27 June 2008 to 21 April 2008
¶ Whole Data · 27 June 2008 essay/tech
So there's "the Semantic Web", which has lots of philosophical baggage, and then there's "Linked Data", which is supposed to represent unpacking only the practical stuff from the piles of baggage. A secret password for a cult within a cult. A cult-within-a-cult big enough to have a two-day conference dedicated to it, but not yet big enough that the final panel on the second day wasn't facing a mostly empty room.
And not quite yet a cult-within-a-cult with a coherent, useful agenda, I think. If you want to stage a grassroots revolution, you need to figure out four things:
- What is the big change you're going to bring about?
- What's the work that has to be done?
- Who has to do the work?
- What's in it for them?
Unfortunately, the current Linked Data agenda kind of answers these questions like this:
- The big change is that all "data records" will have universally unique names, which will all also be web addresses so you can look them (or maybe something about them, or maybe kind of both) up with a browser, and when you look them up they will point you to other things.
- The work to be done is that everybody must either convert their data into a list of individual subject-verb-objects assertions, including meta-assertions about those first assertions, or else at least construct the meta-assertions about the assertions and construct the unique names for the original assertions even if they don't actually exist. And all this should be done in a language (and data model) called RDF, most explanations of which begin by apologizing for it, which is understandable because it's the data-modeling equivalent of assembly language for programming, and pretty much nobody voluntarily works with nothing but levers when there's a Home Depot nearby.
- The people who have to do the work are the owners of data.
- The thing that's in it for them is that other people might mash up their data into something else, or discover it serendipitously, or effortlessly integrate it. Except Linked Data doesn't mean Open Linked Data, so you don't have to expose your data to the world, so in that case the benefit is, um, something something ontology something toolchain serendipitous LOOK!! OVER THERE!! IT'S A GIANT GLOBAL GRAPH EATING THE EMPIRE STATE BUILDING!!!!!! THIS IS THE WEB DONE RIGHT!!!!!
This is a pretty bad plan for a revolution. It's hard to understand why the big change is big, never mind why it's good; the work is artificially difficult and deliberately obscure; the people who would have to do it are basically unprepared; and the "benefits" are peripheral more or less by definition.
Let me try a different set of answers:
- The big change is that we can finally afford to store most kinds of information in a way that separates the logical data model from the storage mechanics, so that the only thing that constrains what you can do with your data is your data.
- The work to be done is that someone needs to build a node/arc-oriented database system, with accompanying data-model and query-language, that brings this idea up to the usability level of, say, a simple Excel spreadsheet or Google Base.
- The people who have to do the work are data-system developers, whether new companies or existing ones.
- The things that are in it for them are that the market of people with data is huge and growing, and the market for people with highly interconnected data is newly huge and frantically growing, and the existing RDBMS/SQL-based tools for analyzing and exploring and publishing that data are so awful that we will look back on them like we look back on COBOL and punch-cards. There is both money and human progress to be made.
Mine probably initially seems like a smaller revolution. My enemy is not the web. My revolution is not about URIs or linking or dereferencing or ontology subsumption or transitive closure. I just know that we've wasted human-centuries of time fighting against internal problems introduced by relational-database implementations, and built legions of crappy, inflexible, inhumane data systems because the limitations of our databases constrained what questions we allowed humans to even ask, never mind get answered. And I know that computers are now big enough and fast enough that for increasingly many datasets, the old ugliness is no longer even remotely necessary.
And thus the new ugliness, RDF and SPARQL, is a painfully tragic missed opportunity. I no more want to be buried in triples than I wanted to be boxed into tables. Where SQL and tables made some simple things relatively simple, some simple things very hard, and most hard things really hard, RDF and SPARQL make all things theoretically possible, but all specific trivial things barely feasible, any simple things too cumbersome to attempt without assistance, and hard things moot because the simple things raise so many epistemological issues that all actual work halts.
We can do better. Let's call this new movement Whole Data, like whole food. Let our data be what it is to people, not what it's easier to be to machines. I don't claim this is any kind of new science. Object-oriented databases aren't a new idea, and arguably a binary-relation node/arc data-model is more or less what the original idea of a "relational" database was before mundane practicality spent a few decades abusing it. But we can build it now. We can build it so that people can use it, easily and without having to learn some whole esoteric new trade.
And yes, a node/arc Whole Data database will lend itself incredibly well to publishing that data on the web. Arcs are links, and the web is made of links, and it's deliciously easy to turn links into links. Moreover, arcs are labeled links, and labeled links mean that machines can do something useful with them. But it is not the job of each data owner to rewrite their own database tools. It is not the job of each webmaster to figure out how to "semantically annotate" their pages. This is a revolution in data-modeling abstraction, and it will be fought by software designers and developers.
And linking disparate datasets together, which is supposed to be the whole point of Linked Data, and thus the whole point of this slightly sad and more than slightly confused conference I went to last week, is only barely a technical problem to begin with, and it's not at all clear to me that the technical agenda of this subcult actually makes non-trivial linking any easier. Most of the claimed benefits, even if you don't worry about whom they're benefits for, seem to me like imaginative hand-waving.
