4 February 2010 to 18 September 2009
Now that Needle, my work project, is finally no longer secret, I'm starting my slow seditious campaign to subvert the entire Semantic Web establishment. "Entire" is maybe a big word for a small world that not very many people care about, but part of the reason I care is that I think more people would care about the problems this community is addressing if the nature of the problems weren't so obscured by the prevailing ostensible solutions.
I'll be taking this argument on the road, albeit only a couple blocks down it, for a short talk at the Cambridge Semantic Web Meetup Group, next Tuesday night (9 Feb, 6pm) at MIT.
I'll be taking this argument on the road, albeit only a couple blocks down it, for a short talk at the Cambridge Semantic Web Meetup Group, next Tuesday night (9 Feb, 6pm) at MIT.
DERI semantic-web researcher Alexandre Passant just announced a semantic-web-based music-recommendation engine called dbrec. It runs on dbpedia data, and computes "Linked Data Semantic Distance" between bands to find likely suggestions. This is an intriguing premise, and probably a worthy experiment.
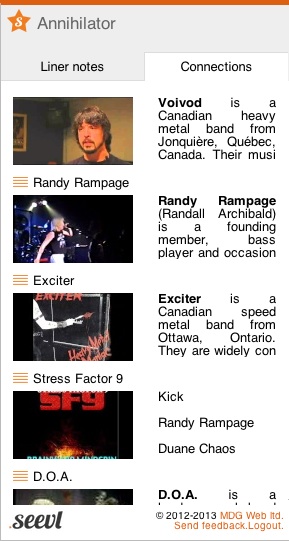
The site isn't labeled "intriguing experiment", though, it's labeled "intelligent music recommendations". Here are its top "intelligent" recommendations for, just to pick a random example near the beginning of the alphabet, Annihilator:
Jeff Waters
Primal Fear
D.O.A.
Extreme
Randy Black
Megadeth
Bif Naked
"Intelligent" is not really the word for this.
On the one hand, the quality of the recommendations is not mostly Passant's fault. The underlying data isn't that great, and you can see how not-great it is in Passant's generated explanations, like this one for how Jeff Waters and Annihilator relate:
This is an incredibly obtuse way of saying, as the human-readable Wikipedia article about Waters puts it in the first sentence: "Jeff Waters is the guitarist and mastermind of the thrash metal band Annihilator". Passant's data doesn't quite record this fact, so he's left to try to make sense of the difference between "associated musical artist", "associated act" and "associated band" and "reference".
Unsurprisingly, not much interesting sense results. Everything in this example is connected primarily through personnel overlap. Drummer Randy Black has played in both Primal Fear and Annihilator, and on one Bif Naked album. D.O.A. founder Randall Archibald sang on two Annihilator albums. Extreme are on the list because drummer Mike Mangini played briefly in both bands. Bif and Annihilator share the hometown "Canada".
These connections aren't irrelevant, exactly. If you were trying to get the phone number of Annihilator's booking agent, they might be worth scanning through in case you spot somebody you went to high school with.
As musical recommendations, though, they suck. As "intelligent" musical recommendations they're idiotic. Annihilator is a thrash-metal band, Extreme were metal-derived MOR pop, Bif Naked is a punk singer. Compare the list, with no claim of "intelligence", for Annihilator on empath:
A person could probably do better than this, too, especially if they're allowed extra adjectives and a lower granularity than artists ("like Kill 'Em All-era Metallica", or "started off like early Slayer, but with more emphasis on technique"; and I don't even know Annihilator very well), but this list is at least not inane.
And yet, Passant's work is almost certainly more technically sophisticated than mine. I used one genre, one data-source and one connection-metric, and produced a deliberately simple web-site with almost no ancillary information. Passant had to confront the sprawl of the Linked Open Data "cloud", figure out non-obvious weightings for a bunch of different connection paths, and display a lot more information than I deal with, in both breadth and depth.
And yet, and yet, and yet: The recommendations are bad. Or, more accurately, the connections are what they are, but calling them recommendations is bad. Calling them "intelligent" is worse, and presenting the combination of "intelligent", "recommendation" and "linked data" to the general public is deadly. If "Linked Data" and "Semantic Web" mean ways for machines to tell me that if I like Annihilator I should listen to Extreme, then nobody needs them. If Linked Data, the movement, can't tell the difference between intelligent and idiotic, it's not to be trusted on anything.
[2013 Postscript]
The site isn't labeled "intriguing experiment", though, it's labeled "intelligent music recommendations". Here are its top "intelligent" recommendations for, just to pick a random example near the beginning of the alphabet, Annihilator:
Jeff Waters
Primal Fear
D.O.A.
Extreme
Randy Black
Megadeth
Bif Naked
"Intelligent" is not really the word for this.
On the one hand, the quality of the recommendations is not mostly Passant's fault. The underlying data isn't that great, and you can see how not-great it is in Passant's generated explanations, like this one for how Jeff Waters and Annihilator relate:
Annihilator (band) is 'associated musical artist' of Jeff Waters (7 artists sharing it)
Annihilator (band) is 'associated acts' of Jeff Waters (7 artists sharing it)
Annihilator (band) is 'associated band' of Jeff Waters (7 artists sharing it)
Jeff Waters is 'current members' of Annihilator (band) (2 artists sharing it)
Annihilator (band) and Jeff Waters share the same value for 'genre'
- Thrash metal (529 artists sharing it)
- Groove metal (101 artists sharing it)
- Speed metal (170 artists sharing it)
- Heavy Metal Music (1534 artists sharing it)
Annihilator (band) and Jeff Waters share the same value for 'reference' (1 artists sharing it)
Annihilator (band) is 'associated acts' of Jeff Waters (7 artists sharing it)
Annihilator (band) is 'associated band' of Jeff Waters (7 artists sharing it)
Jeff Waters is 'current members' of Annihilator (band) (2 artists sharing it)
Annihilator (band) and Jeff Waters share the same value for 'genre'
- Thrash metal (529 artists sharing it)
- Groove metal (101 artists sharing it)
- Speed metal (170 artists sharing it)
- Heavy Metal Music (1534 artists sharing it)
Annihilator (band) and Jeff Waters share the same value for 'reference' (1 artists sharing it)
This is an incredibly obtuse way of saying, as the human-readable Wikipedia article about Waters puts it in the first sentence: "Jeff Waters is the guitarist and mastermind of the thrash metal band Annihilator". Passant's data doesn't quite record this fact, so he's left to try to make sense of the difference between "associated musical artist", "associated act" and "associated band" and "reference".
Unsurprisingly, not much interesting sense results. Everything in this example is connected primarily through personnel overlap. Drummer Randy Black has played in both Primal Fear and Annihilator, and on one Bif Naked album. D.O.A. founder Randall Archibald sang on two Annihilator albums. Extreme are on the list because drummer Mike Mangini played briefly in both bands. Bif and Annihilator share the hometown "Canada".
These connections aren't irrelevant, exactly. If you were trying to get the phone number of Annihilator's booking agent, they might be worth scanning through in case you spot somebody you went to high school with.
As musical recommendations, though, they suck. As "intelligent" musical recommendations they're idiotic. Annihilator is a thrash-metal band, Extreme were metal-derived MOR pop, Bif Naked is a punk singer. Compare the list, with no claim of "intelligence", for Annihilator on empath:
0.228 Anthrax
0.224 Dio
0.206 Sodom
0.182 Saxon
0.176 Black Label Society
0.175 Onslaught (Gbr)
0.170 Grave Digger
0.224 Dio
0.206 Sodom
0.182 Saxon
0.176 Black Label Society
0.175 Onslaught (Gbr)
0.170 Grave Digger
A person could probably do better than this, too, especially if they're allowed extra adjectives and a lower granularity than artists ("like Kill 'Em All-era Metallica", or "started off like early Slayer, but with more emphasis on technique"; and I don't even know Annihilator very well), but this list is at least not inane.
And yet, Passant's work is almost certainly more technically sophisticated than mine. I used one genre, one data-source and one connection-metric, and produced a deliberately simple web-site with almost no ancillary information. Passant had to confront the sprawl of the Linked Open Data "cloud", figure out non-obvious weightings for a bunch of different connection paths, and display a lot more information than I deal with, in both breadth and depth.
