28 July 2024 to 25 January 2024 · tagged listen/tech
¶ New Releases by Genre: the comeback begins · 28 July 2024 listen/tech
Spotify killed the New Releases by Genre function of Every Noise at Once when they laid me off and cut off my website from its internal data sources. As I've described previously, the fact that a functional new-release tool required internal data-access, to begin with, was a result of minor structural contingencies, not conceptual or business objections, but in 10 years of working at Spotify I do not remember ever successfully persuading the API team to change a feature. If we're going to get NRbG back, we're going to have to figure out how to rebuild it with the tools we are allowed.
But since I need NRbG myself, emotionally not just logistically, I've kept experimenting with ways of recreating it. It didn't actually take me very long to build a personal version of it. Spotify still does have the best music-service API, by far, and the brute-force approach of searching for artists by genre, and then checking the catalogs of each of those artists one-by-one for new releases every week, does basically work. It just doesn't scale. I'm willing to wait a few minutes for the things I care about the most; it doesn't work to make everybody wait for everything anybody cares about. When I worked at Spotify, I could try to solve some problems for everybody at once; from outside, I am too constrained by API rate limits.
The code I wrote, however, would work for you as readily as for me. Even my "personal" tools are general-purpose, because I assume I'll be curious tomorrow about something I didn't care about today. Maybe it's more accurate to say that I tend to build tools to extend my curiosity as much as to satisfy it, or that extending and satisfying describe a propulsive cycle of curiosity more than alternative goals. I would love to inspire this same kind of curiosity in you, but I would settle for giving you some power and letting you discover what you do with it.
And a few days ago it occurred to me that I can. Or, rather, I can give you the power of my knowledge and experience embodied in code, and you can get the power of running it for yourself by signing up for your own API keys. Which is easy and free.
Here's how:
- go to developer.spotify.com
- click "Log in", and log into your regular Spotify account
- click your name in the top right, and pick Dashboard
- read and accept the developer terms of service
- on the Dashboard page, click "Create app" in the top right
-- App name: NRbG
-- App description: New Releases by Genre
-- Website: (leave blank)
-- Redirect URIs: localhost (NRbG doesn't actually use this)
-- [x] Web API (leave the others unchecked)
-- [x] I understand and agree etc.
- click Save
- on your new NRbG app page, click Settings in the top right
- click "View client secret"
- copy your "Client ID" and "Client secret"
- go to NRbG (DIY version)
- paste your client ID and secret into the boxes
- hit Enter
Now you have power.
The new version of NRbG is a little different from the old one. Instead of a list of all the genres in the world, it has a text box. Type a genre name there and hit Enter, and it will start looking for new releases by artists in or around that genre that came out in the last release week (from Saturday through Friday, because Friday is the traditional music-industry release day).

After a while it might start finding some.
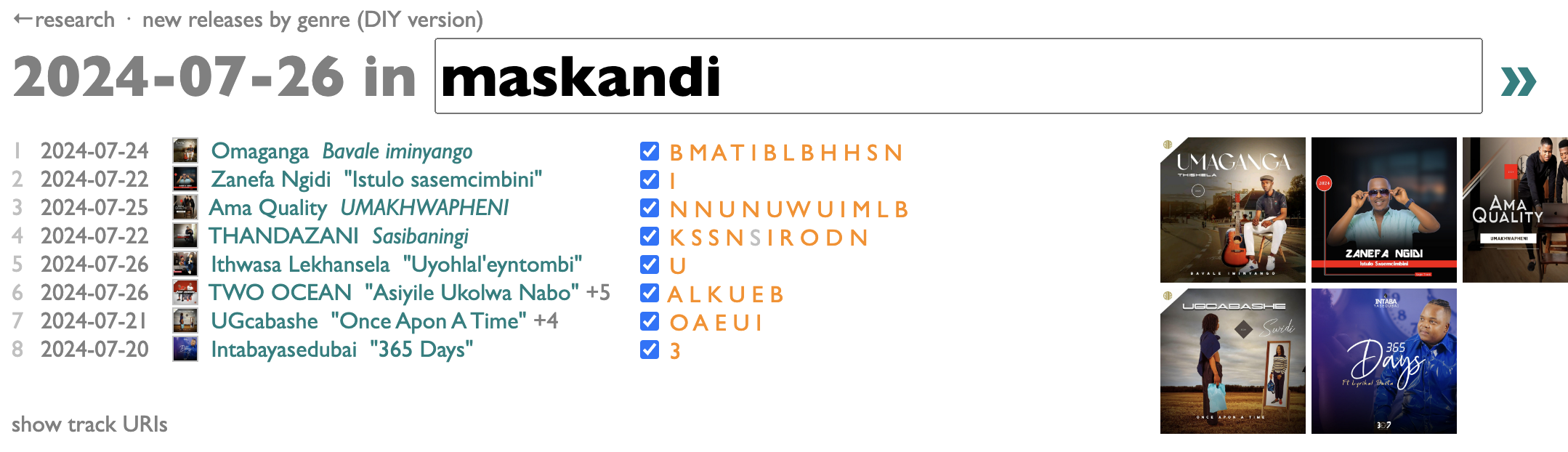
The orange letters are the first letters of each song-title, and you can click on them to hear samples. If a new release has songs that already came out some other way, they will (usually) be grayed out here, like with the gray S above for the advance single "Sekuyiso Isikhathi" from THANDAZANI's album Sasibaningi.
If you click "show track URIs", at the bottom, you'll get a list of the URIs for all the new tracks from the releases you have checked in the list, which you can copy and paste into a blank (or existing) Spotify playlist (using command-C, command-V in the Spotify desktop app). There's also a "save playlist" option, which create a new playlist for you directly if you want.
Because I built this for myself, there are a few non-obvious features.
The text box actually takes a list of things, separated by + signs, and the things can each be any of these:
- a genre (e.g. maskandi or gothic symphonic metal)
- a Spotify artist link/URI
- the name of an individual artist, in quotes, like "Nightwish", although this will find the most popular with that name, so URIs are always safer
- a Spotify playlist link/URI, to be interpreted as a list of artists
- @ and then the name of a record label (e.g. @Profound Lore; the spelling has to be exactly right, but see the note later about playlists)
If your list starts with a +, the results will be added to the bottom of the current list; otherwise the current results will be replaced.
The ">>" link encodes your current parameters, so if you click that, you can then bookmark the resulting URL for reuse.
New releases for selected labels, because labels are the only thing that works properly in new-release API searching, are each shown individually, in labeled groups. Everything else in a given list is combined to make a consolidated set of artists, those artists are then checked for their closest related artists (via Fans Also Like), and the whole thus-expanded list of artists is reordered by collective relevance and then checked individually in order for new releases.
If you don't know the exact genre names you want, offhand, you can also just type a partial name and an asterisk, like metal*, and it will give you a list of all the genre names that include that word. Or you could go to everynoise.com and type an artist name into the search box in the top right to see what genres they belong to.
The words "new" and "releases", in "new releases by genre" at the top, are both actually mode controls. "new" switches back and forth between "new", for new-release mode, and "top", for one-top-release-per-artist sampler mode, not constrained by dates. "releases" cycles through "releases" (everything), "albums" (no singles or compilations) and "singles" (no albums or compilations).
If you want to get only 1 track per release, for sampler purposes, you can put "1/" before your list. Or indeed any number and then a "/". This will pick the most popular however-many tracks on each release, and gray out the rest (and exclude them from the URI list) like the non-new tracks on new releases.