- Giving things unique IDs does make it easier to talk about them. But you can have IDs in table records, so that isn't new, and you can refer to things by instructions instead of IDs and most of the time it doesn't make a lot of difference, so IDs aren't even always necessary. And giving things web IDs is a totally orthogonal issue about publishing that isn't about the data itself at all, and makes no more general sense than saying that all children should be named with cell-phone numbers.
- You can "mesh together" RDF sets. Sometimes, modulo some obtuse URI issues. And if the sets' conceptual data models are compatible enough, you might be able to get something out of the combination. But this is more or less true of relational database tables, too. Exchanging data is not difficult. CSV, JSON, XML, whatever. Agreeing what the data should be is difficult, and agreeing what it should be in triples is no easier than agreeing what it should be in tables. (Maybe easier in theory, but definitely harder in current practice.) Integration is never "effortless". It's just that sometimes somebody else has already done the effort of reaching agreement, and sometimes they haven't.
- My adorable little FOAF file can link to yours, and we can both link ours to Tim Berners-Lee's. But this is a toy "data web". It doesn't scale. Currently it doesn't even scale technically, as the web is too slow for queries to be federated out across every foafy server on the planet, but solving the technical problem will only make it faster for us to see how useless the answers are for human reasons. Every level of remove you go through is a chance for context or trust or meaning to be lost. I don't know how you decide who goes in your file, and I certainly don't know how the people in your file decide who goes in theirs. If you find your way to me and then to Tim, it is unlikely to do you very much real good. On one hand, his office is about two blocks away from mine. On the other hand, the only reason it's becoming marginally more likely that he knows me is that I keep complaining about things he's working on. Small Pieces Loosely Joined works great when you have time to examine the joins and the pieces and figure out which ones are useful for some particular personal purpose. Carry them home, trim them, water them, love them, and you might get a garden for your efforts. Send a machine out to gather them all up at once and you'll get a mushy septic field with some fine heirloom tomatoes submerged somewhere in it.
- As long as our cults are small, sometimes we can find each other with nothing but our code words. But thinking that URI standards will yield pervasive serendipity is socially oblivious. Nothing I do in my FOAF file will ensure that you find me when you look at Tim's. Distributed linking is inherently asymmetric, and even if you crawl the entire web to construct all the missing inverses, the numbers are implacable. You cannot center yourself in a social network without cooperation. The space of associativity is curved: you can move from the obscure to the popular easily (indeed often inexorably), and along popularity contours with some effort. The imbalance of attention is a human phenomenon, not a technical one.
But my little revolution, at least, doesn't involving changing human nature. Distrust any that does. Whole Data is not magic, it's just healthier than the bleached, bromated version, and yummier than chewing raw semantic bran. All I'm trying to do is make information tools that allow humans to be less mechanical, and machines to be more helpful.
Here are some helpfulnesses:
- A node/arc database can handle multiple-value and no-value relationships just as easily as single-value relationships. Multiple-value relationships are 90% of the interesting structure of data, yet they're basically the bane of relational-database usability, and RDF only handles them if you don't care what order they go in or how easy it is to find out what they all are. No-value relationships are painful in relational databases, and inexpressible in RDF.
- In a node/arc database you can make data-model modifications without touching any node whose data is not actually involved. The model does not determine the storage. In relational databases the model is the storage. Unless you already consider yourself a "working ontologist" you don't want to know what it takes to express a model in (actually for, because you can't do it in) RDF. Real models change all the time, so this can't be a half-assed after-thought.
- In a node/arc database you can look at any data from the perspective of any other data. There's no "top", there's just "outward from here". In a relational database your tables and indexes limit your perspectives. In RDF there's no "top", but neither is there any "here"; all you can do is scan assertions until your patience runs out, looking for ones that say something else somethings this, or this somethings something else. Being able to stand anywhere and look in any direction is the difference between exploration and a zoo, and thus between discovery and watching an okapi crap.
- A node/arc data structure can be browsed. Relational tables and RDF can mostly only be searched, and browsing is a UI illusion built on top of searching. But browsing, wandering, connecting, following, compiling, discarding: these are how humans organize and comprehend information, and we deserve a database in which those are the cheapest and sturdiest building blocks, not the most expensive and fragile fabrications.
- In a node/arc database with a path-based query language, human browsing can be used as machine training, and human questions can be formulated for machine processing in structurally the same way they would be stated for human evaluation. We think in contexts and connections, not in subgraph matching or index inversion. We do not start every inquiry with a list of all the universe's truths. We start somewhere, and follow paths. We need to be able to send our questions down these paths, down all the paths at once, and have them come back with their own answers.