And yet, and yet, and yet: The recommendations are bad. Or, more accurately, the connections are what they are, but calling them recommendations is bad. Calling them "intelligent" is worse, and presenting the combination of "intelligent", "recommendation" and "linked data" to the general public is deadly. If "Linked Data" and "Semantic Web" mean ways for machines to tell me that if I like Annihilator I should listen to Extreme, then nobody needs them. If Linked Data, the movement, can't tell the difference between intelligent and idiotic, it's not to be trusted on anything.
[2013 Postscript]
The short version:
Metal
1. Madder Mortem: Eight Ways
2. Secrets of the Moon: Privilegivm
3. Thy Catafalque: Róka Hasa Rádió
4. Antigua y Barbuda: Try Future
5. Funeral Mist: Maranatha
6. Absu: Absu
7. Wardruna: Runaljod - Gap Var Ginnunga
8. Lifelover: Dekadens
9. Amorphis: Skyforger
10. Cantata Sangui: On Rituals and Correspondence in Constructed Realities
Not Metal
1. Manic Street Preachers: Journal for Plague Lovers demos + album + remixes
2. Tori Amos: Midwinter Graces and Abnormally Attracted to Sin
3. Idlewild: Post Electric Blues
4. It Bites: The Tall Ships
5. Bat for Lashes: Two Suns
6. Wheat: White Ink Black Ink
7. Stars of Track and Field: A Time for Lions
8. Tegan & Sara: Sainthood
9. Metric: Fantasies
10. Maxïmo Park: Quicken the Heart
The long version:
TWAS 511: Lay Down (With) Your Armor
The listen-for-yourself versions:
- furia2009metal.zip (21 songs, 2 hours, 110MB)
- furia2009nonmetal.zip (31 songs, 2 hours, 111MB)
Metal
1. Madder Mortem: Eight Ways
2. Secrets of the Moon: Privilegivm
3. Thy Catafalque: Róka Hasa Rádió
4. Antigua y Barbuda: Try Future
5. Funeral Mist: Maranatha
6. Absu: Absu
7. Wardruna: Runaljod - Gap Var Ginnunga
8. Lifelover: Dekadens
9. Amorphis: Skyforger
10. Cantata Sangui: On Rituals and Correspondence in Constructed Realities
Not Metal
1. Manic Street Preachers: Journal for Plague Lovers demos + album + remixes
2. Tori Amos: Midwinter Graces and Abnormally Attracted to Sin
3. Idlewild: Post Electric Blues
4. It Bites: The Tall Ships
5. Bat for Lashes: Two Suns
6. Wheat: White Ink Black Ink
7. Stars of Track and Field: A Time for Lions
8. Tegan & Sara: Sainthood
9. Metric: Fantasies
10. Maxïmo Park: Quicken the Heart
The long version:
TWAS 511: Lay Down (With) Your Armor
The listen-for-yourself versions:
- furia2009metal.zip (21 songs, 2 hours, 110MB)
- furia2009nonmetal.zip (31 songs, 2 hours, 111MB)
After deconstructing the annual Village Voice music poll for many years, this year I actually helped construct it, doing the data-correction and tabulation myself in Needle, the new database system I work on at ITA Software. In conjunction with this, the system itself is finally making its public debut! We are still in private beta for people who want to build data-sets using our tools, but the Voice has allowed us to share the underlying data from the poll as a sample of what data-sets look like in Needle.
I will have, probably, far too much to say about this over time, now that I can actually show people a partial glimpse of what I've been doing for a living for 3+ years. For now, here are the links:
Pazz & Jop 2009 (official results)
Needle - Pazz & Jop 2009 (system intro and data explorer)
All-Idols 2009 (centricity, similarity, kvltosis and other assorted stats)
I will have, probably, far too much to say about this over time, now that I can actually show people a partial glimpse of what I've been doing for a living for 3+ years. For now, here are the links:
Pazz & Jop 2009 (official results)
Needle - Pazz & Jop 2009 (system intro and data explorer)
All-Idols 2009 (centricity, similarity, kvltosis and other assorted stats)
¶ 4 November 2009
Fear is one thing, but voting for hate when love would have cost you nothing is pretty much the quintessence of cowardice. Love will win, and after that, telling the story of standing up for divisiveness and intolerance will be like being proud of having hand-lettered "No Coloreds" signs for water-fountains.
And although the individual people will be forgiven, the institutions should be forfeit. In particular, any church that campaigned against same-sex marriage has violated the social contract that permits religion and rational society to coexist, and should be seized by eminent domain and fumigated for ignorance.
And although the individual people will be forgiven, the institutions should be forfeit. In particular, any church that campaigned against same-sex marriage has violated the social contract that permits religion and rational society to coexist, and should be seized by eminent domain and fumigated for ignorance.
In data-aggregation we are constantly trying to deduplicate references. One dataset says "Olecito", one says "Olecito -- Cambridge", a third says "Olecito Taqueria", and a fourth says "Cielito Taqueria" in the same city as the others, and we'd really like to know whether we have four restaurants, or one, or they're all imaginary or closed or what.
Aligning the variant names is a problem in itself, but it's not the hard one. The hard one is when the concepts themselves don't quite line up. One dataset may be a list of employers, for example, so one "Olecito" is actually a corporate entity with various business properties, including a business address for their accountant's office, and if we show up there wanting a steak quesadilla we will probably (although I don't want to underestimate the guy) be disappointed.
In Linked Data practice (and I'm not currently arguing that you need to know what that is if you don't already), the most common tool for asserting equivalence is a relationship called "owl:sameAs". Out of context this seems like some kind of Star Wars joke by way of Harry Potter: those were not the droids you were looking for, but these are the owls you want. But the "owl:" part is just a bit of pointlessly off-putting data-modeling pedantry in which every single thing you say has to be individually attributed, like saying "These scrambled (in the Epicurious sense) eggs (in the Wikipedia sense) are (in the OED sense) cold (in the Eastern West Virginia State College Department of Thermopedantics and Breakfast sense)."
But never mind, the point of this goofy label is just to say that two different names are actually names for the same thing. Or concept, or even restaurant. The way the function works, officially, it is an absolute statement. It is inherently transitive and symmetric, so if we say that "Olecito", the corporation, is the same owls as "Olecito Taqueria", the excellent take-out restaurant, and "Olecito Taqueria" is a name for the same thing somebody once mistakenly typed as "Cielito Taqueria", then we are saying that anything said about any of those is true of the others. And there we are in the CPA's office-park again, annoying him by demanding Jarritos and a torta.
Practitioner arguments about this issue are obscure even by my standards. (You can see one here, but you've been warned.) Towards the end of that scattered argument, though, it occurred to me what I think the official owls need.
Sometimes we really are trying to say that two different names are wholly interchangeable, particularly when we're cleaning up a single dataset. So having a way to say that is necessary and good.
But across datasets what we usually mean is, in English, something more like "For our current purposes, the thing called X in somebody else's dataset can be taken to provide some missing information about Y in our dataset." This is different from the same-owls thing in two essential ways: it's contextual, not absolute; and even more importantly, it's one-way. We are not saying, or even implying, that our information about Y ought to be inserted into anybody's database as information about X or Z or anything. We are making no claim about whether X and Y are the same existentially, or for any other purpose than this.
The relevant web standards are missing this concept. Maybe oddly, maybe not: RDF and OWL arose out of taxonomy, not data-cleanup. So they have a way to say that one whole class of things are derived from another class of things, and that one relationship is a variation on another relationship; but not that one individual data-concept is a contextual elaboration on another.
Adding it, though, would be trivial, at least logically. It could be called "owl:represents", as in "My owl is elsewhere, so I'll send this note with yours." And in the other direction, if you are the recipient of this representation, the relationship would be "owl:isRepresentedBy". The assertion is neither transitive nor symmetric. What I say about your data is completely separate from what you say about mine, or what you say about anybody else's. I have no business saying whether my data matches yours for your purposes, and no desire to have my statements about my purposes conflated with anything broader. I'm only trying to say what I'm saying. More precisely, I'm trying to say only what I'm saying. We each keep our owls, and you know that I used yours to send a message, but that doesn't make my owl your owl, or my message your message, or anything inane like that.
Surely the owls, at least, would appreciate this.
Aligning the variant names is a problem in itself, but it's not the hard one. The hard one is when the concepts themselves don't quite line up. One dataset may be a list of employers, for example, so one "Olecito" is actually a corporate entity with various business properties, including a business address for their accountant's office, and if we show up there wanting a steak quesadilla we will probably (although I don't want to underestimate the guy) be disappointed.
In Linked Data practice (and I'm not currently arguing that you need to know what that is if you don't already), the most common tool for asserting equivalence is a relationship called "owl:sameAs". Out of context this seems like some kind of Star Wars joke by way of Harry Potter: those were not the droids you were looking for, but these are the owls you want. But the "owl:" part is just a bit of pointlessly off-putting data-modeling pedantry in which every single thing you say has to be individually attributed, like saying "These scrambled (in the Epicurious sense) eggs (in the Wikipedia sense) are (in the OED sense) cold (in the Eastern West Virginia State College Department of Thermopedantics and Breakfast sense)."
But never mind, the point of this goofy label is just to say that two different names are actually names for the same thing. Or concept, or even restaurant. The way the function works, officially, it is an absolute statement. It is inherently transitive and symmetric, so if we say that "Olecito", the corporation, is the same owls as "Olecito Taqueria", the excellent take-out restaurant, and "Olecito Taqueria" is a name for the same thing somebody once mistakenly typed as "Cielito Taqueria", then we are saying that anything said about any of those is true of the others. And there we are in the CPA's office-park again, annoying him by demanding Jarritos and a torta.
Practitioner arguments about this issue are obscure even by my standards. (You can see one here, but you've been warned.) Towards the end of that scattered argument, though, it occurred to me what I think the official owls need.
Sometimes we really are trying to say that two different names are wholly interchangeable, particularly when we're cleaning up a single dataset. So having a way to say that is necessary and good.
But across datasets what we usually mean is, in English, something more like "For our current purposes, the thing called X in somebody else's dataset can be taken to provide some missing information about Y in our dataset." This is different from the same-owls thing in two essential ways: it's contextual, not absolute; and even more importantly, it's one-way. We are not saying, or even implying, that our information about Y ought to be inserted into anybody's database as information about X or Z or anything. We are making no claim about whether X and Y are the same existentially, or for any other purpose than this.
The relevant web standards are missing this concept. Maybe oddly, maybe not: RDF and OWL arose out of taxonomy, not data-cleanup. So they have a way to say that one whole class of things are derived from another class of things, and that one relationship is a variation on another relationship; but not that one individual data-concept is a contextual elaboration on another.
Adding it, though, would be trivial, at least logically. It could be called "owl:represents", as in "My owl is elsewhere, so I'll send this note with yours." And in the other direction, if you are the recipient of this representation, the relationship would be "owl:isRepresentedBy". The assertion is neither transitive nor symmetric. What I say about your data is completely separate from what you say about mine, or what you say about anybody else's. I have no business saying whether my data matches yours for your purposes, and no desire to have my statements about my purposes conflated with anything broader. I'm only trying to say what I'm saying. More precisely, I'm trying to say only what I'm saying. We each keep our owls, and you know that I used yours to send a message, but that doesn't make my owl your owl, or my message your message, or anything inane like that.
Surely the owls, at least, would appreciate this.
¶ Inside a Dataset, Relational Density Is Data's Best Friend. Outside a Dataset, It's Too Dark to Read · 29 September 2009 essay/tech
Stefano Mazzocchi (of Freebase) and David Karger (of MIT) have been holding a slow but interesting conversation about data reconciliation. It's been phrased as a sort of debate between two arbitrarily polarized approaches to the problem of cleaning up data so that you don't have multiple variant references to the same real data-point: either you try to do this cleanup "in the data", so that it's done and you don't have to worry about it any more; or you leave the data alone and figure you'll incorporate the cleanup into your query process when you actually start asking specific questions.
But I think this is less of a debate than Stefano and (particularly) David are making it seem. Or, rather, that the real polarization is along a slightly different axis. The biggest difference between Stefano's world and David's happens before you even start to worry about when you're going to start worrying about data cleanup: Freebase is attempting to build a single huge structured-data-representation of (eventually) all knowledge; David's work is largely about building lots of little structured-data-representations of individual (relatively) small blobs of knowledge.
Within a dataset, though, Stefano and David (and I) are in enthusiastic agreement: internal consistency is what makes data meaningful. If your data doesn't know whether "Beatles" and "The Beatles" are one band or two different ones, your answers to any question that touches either one are liable to be so pathetically wrong that people will very quickly stop asking you things. In the classic progression from Data to Information to Knowledge to Wisdom, this is what that first step means: Data is isolated, Information is consolidated. It would be inane to be against this. (Unless, I guess, you were also against Knowledge and Wisdom.)
It's on the definition of "within", though, that most of the interesting issues under the heading of "the Semantic Web" wobble. David says "I argued in favor of letting individuals make their own [datasets] ... and worry about merging them with other people’s data later." He really does mean individuals, and the MIT-developed tool he has in mind (Exhibit) is designed (and only suited) for fairly small datasets. Freebase is officially a database of everything, but of course within this everything are lots of subsets, and Stefano is really talking more about cleaning up these subsets than the whole universe. Reconciling all the artist references to "Beatles" and "The Beatles" from albums and songs is a straightforward practical task both beneficial and probably necessary for asking questions of a song/album/artist dataset, whether it's embedded in a larger one or not. Reconciling the "'The Beatles" who are the artist of the song "Day Tripper" with "The Beatles" who are depicted in cartoon form on a particular vintage lunchbox for sale on eBay, on the other hand, is less conceptually straightforward, and of more obscure practical import.
The thing I'm working on at ITA falls in between Exhibit and Freebase on this dataset axis, both in capacity and design. We handle datasets much bigger than you could put in Exhibit, and allow you to explore and analyze them in ways that Exhibit cannot; but we separate datasets, partly for scalability but even more importantly to specifically keep out of any unnecessary quagmire of trying to reconcile not just the bits of data but the structures.
And my own scouting report, from having done a lot of data-reconciliation in a system designed for it, and in other lives of a lot of more-painful data-reconciliation in various systems not really designed for it, is the same as Stefano's report from his experiences at Freebase: getting from data to information, at scale, is hard. It's mainly hard in ways that machines cannot just solve for you, and anybody who thinks RDF is a solution to data-reconciliation is, as Stefano puts it, confusing model mixability with semantic reconciliation, and has probably not noticed because they've only been playing with toy datasets, which is like thinking you're learning Architecture by building a few birdhouses.
And this is all exactly why I have repeatedly argued for treating the "Semantic Web" technology problem as a database-tech problem first, and a web-tech problem only secondarily. David complains, justifiably, about the pain of combining two small, simple folk-dance datasets he himself cares about. But just as Stefano says in another example, the syntax problems here (e.g. text in a YouTube description box, rather than formally-labeled data records) are fairly trivial compared to the modeling differences. All the URIs and XSL transformations in the world are not going to allow every two datasets to magically operate as one. Some person, without or without tools to magnify their effort, is going to have to rephrase one dataset in the argot of the other.
And to say another thing I've said before again, the fact that RDF doesn't itself solve these problems is not its terminal design flaw. Its terrible flaw is that it isn't even a sufficient foundation upon which to build the tools that would help solve these problems. It takes the right fundamental idea, that the most basic conceptual structure of data is things and the relationships between them, but then becomes so invertedly obsessed with the theoretical purity of this reduction that it leaves a whole layer of needed practical elaboration unbuilt. We shouldn't need abstruse design patterns to get ordered lists, or rickety reasoning engines just to get relationships that go both directions, or endless syntax officiousness that gets us expensive precision with no gain in accuracy.
This effort has let us down. And worse, it has constrained smart people so that their earnest efforts cannot help but let us down. After years and years of waiting, we have no Semantic Web of information, we have only Linked Data, where the word "Linked" is so tenuously justified it might as well be replaced with some pink-ink-drinking Seuss pet, and the word "Data" is tragically all too accurate. We have all these computers, living abbreviated lives of quiet depreciation, filled with the data that should become our wisdom, and yearning, if they are allowed to yearn for even one thing, to be able to tell us what they know.