The project I'm working on has a database system like I describe, and a data-model that's more usable than RDF, and a path-based query-language I wrote that's better than SPARQL. I want this thing to exist. I think we need it to exist. I'd rather it already existed, and if somebody else comes out with one tomorrow that's at least as good as mine, I'll be totally thrilled to use that instead. Mine isn't going to come out tomorrow. I don't know when it will. I don't know who will be totally thrilled, the day mine comes out, to use that one instead of the one they were working on.
But I know these small improvements matter. Information matters, and understanding matters, and the tools for getting from one to the other matter. I think our ability to make use of information is part of how we are going to survive on Earth. So this, for the moment, is what I'm trying to do for us.
And not quite yet a cult-within-a-cult with a coherent, useful agenda, I think. If you want to stage a grassroots revolution, you need to figure out four things:
- What is the big change you're going to bring about?
- What's the work that has to be done?
- Who has to do the work?
- What's in it for them?
Unfortunately, the current Linked Data agenda kind of answers these questions like this:
- The big change is that all "data records" will have universally unique names, which will all also be web addresses so you can look them (or maybe something about them, or maybe kind of both) up with a browser, and when you look them up they will point you to other things.
- The work to be done is that everybody must either convert their data into a list of individual subject-verb-objects assertions, including meta-assertions about those first assertions, or else at least construct the meta-assertions about the assertions and construct the unique names for the original assertions even if they don't actually exist. And all this should be done in a language (and data model) called RDF, most explanations of which begin by apologizing for it, which is understandable because it's the data-modeling equivalent of assembly language for programming, and pretty much nobody voluntarily works with nothing but levers when there's a Home Depot nearby.
- The people who have to do the work are the owners of data.
- The thing that's in it for them is that other people might mash up their data into something else, or discover it serendipitously, or effortlessly integrate it. Except Linked Data doesn't mean Open Linked Data, so you don't have to expose your data to the world, so in that case the benefit is, um, something something ontology something toolchain serendipitous LOOK!! OVER THERE!! IT'S A GIANT GLOBAL GRAPH EATING THE EMPIRE STATE BUILDING!!!!!! THIS IS THE WEB DONE RIGHT!!!!!
This is a pretty bad plan for a revolution. It's hard to understand why the big change is big, never mind why it's good; the work is artificially difficult and deliberately obscure; the people who would have to do it are basically unprepared; and the "benefits" are peripheral more or less by definition.
Let me try a different set of answers:
- The big change is that we can finally afford to store most kinds of information in a way that separates the logical data model from the storage mechanics, so that the only thing that constrains what you can do with your data is your data.
- The work to be done is that someone needs to build a node/arc-oriented database system, with accompanying data-model and query-language, that brings this idea up to the usability level of, say, a simple Excel spreadsheet or Google Base.
- The people who have to do the work are data-system developers, whether new companies or existing ones.
- The things that are in it for them are that the market of people with data is huge and growing, and the market for people with highly interconnected data is newly huge and frantically growing, and the existing RDBMS/SQL-based tools for analyzing and exploring and publishing that data are so awful that we will look back on them like we look back on COBOL and punch-cards. There is both money and human progress to be made.
Mine probably initially seems like a smaller revolution. My enemy is not the web. My revolution is not about URIs or linking or dereferencing or ontology subsumption or transitive closure. I just know that we've wasted human-centuries of time fighting against internal problems introduced by relational-database implementations, and built legions of crappy, inflexible, inhumane data systems because the limitations of our databases constrained what questions we allowed humans to even ask, never mind get answered. And I know that computers are now big enough and fast enough that for increasingly many datasets, the old ugliness is no longer even remotely necessary.
And thus the new ugliness, RDF and SPARQL, is a painfully tragic missed opportunity. I no more want to be buried in triples than I wanted to be boxed into tables. Where SQL and tables made some simple things relatively simple, some simple things very hard, and most hard things really hard, RDF and SPARQL make all things theoretically possible, but all specific trivial things barely feasible, any simple things too cumbersome to attempt without assistance, and hard things moot because the simple things raise so many epistemological issues that all actual work halts.
We can do better. Let's call this new movement Whole Data, like whole food. Let our data be what it is to people, not what it's easier to be to machines. I don't claim this is any kind of new science. Object-oriented databases aren't a new idea, and arguably a binary-relation node/arc data-model is more or less what the original idea of a "relational" database was before mundane practicality spent a few decades abusing it. But we can build it now. We can build it so that people can use it, easily and without having to learn some whole esoteric new trade.
And yes, a node/arc Whole Data database will lend itself incredibly well to publishing that data on the web. Arcs are links, and the web is made of links, and it's deliciously easy to turn links into links. Moreover, arcs are labeled links, and labeled links mean that machines can do something useful with them. But it is not the job of each data owner to rewrite their own database tools. It is not the job of each webmaster to figure out how to "semantically annotate" their pages. This is a revolution in data-modeling abstraction, and it will be fought by software designers and developers.