But I think this is less of a debate than Stefano and (particularly) David are making it seem. Or, rather, that the real polarization is along a slightly different axis. The biggest difference between Stefano's world and David's happens before you even start to worry about when you're going to start worrying about data cleanup: Freebase is attempting to build a single huge structured-data-representation of (eventually) all knowledge; David's work is largely about building lots of little structured-data-representations of individual (relatively) small blobs of knowledge.
Within a dataset, though, Stefano and David (and I) are in enthusiastic agreement: internal consistency is what makes data meaningful. If your data doesn't know whether "Beatles" and "The Beatles" are one band or two different ones, your answers to any question that touches either one are liable to be so pathetically wrong that people will very quickly stop asking you things. In the classic progression from Data to Information to Knowledge to Wisdom, this is what that first step means: Data is isolated, Information is consolidated. It would be inane to be against this. (Unless, I guess, you were also against Knowledge and Wisdom.)
It's on the definition of "within", though, that most of the interesting issues under the heading of "the Semantic Web" wobble. David says "I argued in favor of letting individuals make their own [datasets] ... and worry about merging them with other people’s data later." He really does mean individuals, and the MIT-developed tool he has in mind (Exhibit) is designed (and only suited) for fairly small datasets. Freebase is officially a database of everything, but of course within this everything are lots of subsets, and Stefano is really talking more about cleaning up these subsets than the whole universe. Reconciling all the artist references to "Beatles" and "The Beatles" from albums and songs is a straightforward practical task both beneficial and probably necessary for asking questions of a song/album/artist dataset, whether it's embedded in a larger one or not. Reconciling the "'The Beatles" who are the artist of the song "Day Tripper" with "The Beatles" who are depicted in cartoon form on a particular vintage lunchbox for sale on eBay, on the other hand, is less conceptually straightforward, and of more obscure practical import.
The thing I'm working on at ITA falls in between Exhibit and Freebase on this dataset axis, both in capacity and design. We handle datasets much bigger than you could put in Exhibit, and allow you to explore and analyze them in ways that Exhibit cannot; but we separate datasets, partly for scalability but even more importantly to specifically keep out of any unnecessary quagmire of trying to reconcile not just the bits of data but the structures.
And my own scouting report, from having done a lot of data-reconciliation in a system designed for it, and in other lives of a lot of more-painful data-reconciliation in various systems not really designed for it, is the same as Stefano's report from his experiences at Freebase: getting from data to information, at scale, is hard. It's mainly hard in ways that machines cannot just solve for you, and anybody who thinks RDF is a solution to data-reconciliation is, as Stefano puts it, confusing model mixability with semantic reconciliation, and has probably not noticed because they've only been playing with toy datasets, which is like thinking you're learning Architecture by building a few birdhouses.
And this is all exactly why I have repeatedly argued for treating the "Semantic Web" technology problem as a database-tech problem first, and a web-tech problem only secondarily. David complains, justifiably, about the pain of combining two small, simple folk-dance datasets he himself cares about. But just as Stefano says in another example, the syntax problems here (e.g. text in a YouTube description box, rather than formally-labeled data records) are fairly trivial compared to the modeling differences. All the URIs and XSL transformations in the world are not going to allow every two datasets to magically operate as one. Some person, without or without tools to magnify their effort, is going to have to rephrase one dataset in the argot of the other.
And to say another thing I've said before again, the fact that RDF doesn't itself solve these problems is not its terminal design flaw. Its terrible flaw is that it isn't even a sufficient foundation upon which to build the tools that would help solve these problems. It takes the right fundamental idea, that the most basic conceptual structure of data is things and the relationships between them, but then becomes so invertedly obsessed with the theoretical purity of this reduction that it leaves a whole layer of needed practical elaboration unbuilt. We shouldn't need abstruse design patterns to get ordered lists, or rickety reasoning engines just to get relationships that go both directions, or endless syntax officiousness that gets us expensive precision with no gain in accuracy.
This effort has let us down. And worse, it has constrained smart people so that their earnest efforts cannot help but let us down. After years and years of waiting, we have no Semantic Web of information, we have only Linked Data, where the word "Linked" is so tenuously justified it might as well be replaced with some pink-ink-drinking Seuss pet, and the word "Data" is tragically all too accurate. We have all these computers, living abbreviated lives of quiet depreciation, filled with the data that should become our wisdom, and yearning, if they are allowed to yearn for even one thing, to be able to tell us what they know.








{kind=link}
¶ (How) We Can Work It Out · 23 September 2009 essay/tech
[Fair warning: This is another post about data-modeling and query languages, and it isn't likely to be the last. It may or may not be interesting to people with personal interests in those topics, but I think it's pretty unlikely to be interesting to people without those interests. You have been warned.]
In data-modeling you usually live in fear of the word "usually". Accounting for the subsequent "but sometimes" is usually where a simple, manageable data-model starts its ugly metamorphosis towards tangled and unusable. Same with "mostly", "more often", "occasionally". Most data-modeling contexts are only really ever happy with "always" and "never"; and the real world is usually not so helpfully binary.
DiscO, my data-model for discographies, notes that Tracks, Releases and Sequences can all have Artists, but that usually Tracks would get their Artist indirectly from their Release, which would in turn get it from its Sequence.
What this means, in practical terms, is that when we're entering or importing data, we don't necessarily want to have to set Artist individually on every single Sequence, Release and Track. But when we're querying the data, we want to be able to ask about Artist on every one of those.
Data-modeling people call this "inference", and it's a whole academic subject of its own, deeply entangled with abstract logic and belief-system consistency. The Sequence/Release/Track problem sounds theoretically straightforward at first, but gets very hard very quickly once you realize that some Releases are compilations of Tracks by multiple artists, and some Sequences have Releases by multiple artists. Thus it's not quite true that Sequence "contains" Release, and upon that "not quite" most academic approaches will founder and demand to be released from this vagueness via a rococo expansion of the domain model to separate the notions of Single-Artist and Multiple-Artist Sequences and Releases.
But "usually" is a good concept. And for lots of real-world data problems it can be handled without flailing into existential abstraction. We can keep our model simple, and fill in the implied data with a very general mechanism: the relationships between "actual" values and "effective" values can themselves be described in queries.
Releases, we said, may have Artists directly, or may get them implicitly from their Sequence. More specifically, we probably mean something like this:
- If a Release has an Artist, directly, use that.
- If it doesn't, get all the Sequences in which it occurs.
- Ignore any Sequence that itself has no Artist or multiple Artists.
- If all the remaining (single-Artist) Sequences have the same Artist, use that.
- Otherwise we don't know.
This can be written out in Thread in pretty much these exact steps:
This isn't a syntax tutorial, but ";" means otherwise, and "::#=1" tests a list to see if it has exactly one entry, so maybe you can sort of see what the query is doing.
A Track, then, follows the same pattern, but has to check one more level:
- If a Track has an Artist, directly, use that.
- If it doesn't, get all the Releases in which it occurs.
- Ignore any Release that itself has no Artist or multiple Artists.
- If all the remaining (single-Artist) Releases have the same Artist, use that.
- Otherwise, get all the Sequences for all the Releases on which the track appears.
- Ignore any Sequence that itself has no Artist or multiple Artists.
- If all the remaining (single-Artist) Sequences have the same Artist, use that.
- Otherwise we don't know.
Or, in Thread:
In this system, once you've learned the query-language (and I'm not saying this is a trivial task, but it's not that hard), you can do most anything. The language with which you ask questions is the same language you use for stipulating answers.
Query-language-geek postscript: And, of course, it's the same language you use for obsessively fiddling with your questions and answers because you just can't help it. That Track query has some redundancy, and while redundancy isn't always bad, it's almost always fun to see if you can get rid of it. In this case we're asking the same question ("What's your artist?") in all three steps of the query. We can rearrange it so that we get all the Tracks and Releases and Sequences first, then ask all the Artist questions at the end:
"...__," may initially look a little like ants playing Limbo, but "...__,Release,Sequence" means "get these things, their Releases and their Sequences, and then add those things' Releases and Sequences, etc. until you get to the end. So this version of the query builds up the complete list of all the places from which this Track could derive its artist, keeps only the ones that have a single artist, and then sees if we're left with a single artist at the end of the whole process. Depending on what we want to do if our data has internal contradictions, this might actually be functionally better than the first version, not just shorter to type.
But DiscO also has all that stuff about Original Versions, and it would be nice if our Artist inference used that information, too. If Past Masters [Remastered] is an alternate version of Past Masters, Vol. 1 & 2, and Past Masters, Vol. 1 & 2 belongs to the Beatles' Compilations sequence, then we should be able to deduce that the version of "We Can Work It Out" on Past Masters [Remastered] is by the Beatles. Our experimental elimination of redundancy now pays off a little bit, because we only have to add in "Original Version" in one place:
And interestingly, since both Tracks and Releases can have Original Versions, this whole thing actually works for either type, and thus we can combine the two and have even fewer things to worry about:
Having fewer things to worry about is (usually) good.
In data-modeling you usually live in fear of the word "usually". Accounting for the subsequent "but sometimes" is usually where a simple, manageable data-model starts its ugly metamorphosis towards tangled and unusable. Same with "mostly", "more often", "occasionally". Most data-modeling contexts are only really ever happy with "always" and "never"; and the real world is usually not so helpfully binary.
DiscO, my data-model for discographies, notes that Tracks, Releases and Sequences can all have Artists, but that usually Tracks would get their Artist indirectly from their Release, which would in turn get it from its Sequence.
What this means, in practical terms, is that when we're entering or importing data, we don't necessarily want to have to set Artist individually on every single Sequence, Release and Track. But when we're querying the data, we want to be able to ask about Artist on every one of those.
Data-modeling people call this "inference", and it's a whole academic subject of its own, deeply entangled with abstract logic and belief-system consistency. The Sequence/Release/Track problem sounds theoretically straightforward at first, but gets very hard very quickly once you realize that some Releases are compilations of Tracks by multiple artists, and some Sequences have Releases by multiple artists. Thus it's not quite true that Sequence "contains" Release, and upon that "not quite" most academic approaches will founder and demand to be released from this vagueness via a rococo expansion of the domain model to separate the notions of Single-Artist and Multiple-Artist Sequences and Releases.
But "usually" is a good concept. And for lots of real-world data problems it can be handled without flailing into existential abstraction. We can keep our model simple, and fill in the implied data with a very general mechanism: the relationships between "actual" values and "effective" values can themselves be described in queries.
Releases, we said, may have Artists directly, or may get them implicitly from their Sequence. More specifically, we probably mean something like this:
- If a Release has an Artist, directly, use that.
- If it doesn't, get all the Sequences in which it occurs.
- Ignore any Sequence that itself has no Artist or multiple Artists.
- If all the remaining (single-Artist) Sequences have the same Artist, use that.
- Otherwise we don't know.
This can be written out in Thread in pretty much these exact steps:
Release|Artist=(.Artist;(.Sequence:(.Artist::#=1).Artist::#=1))
This isn't a syntax tutorial, but ";" means otherwise, and "::#=1" tests a list to see if it has exactly one entry, so maybe you can sort of see what the query is doing.
A Track, then, follows the same pattern, but has to check one more level:
- If a Track has an Artist, directly, use that.
- If it doesn't, get all the Releases in which it occurs.
- Ignore any Release that itself has no Artist or multiple Artists.
- If all the remaining (single-Artist) Releases have the same Artist, use that.
- Otherwise, get all the Sequences for all the Releases on which the track appears.
- Ignore any Sequence that itself has no Artist or multiple Artists.
- If all the remaining (single-Artist) Sequences have the same Artist, use that.
- Otherwise we don't know.
Or, in Thread:
Track|Artist=(
.Artist;
.(.Release:(.Artist::#=1).Artist::#=1);
.(.Release.Sequence:(.Artist::#=1).Artist::#=1))
.Artist;
.(.Release:(.Artist::#=1).Artist::#=1);
.(.Release.Sequence:(.Artist::#=1).Artist::#=1))
In this system, once you've learned the query-language (and I'm not saying this is a trivial task, but it's not that hard), you can do most anything. The language with which you ask questions is the same language you use for stipulating answers.
Query-language-geek postscript: And, of course, it's the same language you use for obsessively fiddling with your questions and answers because you just can't help it. That Track query has some redundancy, and while redundancy isn't always bad, it's almost always fun to see if you can get rid of it. In this case we're asking the same question ("What's your artist?") in all three steps of the query. We can rearrange it so that we get all the Tracks and Releases and Sequences first, then ask all the Artist questions at the end:
Track|Artist=(...__,Release,Sequence:(.Artist::#=1).Artist::#=1)
"...__," may initially look a little like ants playing Limbo, but "...__,Release,Sequence" means "get these things, their Releases and their Sequences, and then add those things' Releases and Sequences, etc. until you get to the end. So this version of the query builds up the complete list of all the places from which this Track could derive its artist, keeps only the ones that have a single artist, and then sees if we're left with a single artist at the end of the whole process. Depending on what we want to do if our data has internal contradictions, this might actually be functionally better than the first version, not just shorter to type.
But DiscO also has all that stuff about Original Versions, and it would be nice if our Artist inference used that information, too. If Past Masters [Remastered] is an alternate version of Past Masters, Vol. 1 & 2, and Past Masters, Vol. 1 & 2 belongs to the Beatles' Compilations sequence, then we should be able to deduce that the version of "We Can Work It Out" on Past Masters [Remastered] is by the Beatles. Our experimental elimination of redundancy now pays off a little bit, because we only have to add in "Original Version" in one place:
Track|Artist=(...__,Release,Sequence,Original Version:(.Artist::#=1).Artist::#=1)
And interestingly, since both Tracks and Releases can have Original Versions, this whole thing actually works for either type, and thus we can combine the two and have even fewer things to worry about:
Track,Release|Artist=(...__,Release,Sequence,Original Version:(.Artist::#=1).Artist::#=1)
Having fewer things to worry about is (usually) good.
¶ Data Tripping (and DiscO) · 18 September 2009 essay/tech
What Beatles album is "Day Tripper" on?
This is partially a trick question, of course, as "Day Tripper" was originally a non-album single, but it has been on several Beatles compilations over the years, including the red 1962-1966 best-of, and in the remastered 2009 catalog it lands on both the mono and stereo versions of Past Masters.
Starting from scratch, it would take you, as a person, a little while to figure this answer out on the web. There's a Wikipedia page for the song, which is the top search hit for the above question in both Google and Bing, and it explains the non-album-ness and mentions several compilations, but it doesn't (at least as of this moment) clarify current availability, and none of the pages for the non-current compilations refer you explicitly (again, as of this moment) to the right place.
There are a few paths that lead you to a voluminous page for the Beatles discography, on which "Day Tripper" is again mentioned several times, but this page doesn't itemize the track-listings of compilations, and the "Day Tripper" links just go back to the original song-page. But eventually you might blunder into the separate pages for the Mono and Stereo box sets, and from there you might wander over to Amazon.
Here even more potential confusion awaits you. The top Google hit for "amazon past masters", at the moment, is the now-obsolete second volume of the old CD edition. Searching on "past masters" on Amazon itself gets you the Remastered edition as the top hit, but idiotically suggests buying it together with the old Volume 2, and you would have to scrutinize the track lists to realize that Past Masters [Remastered] subsumes Past Masters, Vol. 1 and Past Masters, Vol. 2.
In fact, if you backtrack and try searching for "Day Tripper" on Amazon, the top hit is Rubber Soul, the album on which "Day Tripper" would have appeared, chronologically, but doesn't. And, for good measure, that top hit is the obsolete 1990 CD, not the new remaster.
Bleh.
But at least you're a person, and via a judicious combination of intuition and stubbornness and asking some friends who might know, you can eventually solve these information problems. If you were a computer, you'd be fucked.
Which is OK on some existential level, because if you were a computer you probably wouldn't appreciate the song, anyway. But the point of computers is to help people do things, and a computer ought to be a particularly helpful tool when the thing you need to do is sort through some data.
But for the computer to help you puzzle through this data, the data has to be modeled usefully by people first. There are several prominent sources of meticulously structured data about music, so this should be easy. But here, sadly, people have let us down again. And again, and again. Let's see how.