And linking disparate datasets together, which is supposed to be the whole point of Linked Data, and thus the whole point of this slightly sad and more than slightly confused conference I went to last week, is only barely a technical problem to begin with, and it's not at all clear to me that the technical agenda of this subcult actually makes non-trivial linking any easier. Most of the claimed benefits, even if you don't worry about whom they're benefits for, seem to me like imaginative hand-waving.
- Giving things unique IDs does make it easier to talk about them. But you can have IDs in table records, so that isn't new, and you can refer to things by instructions instead of IDs and most of the time it doesn't make a lot of difference, so IDs aren't even always necessary. And giving things web IDs is a totally orthogonal issue about publishing that isn't about the data itself at all, and makes no more general sense than saying that all children should be named with cell-phone numbers.
- You can "mesh together" RDF sets. Sometimes, modulo some obtuse URI issues. And if the sets' conceptual data models are compatible enough, you might be able to get something out of the combination. But this is more or less true of relational database tables, too. Exchanging data is not difficult. CSV, JSON, XML, whatever. Agreeing what the data should be is difficult, and agreeing what it should be in triples is no easier than agreeing what it should be in tables. (Maybe easier in theory, but definitely harder in current practice.) Integration is never "effortless". It's just that sometimes somebody else has already done the effort of reaching agreement, and sometimes they haven't.
- My adorable little FOAF file can link to yours, and we can both link ours to Tim Berners-Lee's. But this is a toy "data web". It doesn't scale. Currently it doesn't even scale technically, as the web is too slow for queries to be federated out across every foafy server on the planet, but solving the technical problem will only make it faster for us to see how useless the answers are for human reasons. Every level of remove you go through is a chance for context or trust or meaning to be lost. I don't know how you decide who goes in your file, and I certainly don't know how the people in your file decide who goes in theirs. If you find your way to me and then to Tim, it is unlikely to do you very much real good. On one hand, his office is about two blocks away from mine. On the other hand, the only reason it's becoming marginally more likely that he knows me is that I keep complaining about things he's working on. Small Pieces Loosely Joined works great when you have time to examine the joins and the pieces and figure out which ones are useful for some particular personal purpose. Carry them home, trim them, water them, love them, and you might get a garden for your efforts. Send a machine out to gather them all up at once and you'll get a mushy septic field with some fine heirloom tomatoes submerged somewhere in it.
- As long as our cults are small, sometimes we can find each other with nothing but our code words. But thinking that URI standards will yield pervasive serendipity is socially oblivious. Nothing I do in my FOAF file will ensure that you find me when you look at Tim's. Distributed linking is inherently asymmetric, and even if you crawl the entire web to construct all the missing inverses, the numbers are implacable. You cannot center yourself in a social network without cooperation. The space of associativity is curved: you can move from the obscure to the popular easily (indeed often inexorably), and along popularity contours with some effort. The imbalance of attention is a human phenomenon, not a technical one.
But my little revolution, at least, doesn't involving changing human nature. Distrust any that does. Whole Data is not magic, it's just healthier than the bleached, bromated version, and yummier than chewing raw semantic bran. All I'm trying to do is make information tools that allow humans to be less mechanical, and machines to be more helpful.
Here are some helpfulnesses:
- A node/arc database can handle multiple-value and no-value relationships just as easily as single-value relationships. Multiple-value relationships are 90% of the interesting structure of data, yet they're basically the bane of relational-database usability, and RDF only handles them if you don't care what order they go in or how easy it is to find out what they all are. No-value relationships are painful in relational databases, and inexpressible in RDF.
- In a node/arc database you can make data-model modifications without touching any node whose data is not actually involved. The model does not determine the storage. In relational databases the model is the storage. Unless you already consider yourself a "working ontologist" you don't want to know what it takes to express a model in (actually for, because you can't do it in) RDF. Real models change all the time, so this can't be a half-assed after-thought.
- In a node/arc database you can look at any data from the perspective of any other data. There's no "top", there's just "outward from here". In a relational database your tables and indexes limit your perspectives. In RDF there's no "top", but neither is there any "here"; all you can do is scan assertions until your patience runs out, looking for ones that say something else somethings this, or this somethings something else. Being able to stand anywhere and look in any direction is the difference between exploration and a zoo, and thus between discovery and watching an okapi crap.
- A node/arc data structure can be browsed. Relational tables and RDF can mostly only be searched, and browsing is a UI illusion built on top of searching. But browsing, wandering, connecting, following, compiling, discarding: these are how humans organize and comprehend information, and we deserve a database in which those are the cheapest and sturdiest building blocks, not the most expensive and fragile fabrications.
- In a node/arc database with a path-based query language, human browsing can be used as machine training, and human questions can be formulated for machine processing in structurally the same way they would be stated for human evaluation. We think in contexts and connections, not in subgraph matching or index inversion. We do not start every inquiry with a list of all the universe's truths. We start somewhere, and follow paths. We need to be able to send our questions down these paths, down all the paths at once, and have them come back with their own answers.