All Music Guide
A text-search for "Day Tripper" (there's no other query interface) returns a full page of cryptic results. There's an "Occurrences" column, and although it's not clear exactly what that means, it's obvious that more is supposed to be better, and the first listing has 360 where none of the rest have more than 13, so presumably that's the "right" one.
Clicking this gets you 8 pages of results, which is annoying in itself (the splitting of them into pages, I mean). They're sorted by Artist, which sounds reasonable enough, except that the ones without artists are sorted first, and thus the first page of results is almost totally crap. There are lots of Beatles releases listed, but they get split between pages 1 and 2 of the results list, making it impossible to look at them all at once.
But if you drill into one of them at random, and then click on "Day Tripper" in the track listing, you do finally get to a page that lists all (or several, anyway) Beatles releases on which this song appears. There are 24, though, including such things as "Five Nights in a Judo Arena", which human intuition might guess is not a normative release, but a computer would have no basis for dismissing. These releases are in date-order, at least, but this turns out to be worse than worthless for our current question, because All Music has modeled Past Masters [Remastered] not as an album, but as an alternate manifestation of the album Past Masters, Vol. 1 & 2, which means it appears way up in the middle of this list, labeled 1988, because that was the year of its earliest issue (on cassette!).
Looking through the data, in fact, we see that although All Music has lots of individual detail on most kinds of things, it has essentially nothing that models the relationships of things to each other, or in groups. There is no modeled connection between Past Masters, Vol. 1 & 2, Past Masters, Vol. 2, The Beatles: Mono Box Set and The Beatles: Stereo Box Set, even though v1/2 subsumes v2, and both boxes subsume both.
And there's no modeling of "in print", or any notion of representing the subset of albums that represent the current core catalog. So a computer can't use this data to answer real questions by itself. Source fail.
MusicBrainz
This is a database first, not a guide, and thus a more likely candidate for well-structured data anyway, and one where I won't pick at their explicitly-secondary browsing UI.
The good news is that MusicBrainz has the kind of data we need. They have some relationships between tracks, like one being a mashup of some others, so presumably they could add one to express that the Mono Masters of "Day Tripper" is a different version from the Past Masters [Remastered] one, but the same underlying song. They already have a reconciliation mechanism by which they can say that the "Day Tripper" on 1962-1966 is "the same" as the one on Past Masters, although at the moment the reconciliation data looks too noisy for real use.
They even have the notion of one release being part of a set, although I didn't find very many examples of sets, and in particular I can't tell if a release can be part of more than one set. But if they can, that might be a mechanism for expressing official catalogs, current availability, and various other kinds of groupings and subsets.
So current source fail, but at least there's hope here.
Freebase
Freebase is easily the most sophisticated public attempt at universal data-modeling, at the moment, but this is a caveat as well as a compliment. Freebase models attempt to represent everything that could possibly exist, and thus tend to drift quickly from usable simplicity towards abstractly-correct awkwardness, usually coming to rest far into the latter.
So if you search on "Day Tripper", you will find that there are results of that name as "Topic", "Composition", "Musical Album" and "Musical Track", with at least dozens of the latter. Freebase fails the usability test even more spectacularly than All Music, as the list of Musical Tracks is presented with no grouping or distinguishing information at all, just "Day Tripper (Musical Track)" after "Day Tripper (Musical Track)", and you have to click on each one to get any clarifying info. "Day Tripper" the composition does not link to any of the tracks, and "Day Tripper" the album turns out to be a compilation of Beatles covers which does not, at least as far as the listed information shows, even contain the song "Day Tripper".
And if you delve into the internals of the Freebase music schema, you can quickly develop a guess about why the data has not all been filled in: there's too damn much structure. A music/track is a recording of a music/composition. The track can appear on multiple music/releases, each of which is a publication of a particular music/album. Unless you need to model who was in the band during the making of an album, in which case the album links instead to a set of music/recording_contributions, which is each a combination of albums, contributors and roles.
Oh, except compositions can be recorded "as albums", in which case they link to music/album without going through music/track, and tracks can appear directly on releases without going through music/album. And there's no current property for saying that a given track is an alternate version of another, but from following Freebase modeling discussions I can confidently guess that they'd model that by saying that a music/track links to something like a music/track_derivation, which itself is a combination of original track, derivative track, deriving artist (or music/track_derivation_contribution) and derivation type. And Freebase's query-language doesn't provide any recursion, so if these relationships chain, good luck querying them.
Music Ontology
This isn't a database, just an attempt at a model for one. And, grimly, it's another quantum level more elaborately and unusably correct than the Freebase model. Even "MO Basics" (and the "Overview" has 22 more tables of explication beyond these "Basics", without getting into the "details") includes conceptual distinctions between Composition, Arrangement, Recording, Musical Work, Musical Item, MusicalExpression and MusicalManifestation. And then there are pages upon pages of minutely itemized trivia like beginsAtDuration, djmix_of, paid_download (and "paiddownload", which is different in some way I couldn't figure out), AnalogSignal, isFactorOf... This list is bad because it's too long, but the fact that it's in the schema means that it's also bad because no matter how long it is, it will never include every nuance you ever find yourself wanting, and thus over time it will only accumulate more debris.
A tour-de-force into a cul-de-sac.
The Rest of the Web
Searching on any particular band or bit of music will unearth dozens or hundreds of other sites that contain bits of the information we need: stores, discographies, databases, forums, fan pages, official sites. Almost universally, these are either unqueriable flat HTML pages, or tree-structured databases with even less interlinking than the above sites. Encyclopaedia Metallum, my favorite metal site, has full track listings for a genuinely mind-boggling number of releases by an astonishing number of bands, but the tracks themselves are not data-objects and a machine can find out nothing about them. There are several lovingly hand-crafted Beatles discographies on the web, all far too detailed for our original casual query, and all essentially useless to a computer attempting to help us.
So: Ugh. Triple ugh because a) the population of people willing to put time and energy into filling out music-related data-forms is obviously huge, b) the modeling problems are not intractably complicated in any theoretical sense, c) MusicBrainz and Freebase, at least (and the system I'm designing at work, I think), seem to be technically sufficient to represented the data correctly. If only we had a better plan.
DiscO
So here's my attempt at a better plan. I call it DiscO, for Discographic Ontology; that is, it's a scheme for structuring discographies. It is not an attempt at an abstract physics of human air-vibrating creativity, it is just an outline of a way to write down the information about bands, the music they've made, and how that music was released. It's intended to be simple enough that you can imagine people actually filling in the data, but expressive enough that the data can support interesting queries. And it's specifically intended to model nuance abstractly, so that it can accommodate some kinds of new needs without perpetually having to itself expand.
There are four basic types:
Artist - The Beatles, Big Country, Megadeth, Frank Zappa, whatever...
Release - an individual album, single, compilation, whatever; Rubber Soul, Past Masters [Remastered], "Day Tripper"/"We Can Work It Out"...
Track - an individual version of a song; "Day Tripper", "Day Tripper [mono]", "Day Tripper (performed live on pan flute and triangle by Zamfir and Elmo)", etc.
Sequence - any collection of releases; Original Albums, Japanese Cassette Singles, 2009 Remasters, etc.
These are related to each other like this:
Artists mostly have Sequences. Sequences can be anything, but many artists would have some standard ones: Original Albums, Singles, Compilations, Remastered Albums, Current Catalog.
Sequences have Releases (and Artists).
Releases have Dates, Labels and Tracks. A Release may have an Artist directly, but more often would have one indirectly via a Sequence.
Releases may be related to each other via Alternate Version/Original Version links. Thus Past Masters, Vol. 1 & 2 and Past Masters [Remastered] are both Releases, but Past Masters [Remastered] has an Original Version link to Past Masters, Vol. 1 & 2, and Past Masters, Vol. 1 & 2 has an Alternate Version link to Past Masters [Remastered].
Tracks have Durations. A Track may have an Artist directly (so individual tracks on multi-artist compilations can be attributed correctly), but more often would have one indirectly via Release (which itself may have one indirectly via Sequence).
Tracks may also be related to each other via Alternate Version/Original Version links. "Day Tripper" and "Day Tripper [mono]" are both Tracks, but "Day Tripper" has an Alternate Version link to "Day Tripper [mono]", and "Day Tripper [mono]" has an Original Version link to "Day Tripper". (We can get into geek arguments about which versions are the same and which are derivations (of which!), if we want, but whatever we decide, we can model.)
Restated in schema-ish form, that's:
Artist
- Sequence
- Release
- Track
Sequence
- Artist
- Release
Release
- Sequence
- Artist
- Date
- Label
- Track
- Original Version
- Alternate Version
Track
- Artist
- Duration
- Original Version
- Alternate Version
I think that's basically enough. What it gives up in expressiveness, it gains in usability. Our Beatles data can now, I think, be modeled both tractably and informatively. We can hook up all the versions of albums and versions of songs. We can create whatever sequences we need, and since the sequences themselves are just data, it's fine to have "Canadian Singles" for the Beatles and "Fanzine Flexis" for The Bedsitters without implying that either band should also have the other.
And using Thread, the query-language I will (before long, hopefully) be attempting to spread through the universe, we can start to ask our questions in a way the computer can answer:
This is our naive query. It gets all the releases that have any track called exactly "Day Tripper". Good for assuring us there's some data in the bucket, but not much help in answering our question.
That limits our results to albums by the Beatles, but there are still too many. With our fully-interlinked data-model, though, we can now actually ask something that is much closer to what we mean:
That is, find the artist The Beatles, get their Current Catalog sequence, get that sequence's releases, and filter those releases down to the ones that contain a track called exactly "Day Tripper". This is progress.
But "called exactly 'Day Tripper'" will exclude "Day Tripper [mono]", which isn't what we want to do. We're trying to ask a musical question about a song, not a typographical question about a title. But this, too, we have the powers to cope with:
This time we first define a new inferred relationship on Track called "Day Trippers", which gets the Track, all its Original Versions, all their Original Versions (recursively), and then filters this set of tracks down to just the ones called "Day Tripper".
Then we get the Beatles' current catalog releases again, but this time instead of checking each release for a track named "Day Tripper", we use our Day Trippers relationship to check for a track that is, or is derived from, "Day Tripper". And then, for each of the releases that have one, we infer two new relationships: "DT Versions" tells us which track(s) on this release are versions of "Day Tripper", and "Other Tracks" counts the tracks on this release that are not derivations of "Day Tripper".
I.e.:
So now we know our choices. It took us so long to find out, but we found out.
Tantalizing Postscript: But now that we have these three options before us, how do their contents overlap or differ, track by track?! We could bring up three different windows and squint at them. Or we could ask the computer:
Aaah. I see now. (How nice it will be when I'm allowed to show you...)
This is partially a trick question, of course, as "Day Tripper" was originally a non-album single, but it has been on several Beatles compilations over the years, including the red 1962-1966 best-of, and in the remastered 2009 catalog it lands on both the mono and stereo versions of Past Masters.
Starting from scratch, it would take you, as a person, a little while to figure this answer out on the web. There's a Wikipedia page for the song, which is the top search hit for the above question in both Google and Bing, and it explains the non-album-ness and mentions several compilations, but it doesn't (at least as of this moment) clarify current availability, and none of the pages for the non-current compilations refer you explicitly (again, as of this moment) to the right place.
There are a few paths that lead you to a voluminous page for the Beatles discography, on which "Day Tripper" is again mentioned several times, but this page doesn't itemize the track-listings of compilations, and the "Day Tripper" links just go back to the original song-page. But eventually you might blunder into the separate pages for the Mono and Stereo box sets, and from there you might wander over to Amazon.
Here even more potential confusion awaits you. The top Google hit for "amazon past masters", at the moment, is the now-obsolete second volume of the old CD edition. Searching on "past masters" on Amazon itself gets you the Remastered edition as the top hit, but idiotically suggests buying it together with the old Volume 2, and you would have to scrutinize the track lists to realize that Past Masters [Remastered] subsumes Past Masters, Vol. 1 and Past Masters, Vol. 2.
In fact, if you backtrack and try searching for "Day Tripper" on Amazon, the top hit is Rubber Soul, the album on which "Day Tripper" would have appeared, chronologically, but doesn't. And, for good measure, that top hit is the obsolete 1990 CD, not the new remaster.
Bleh.
But at least you're a person, and via a judicious combination of intuition and stubbornness and asking some friends who might know, you can eventually solve these information problems. If you were a computer, you'd be fucked.
Which is OK on some existential level, because if you were a computer you probably wouldn't appreciate the song, anyway. But the point of computers is to help people do things, and a computer ought to be a particularly helpful tool when the thing you need to do is sort through some data.
But for the computer to help you puzzle through this data, the data has to be modeled usefully by people first. There are several prominent sources of meticulously structured data about music, so this should be easy. But here, sadly, people have let us down again. And again, and again. Let's see how.
All Music Guide
A text-search for "Day Tripper" (there's no other query interface) returns a full page of cryptic results. There's an "Occurrences" column, and although it's not clear exactly what that means, it's obvious that more is supposed to be better, and the first listing has 360 where none of the rest have more than 13, so presumably that's the "right" one.
Clicking this gets you 8 pages of results, which is annoying in itself (the splitting of them into pages, I mean). They're sorted by Artist, which sounds reasonable enough, except that the ones without artists are sorted first, and thus the first page of results is almost totally crap. There are lots of Beatles releases listed, but they get split between pages 1 and 2 of the results list, making it impossible to look at them all at once.
But if you drill into one of them at random, and then click on "Day Tripper" in the track listing, you do finally get to a page that lists all (or several, anyway) Beatles releases on which this song appears. There are 24, though, including such things as "Five Nights in a Judo Arena", which human intuition might guess is not a normative release, but a computer would have no basis for dismissing. These releases are in date-order, at least, but this turns out to be worse than worthless for our current question, because All Music has modeled Past Masters [Remastered] not as an album, but as an alternate manifestation of the album Past Masters, Vol. 1 & 2, which means it appears way up in the middle of this list, labeled 1988, because that was the year of its earliest issue (on cassette!).
Looking through the data, in fact, we see that although All Music has lots of individual detail on most kinds of things, it has essentially nothing that models the relationships of things to each other, or in groups. There is no modeled connection between Past Masters, Vol. 1 & 2, Past Masters, Vol. 2, The Beatles: Mono Box Set and The Beatles: Stereo Box Set, even though v1/2 subsumes v2, and both boxes subsume both.
And there's no modeling of "in print", or any notion of representing the subset of albums that represent the current core catalog. So a computer can't use this data to answer real questions by itself. Source fail.
MusicBrainz
This is a database first, not a guide, and thus a more likely candidate for well-structured data anyway, and one where I won't pick at their explicitly-secondary browsing UI.
The good news is that MusicBrainz has the kind of data we need. They have some relationships between tracks, like one being a mashup of some others, so presumably they could add one to express that the Mono Masters of "Day Tripper" is a different version from the Past Masters [Remastered] one, but the same underlying song. They already have a reconciliation mechanism by which they can say that the "Day Tripper" on 1962-1966 is "the same" as the one on Past Masters, although at the moment the reconciliation data looks too noisy for real use.
They even have the notion of one release being part of a set, although I didn't find very many examples of sets, and in particular I can't tell if a release can be part of more than one set. But if they can, that might be a mechanism for expressing official catalogs, current availability, and various other kinds of groupings and subsets.
So current source fail, but at least there's hope here.
Freebase
Freebase is easily the most sophisticated public attempt at universal data-modeling, at the moment, but this is a caveat as well as a compliment. Freebase models attempt to represent everything that could possibly exist, and thus tend to drift quickly from usable simplicity towards abstractly-correct awkwardness, usually coming to rest far into the latter.
So if you search on "Day Tripper", you will find that there are results of that name as "Topic", "Composition", "Musical Album" and "Musical Track", with at least dozens of the latter. Freebase fails the usability test even more spectacularly than All Music, as the list of Musical Tracks is presented with no grouping or distinguishing information at all, just "Day Tripper (Musical Track)" after "Day Tripper (Musical Track)", and you have to click on each one to get any clarifying info. "Day Tripper" the composition does not link to any of the tracks, and "Day Tripper" the album turns out to be a compilation of Beatles covers which does not, at least as far as the listed information shows, even contain the song "Day Tripper".