The project I'm working on has a database system like I describe, and a data-model that's more usable than RDF, and a path-based query-language I wrote that's better than SPARQL. I want this thing to exist. I think we need it to exist. I'd rather it already existed, and if somebody else comes out with one tomorrow that's at least as good as mine, I'll be totally thrilled to use that instead. Mine isn't going to come out tomorrow. I don't know when it will. I don't know who will be totally thrilled, the day mine comes out, to use that one instead of the one they were working on.
But I know these small improvements matter. Information matters, and understanding matters, and the tools for getting from one to the other matter. I think our ability to make use of information is part of how we are going to survive on Earth. So this, for the moment, is what I'm trying to do for us.
¶ The Case for Teaching Machines to Understand English · 27 June 2008 child/tech
Applied natural-language-processing work is motivated by the proposition that it's more practical to teach a few computers to understand human languages than it is to teach a lot of people (including every new one) to speak computer languages. The potential advantage, thus, is numeric and large.
So far, though, many people have learned to speak computer languages pretty well, and no computers have learned to understand human languages. Indeed, at this point it's still faster to teach computer languages to humans even if you have to create the humans from scratch first...
So far, though, many people have learned to speak computer languages pretty well, and no computers have learned to understand human languages. Indeed, at this point it's still faster to teach computer languages to humans even if you have to create the humans from scratch first...
1. Trinacria: "Make No Mistake"
Insanely inspired collaboration between viking-metal grind and noise-terror agit-processing, easily the most bracing thing I've heard in years.
2. Leviathan: "Receive the World"
Like being shredded in a slow-motion tornado filled with mid-explosion bombs and extrapolated nightmares.
3. Ihsahn: "Emancipation"
Progressive and necromantic at once, like court music from a Hades starting to gentrify just a little as it discovers its political strength.
4. Moonspell: "Dreamless (Lucifer and Lilith)"
Gothic metal's current standard-bearers.
5. Charon: "Deep Water"
A HIM to Moonspell's Sentenced.
6. Morgion: "Mundane"
A funeral march for glaciers.
7. Dalriada: "Tavaskzköszöntõ"
And at the end of the march, the unexpected moment when you are caught and carried off by sprint-pogoing goat-horned leprechauns and their seven-armed princess who only ever speaks backwards fast.
(All 14 in AAC; 65MB zip file)
Insanely inspired collaboration between viking-metal grind and noise-terror agit-processing, easily the most bracing thing I've heard in years.
2. Leviathan: "Receive the World"
Like being shredded in a slow-motion tornado filled with mid-explosion bombs and extrapolated nightmares.
3. Ihsahn: "Emancipation"
Progressive and necromantic at once, like court music from a Hades starting to gentrify just a little as it discovers its political strength.
4. Moonspell: "Dreamless (Lucifer and Lilith)"
Gothic metal's current standard-bearers.
5. Charon: "Deep Water"
A HIM to Moonspell's Sentenced.
6. Morgion: "Mundane"
A funeral march for glaciers.
7. Dalriada: "Tavaskzköszöntõ"
And at the end of the march, the unexpected moment when you are caught and carried off by sprint-pogoing goat-horned leprechauns and their seven-armed princess who only ever speaks backwards fast.
(All 14 in AAC; 65MB zip file)
¶ 7 Songs · 9 June 2008
By request:
"List seven songs you are into right now. No matter what the genre, whether they have words, or even if they're not any good, but they must be songs you're really enjoying now, shaping your spring. Post these instructions in your blog along with your 7 songs. Then tag 7 other people to see what they're listening to."
The tags: Bethany, Dennis, Heather, Dan, James, Alan, David.
The songs:
1. Frightened Rabbit: "Head Rolls Off"
:05 snippets of :30 clips is no way to fall in love with anything subtle. For Frightened Rabbit it took me a mix received and another one given to stop my scanning long enough to register dawning awe. This may be the best album of tragic-heroism since Del Amitri's Waking Hours, and "Head Rolls Off" is as defiantly hopeful a life anthem as anything since the Waterboys' "I Will Not Follow".
2. Alanis Morissette: "Underneath"
"We have the ultimate key to the cause right here." Alanis says awkward, earnest things that I also believe.
3. Jewel: "Two Become One"
If you don't have the courage to be kaleidoscopically foolish while you're still young enough, you won't have the chance to turn your "2"s into "Two"s when you're a little older, a little wiser, and a little less afraid of yourself.
4. Delays: "Love Made Visible"
Joy made audible.
5. Runrig: "Protect and Survive"
There can be echoes, inside blood, of decades and centuries and stone and water.
6. Okkervil River: "Plus Ones"
Not only probably the best gimmick song ever, but a gimmick song that actually ennobles other gimmick songs.
7. M83: "Graveyard Girl"
Best mid-80s synthpop song since the mid-80s. When my daughter is old enough to gripe about all the old crap I listen to from before she was alive, which thus can't possibly matter, I'll be able to tell her that at least she was around to dance with me to this.