And if you delve into the internals of the Freebase music schema, you can quickly develop a guess about why the data has not all been filled in: there's too damn much structure. A music/track is a recording of a music/composition. The track can appear on multiple music/releases, each of which is a publication of a particular music/album. Unless you need to model who was in the band during the making of an album, in which case the album links instead to a set of music/recording_contributions, which is each a combination of albums, contributors and roles.
Oh, except compositions can be recorded "as albums", in which case they link to music/album without going through music/track, and tracks can appear directly on releases without going through music/album. And there's no current property for saying that a given track is an alternate version of another, but from following Freebase modeling discussions I can confidently guess that they'd model that by saying that a music/track links to something like a music/track_derivation, which itself is a combination of original track, derivative track, deriving artist (or music/track_derivation_contribution) and derivation type. And Freebase's query-language doesn't provide any recursion, so if these relationships chain, good luck querying them.
Music Ontology
This isn't a database, just an attempt at a model for one. And, grimly, it's another quantum level more elaborately and unusably correct than the Freebase model. Even "MO Basics" (and the "Overview" has 22 more tables of explication beyond these "Basics", without getting into the "details") includes conceptual distinctions between Composition, Arrangement, Recording, Musical Work, Musical Item, MusicalExpression and MusicalManifestation. And then there are pages upon pages of minutely itemized trivia like beginsAtDuration, djmix_of, paid_download (and "paiddownload", which is different in some way I couldn't figure out), AnalogSignal, isFactorOf... This list is bad because it's too long, but the fact that it's in the schema means that it's also bad because no matter how long it is, it will never include every nuance you ever find yourself wanting, and thus over time it will only accumulate more debris.
A tour-de-force into a cul-de-sac.
The Rest of the Web
Searching on any particular band or bit of music will unearth dozens or hundreds of other sites that contain bits of the information we need: stores, discographies, databases, forums, fan pages, official sites. Almost universally, these are either unqueriable flat HTML pages, or tree-structured databases with even less interlinking than the above sites. Encyclopaedia Metallum, my favorite metal site, has full track listings for a genuinely mind-boggling number of releases by an astonishing number of bands, but the tracks themselves are not data-objects and a machine can find out nothing about them. There are several lovingly hand-crafted Beatles discographies on the web, all far too detailed for our original casual query, and all essentially useless to a computer attempting to help us.
So: Ugh. Triple ugh because a) the population of people willing to put time and energy into filling out music-related data-forms is obviously huge, b) the modeling problems are not intractably complicated in any theoretical sense, c) MusicBrainz and Freebase, at least (and the system I'm designing at work, I think), seem to be technically sufficient to represented the data correctly. If only we had a better plan.
DiscO
So here's my attempt at a better plan. I call it DiscO, for Discographic Ontology; that is, it's a scheme for structuring discographies. It is not an attempt at an abstract physics of human air-vibrating creativity, it is just an outline of a way to write down the information about bands, the music they've made, and how that music was released. It's intended to be simple enough that you can imagine people actually filling in the data, but expressive enough that the data can support interesting queries. And it's specifically intended to model nuance abstractly, so that it can accommodate some kinds of new needs without perpetually having to itself expand.
There are four basic types:
Artist - The Beatles, Big Country, Megadeth, Frank Zappa, whatever...
Release - an individual album, single, compilation, whatever; Rubber Soul, Past Masters [Remastered], "Day Tripper"/"We Can Work It Out"...
Track - an individual version of a song; "Day Tripper", "Day Tripper [mono]", "Day Tripper (performed live on pan flute and triangle by Zamfir and Elmo)", etc.
Sequence - any collection of releases; Original Albums, Japanese Cassette Singles, 2009 Remasters, etc.
These are related to each other like this:
Artists mostly have Sequences. Sequences can be anything, but many artists would have some standard ones: Original Albums, Singles, Compilations, Remastered Albums, Current Catalog.
Sequences have Releases (and Artists).
Releases have Dates, Labels and Tracks. A Release may have an Artist directly, but more often would have one indirectly via a Sequence.
Releases may be related to each other via Alternate Version/Original Version links. Thus Past Masters, Vol. 1 & 2 and Past Masters [Remastered] are both Releases, but Past Masters [Remastered] has an Original Version link to Past Masters, Vol. 1 & 2, and Past Masters, Vol. 1 & 2 has an Alternate Version link to Past Masters [Remastered].
Tracks have Durations. A Track may have an Artist directly (so individual tracks on multi-artist compilations can be attributed correctly), but more often would have one indirectly via Release (which itself may have one indirectly via Sequence).
Tracks may also be related to each other via Alternate Version/Original Version links. "Day Tripper" and "Day Tripper [mono]" are both Tracks, but "Day Tripper" has an Alternate Version link to "Day Tripper [mono]", and "Day Tripper [mono]" has an Original Version link to "Day Tripper". (We can get into geek arguments about which versions are the same and which are derivations (of which!), if we want, but whatever we decide, we can model.)
Restated in schema-ish form, that's:
Artist
- Sequence
- Release
- Track
Sequence
- Artist
- Release
Release
- Sequence
- Artist
- Date
- Label
- Track
- Original Version
- Alternate Version
Track
- Artist
- Duration
- Original Version
- Alternate Version
I think that's basically enough. What it gives up in expressiveness, it gains in usability. Our Beatles data can now, I think, be modeled both tractably and informatively. We can hook up all the versions of albums and versions of songs. We can create whatever sequences we need, and since the sequences themselves are just data, it's fine to have "Canadian Singles" for the Beatles and "Fanzine Flexis" for The Bedsitters without implying that either band should also have the other.
And using Thread, the query-language I will (before long, hopefully) be attempting to spread through the universe, we can start to ask our questions in a way the computer can answer:
Track:=Day Tripper.Release
This is our naive query. It gets all the releases that have any track called exactly "Day Tripper". Good for assuring us there's some data in the bucket, but not much help in answering our question.
Track:=Day Tripper.Release:(.Artist:=The Beatles)
That limits our results to albums by the Beatles, but there are still too many. With our fully-interlinked data-model, though, we can now actually ask something that is much closer to what we mean:
Artist:=The Beatles.Sequence:=Current Catalog.Release:(.Track:=Day Tripper)
That is, find the artist The Beatles, get their Current Catalog sequence, get that sequence's releases, and filter those releases down to the ones that contain a track called exactly "Day Tripper". This is progress.
But "called exactly 'Day Tripper'" will exclude "Day Tripper [mono]", which isn't what we want to do. We're trying to ask a musical question about a song, not a typographical question about a title. But this, too, we have the powers to cope with:
Track|Day Trippers=(...__,Original Version:=Day Tripper)
Artist:=The Beatles.Sequence:=Current Catalog.Release:(.Track.Day Trippers)|
DT Versions=(.Track:Day Trippers=?),
Other Tracks=(.Track:Day Trippers=_._Count)
DT Versions=(.Track:Day Trippers=?),
Other Tracks=(.Track:Day Trippers=_._Count)
This time we first define a new inferred relationship on Track called "Day Trippers", which gets the Track, all its Original Versions, all their Original Versions (recursively), and then filters this set of tracks down to just the ones called "Day Tripper".
Then we get the Beatles' current catalog releases again, but this time instead of checking each release for a track named "Day Tripper", we use our Day Trippers relationship to check for a track that is, or is derived from, "Day Tripper". And then, for each of the releases that have one, we infer two new relationships: "DT Versions" tells us which track(s) on this release are versions of "Day Tripper", and "Other Tracks" counts the tracks on this release that are not derivations of "Day Tripper".
I.e.:
| # | Release | DT Versions | Other Tracks |
| 1 | Past Masters [Remastered] | Day Tripper | 32 |
| 2 | Mono Box Set | Day Tripper [mono] | 212 |
| 3 | Stereo Box Set | Day Tripper | 238 |
So now we know our choices. It took us so long to find out, but we found out.
Tantalizing Postscript: But now that we have these three options before us, how do their contents overlap or differ, track by track?! We could bring up three different windows and squint at them. Or we could ask the computer:
Artist:=The Beatles.Sequence:=Current Catalog.Release:(.Track.Day Trippers)
/(.Track...__,Original Version:##1)/=nodes
/(.Track...__,Original Version:##1)/=nodes
Aaah. I see now. (How nice it will be when I'm allowed to show you...)