"List seven songs you are into right now. No matter what the genre, whether they have words, or even if they're not any good, but they must be songs you're really enjoying now, shaping your spring. Post these instructions in your blog along with your 7 songs. Then tag 7 other people to see what they're listening to."
The tags: Bethany, Dennis, Heather, Dan, James, Alan, David.
The songs:
1. Frightened Rabbit: "Head Rolls Off"
:05 snippets of :30 clips is no way to fall in love with anything subtle. For Frightened Rabbit it took me a mix received and another one given to stop my scanning long enough to register dawning awe. This may be the best album of tragic-heroism since Del Amitri's Waking Hours, and "Head Rolls Off" is as defiantly hopeful a life anthem as anything since the Waterboys' "I Will Not Follow".
2. Alanis Morissette: "Underneath"
"We have the ultimate key to the cause right here." Alanis says awkward, earnest things that I also believe.
3. Jewel: "Two Become One"
If you don't have the courage to be kaleidoscopically foolish while you're still young enough, you won't have the chance to turn your "2"s into "Two"s when you're a little older, a little wiser, and a little less afraid of yourself.
4. Delays: "Love Made Visible"
Joy made audible.
5. Runrig: "Protect and Survive"
There can be echoes, inside blood, of decades and centuries and stone and water.
6. Okkervil River: "Plus Ones"
Not only probably the best gimmick song ever, but a gimmick song that actually ennobles other gimmick songs.
7. M83: "Graveyard Girl"
Best mid-80s synthpop song since the mid-80s. When my daughter is old enough to gripe about all the old crap I listen to from before she was alive, which thus can't possibly matter, I'll be able to tell her that at least she was around to dance with me to this.
¶ Never Mind the Semantic Web (or, 13 Reasons Not to Let a Computer Scientist Choose a Name (or a Problem)) · 3 June 2008 essay/tech
1. "Semantic". By starting the name this way, you have essentially, avoidably, uselessly doomed the whole named enterprise before it starts. Most people don't have the slightest idea what this word even means, most of the people who do have an idea think it implies pointless distinctions, and everybody left after you eliminate those two groups will still have to argue about what "semantic" means. This is a rare actual example of begging the question. Or to put it in terms you will understand: congratulations, you've introduced terminological head recursion. Any wonder the program never gets around to doing anything?
2. "The Semantic Web". The "The" and the "Web" and the capitalization combine to suggest, even before anybody compounds the error by stating it explicitly, that this thing, which nobody can coherently explain, is intended to compete with a thing we already grok and see and fetishize. But this is totally not the point. The web is good. What we're talking about are new tools for how computers work with data. Or, really, what we're talking about are actually old tools for working with data, but ones that a) weren't as valuable or critical until the web made us more aware of our data and more aware of how badly it is serving us, and b) weren't as practical to implement until pretty recently in processor-speed and memory-size history.
3. "FOAF". There have been worse acronyms, obviously, but this one is especially bad for the mildness of its badness. It sounds like some terrible dessert your friends pressured you to eat at a Renaissance Festival after you finally finished gnawing your baseball-bat-sized Turkey Sinew to death.
4. FOAF as the stock example. You could have started anywhere, and almost any other start would have been better for explaining the true linked nature of data than this. "Friend" is the second farthest thing from a clean semantic annotation in anybody's daily experience. I'm barely in control of the meaning of my own friend lists, and certain wouldn't do anything with anybody else's without human context.
5. Tagging as the stock example. "Tagged as" is the first farthest thing from a clean semantic annotation in anybody's daily experience.
6. Blogging as the stock example. Even if your hand-typed RDFa annotations are nuggets of precious ontological purity, you can't generate enough of them by hand to matter. Your writing is for humans, not machines, and wasting brains the size of planets on chasing pingbacks is squandering electricity. We already know how to add to humanity's knowledge one fact at a time. The problem is in grasping the facts en masse, in turning data to information to knowledge to wisdom to the icecaps not melting on us.
7. Anything AI. Natural-language-processing and entity-extraction are interesting information-science problems, and somebody, somewhere, probably ought to be working on them. But those tools are going to pretty much suck for general-purpose uses for a really long time. So keep them out of our way while we try to actually improve the world in the meantime.
8. "Giant Global" Graph. The "Giant" and "Global" parts are menacing and unnecessary, and maybe ultimately just wrong. In data-modeling, the more giant and global you try to be, the harder it is to accomplish anything. What we're trying to do is make it possible to connect data at the point where humans want it to connect, not make all data connected. We're not trying to build one graph any more than the World Wide Web was trying to build one site.
9. Giant Global "Graph". This is a classic jargon failure: using an overloaded term with a normal meaning that makes sense in most of the same sentences. I don't know the right answer to this one, since "web" and "network" and "mesh" and "map" are all overloaded, too. We may have to use a new term here just so people know we're talking about something new. "Nodeset", possibly. "Graph" is particularly bad because it plays into the awful idea that "visualization" is all about turning already-elusive meaning into splendidly gradient-filled, non-question-answering splatter-plots.
10. URIs. Identifying things is a terrific idea, but "Uniform" is part of the same inane pipe-dream distraction as "Giant" and "Global", and "Resource" and the associated crap about protocols and representations munge together so many orthogonal issues that here again the discussions all end up being Zenotic debates over how many pins can be shoved halfway up which dancing angel.
11. "Metadata". There is no such thing as "metadata". Everything is relative. Everything is data. Every bit of data is meta to everything else, and thus to nothing. It doesn't matter whether the map "is" the terrain, it just matters that you know you're talking about maps when you're talking about maps. (And it usually doesn't matter if the computer knows the difference, regardless...)
12. RDF. It's insanely brilliant to be able to represent any kind of data structure in a universal lowest-common-denominator form. It's just insane to think that this particular brilliance is of pressing interest to anybody but data-modeling specialists, any more than hungry people want to hear your lecture about the atomic structure of food before they eat. RDF will be the core of the new model in the same way that SGML was the core of the web.
13. The Open-World Hypothesis. See "Global", above. Acknowledging the ultimate unknowability of knowledge is a profound philosophical and moral project, but not one for which we need computer assistance. Meanwhile, computers could be helping us make use of what we do know in all our little worlds that are already more than closed enough.
2. "The Semantic Web". The "The" and the "Web" and the capitalization combine to suggest, even before anybody compounds the error by stating it explicitly, that this thing, which nobody can coherently explain, is intended to compete with a thing we already grok and see and fetishize. But this is totally not the point. The web is good. What we're talking about are new tools for how computers work with data. Or, really, what we're talking about are actually old tools for working with data, but ones that a) weren't as valuable or critical until the web made us more aware of our data and more aware of how badly it is serving us, and b) weren't as practical to implement until pretty recently in processor-speed and memory-size history.
3. "FOAF". There have been worse acronyms, obviously, but this one is especially bad for the mildness of its badness. It sounds like some terrible dessert your friends pressured you to eat at a Renaissance Festival after you finally finished gnawing your baseball-bat-sized Turkey Sinew to death.
4. FOAF as the stock example. You could have started anywhere, and almost any other start would have been better for explaining the true linked nature of data than this. "Friend" is the second farthest thing from a clean semantic annotation in anybody's daily experience. I'm barely in control of the meaning of my own friend lists, and certain wouldn't do anything with anybody else's without human context.
5. Tagging as the stock example. "Tagged as" is the first farthest thing from a clean semantic annotation in anybody's daily experience.
6. Blogging as the stock example. Even if your hand-typed RDFa annotations are nuggets of precious ontological purity, you can't generate enough of them by hand to matter. Your writing is for humans, not machines, and wasting brains the size of planets on chasing pingbacks is squandering electricity. We already know how to add to humanity's knowledge one fact at a time. The problem is in grasping the facts en masse, in turning data to information to knowledge to wisdom to the icecaps not melting on us.
7. Anything AI. Natural-language-processing and entity-extraction are interesting information-science problems, and somebody, somewhere, probably ought to be working on them. But those tools are going to pretty much suck for general-purpose uses for a really long time. So keep them out of our way while we try to actually improve the world in the meantime.
8. "Giant Global" Graph. The "Giant" and "Global" parts are menacing and unnecessary, and maybe ultimately just wrong. In data-modeling, the more giant and global you try to be, the harder it is to accomplish anything. What we're trying to do is make it possible to connect data at the point where humans want it to connect, not make all data connected. We're not trying to build one graph any more than the World Wide Web was trying to build one site.
9. Giant Global "Graph". This is a classic jargon failure: using an overloaded term with a normal meaning that makes sense in most of the same sentences. I don't know the right answer to this one, since "web" and "network" and "mesh" and "map" are all overloaded, too. We may have to use a new term here just so people know we're talking about something new. "Nodeset", possibly. "Graph" is particularly bad because it plays into the awful idea that "visualization" is all about turning already-elusive meaning into splendidly gradient-filled, non-question-answering splatter-plots.
10. URIs. Identifying things is a terrific idea, but "Uniform" is part of the same inane pipe-dream distraction as "Giant" and "Global", and "Resource" and the associated crap about protocols and representations munge together so many orthogonal issues that here again the discussions all end up being Zenotic debates over how many pins can be shoved halfway up which dancing angel.
11. "Metadata". There is no such thing as "metadata". Everything is relative. Everything is data. Every bit of data is meta to everything else, and thus to nothing. It doesn't matter whether the map "is" the terrain, it just matters that you know you're talking about maps when you're talking about maps. (And it usually doesn't matter if the computer knows the difference, regardless...)
12. RDF. It's insanely brilliant to be able to represent any kind of data structure in a universal lowest-common-denominator form. It's just insane to think that this particular brilliance is of pressing interest to anybody but data-modeling specialists, any more than hungry people want to hear your lecture about the atomic structure of food before they eat. RDF will be the core of the new model in the same way that SGML was the core of the web.
13. The Open-World Hypothesis. See "Global", above. Acknowledging the ultimate unknowability of knowledge is a profound philosophical and moral project, but not one for which we need computer assistance. Meanwhile, computers could be helping us make use of what we do know in all our little worlds that are already more than closed enough.
Frightened Rabbit: "The Modern Leper" (1.8M mp3)
Irresistible loss, concussive modernity and Scottish rain.
(via a birthday mix from B!)
Irresistible loss, concussive modernity and Scottish rain.
(via a birthday mix from B!)
Eventually, probably, we will figure out how to have computers make some kind of sense of human language. That will be cool and useful, and will change things.
But it's a hard problem, and in the short term I think much of the work required is mostly harder than it is valuable. The big current problems I care about in information technology involve letting computers do things computers are already good at, not beating human heads against them hoping they'll become more human out of sympathy.
So I'm already not the most receptive audience for Powerset, the latest attempt at "improving search" via natural-language processing. I don't think "search" is the problem, to begin with, and I don't think "searching" by typing sentences in English is an improvement even if it works.
And I don't think it works. But make up your own mind. I put together a very simple comparison page for running a search on Powerset and Google side-by-side. And then I ran some. Like these:
what's the closest star?
who was the King of England in 1776?
what movie were Gena Rowlands and Michael J. Fox in together?
new MacBook Pros today?
who are the members of Apple's board of directors?
what's the population of Puerto Rico?
when is Father's Day?
what was the last major earthquake in Tokyo?"
bands like Enslaved
who is Nightwish's new singer?
who is Anette Olzon?
and then, because Powerset suggested it:
who is Anette Olson?
and then, because Google suggested it:
who is Annette Olson?
I think, given these results, it's very hard to argue that Powerset's NLP is doing us much good. At least, not yet. And I'm not their (or anybody's) VC, but I wouldn't be betting a team of salaries that it's going to any time soon.
[12 August 2008 note: the above queries are all still live, and some generate different results today than they did when I posted this. Powerset now gets Anette Olzon, although they still also suggest Anette Olson despite having no interesting results for it, and it still takes Google to suggest fixing Anette Olson to Annette Olson.
The most bizarre new result, though, is that currently the Powerset query-result page for "what movie were Gena Rowlands and Michael J. Fox in together?" is itself the top hit in Google for that query.]
But it's a hard problem, and in the short term I think much of the work required is mostly harder than it is valuable. The big current problems I care about in information technology involve letting computers do things computers are already good at, not beating human heads against them hoping they'll become more human out of sympathy.
So I'm already not the most receptive audience for Powerset, the latest attempt at "improving search" via natural-language processing. I don't think "search" is the problem, to begin with, and I don't think "searching" by typing sentences in English is an improvement even if it works.
And I don't think it works. But make up your own mind. I put together a very simple comparison page for running a search on Powerset and Google side-by-side. And then I ran some. Like these:
what's the closest star?
who was the King of England in 1776?
what movie were Gena Rowlands and Michael J. Fox in together?
new MacBook Pros today?
who are the members of Apple's board of directors?
what's the population of Puerto Rico?
when is Father's Day?
what was the last major earthquake in Tokyo?"
bands like Enslaved
who is Nightwish's new singer?
who is Anette Olzon?
and then, because Powerset suggested it:
who is Anette Olson?
and then, because Google suggested it:
who is Annette Olson?
I think, given these results, it's very hard to argue that Powerset's NLP is doing us much good. At least, not yet. And I'm not their (or anybody's) VC, but I wouldn't be betting a team of salaries that it's going to any time soon.
[12 August 2008 note: the above queries are all still live, and some generate different results today than they did when I posted this. Powerset now gets Anette Olzon, although they still also suggest Anette Olson despite having no interesting results for it, and it still takes Google to suggest fixing Anette Olson to Annette Olson.
The most bizarre new result, though, is that currently the Powerset query-result page for "what movie were Gena Rowlands and Michael J. Fox in together?" is itself the top hit in Google for that query.]
¶ Three From One · 5 May 2008 child/photo



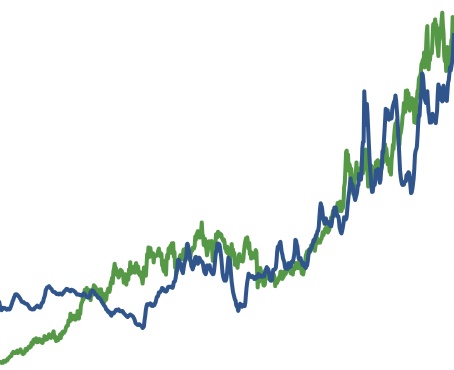
¶ Who Profits From Your Fears? · 5 May 2008
15 years of gas prices and Exxon/Mobil stock.