You might notice that this app, although it requires your API keys, does not itself log into your Spotify account. This is intentional. Many Spotify features are personalized for you in complicated ways, if you are logged in, and for exploratory purposes we don't want that. This means, too, that this app cannot access or modify your personal information. But if you want to control its behavior by giving it more information, it can look up non-private playlists, so that's the mechanism.
If you use a playlist as input (yours or anybody else's), it will look for new releases by the primary artists of the tracks in that playlist and their related artists, but excluding the specific releases already in the playlist. So if you, like me, spend a lot of time using this tool every Friday to make a playlist of new releases you want to hear, you can put that playlist's URI back into the same tool and it will check to see if there's anything else related that you might have missed.
In addition, once you've set up your API keys and NRbG is working, the playlist-profile page in the everynoise research tools also gets a couple added features for finding new releases. Put a playlist link or URI into that view, and it already shows you genres and record labels for every track in the list. But scroll to the bottom of the page, and you'll also see something like this:

The "see new releases" line gives you three links to NRbG for different ways of expanding on this list, each with a set of parameters pre-filled from the data in this playlist.
And, for one last bonus feature, you can check an earlier week by putting that week's Friday date (in YYYY-MM-DD format) at the beginning of your input as an override, like this:

and hit Enter to get:

You can even check whole years by including just a year, although be warned, in both cases, that release-date data gets unreliable pretty quickly once you go back beyond the very recent past.
I don't know what else I'll do with this. Probably more, because it's fun. Feedback, error reports and ideas are all welcome, in the meantime.
See what you find.
But since I need NRbG myself, emotionally not just logistically, I've kept experimenting with ways of recreating it. It didn't actually take me very long to build a personal version of it. Spotify still does have the best music-service API, by far, and the brute-force approach of searching for artists by genre, and then checking the catalogs of each of those artists one-by-one for new releases every week, does basically work. It just doesn't scale. I'm willing to wait a few minutes for the things I care about the most; it doesn't work to make everybody wait for everything anybody cares about. When I worked at Spotify, I could try to solve some problems for everybody at once; from outside, I am too constrained by API rate limits.
The code I wrote, however, would work for you as readily as for me. Even my "personal" tools are general-purpose, because I assume I'll be curious tomorrow about something I didn't care about today. Maybe it's more accurate to say that I tend to build tools to extend my curiosity as much as to satisfy it, or that extending and satisfying describe a propulsive cycle of curiosity more than alternative goals. I would love to inspire this same kind of curiosity in you, but I would settle for giving you some power and letting you discover what you do with it.
And a few days ago it occurred to me that I can. Or, rather, I can give you the power of my knowledge and experience embodied in code, and you can get the power of running it for yourself by signing up for your own API keys. Which is easy and free.
Here's how:
- go to developer.spotify.com
- click "Log in", and log into your regular Spotify account
- click your name in the top right, and pick Dashboard
- read and accept the developer terms of service
- on the Dashboard page, click "Create app" in the top right
-- App name: NRbG
-- App description: New Releases by Genre
-- Website: (leave blank)
-- Redirect URIs: localhost (NRbG doesn't actually use this)
-- [x] Web API (leave the others unchecked)
-- [x] I understand and agree etc.
- click Save
- on your new NRbG app page, click Settings in the top right
- click "View client secret"
- copy your "Client ID" and "Client secret"
- go to NRbG (DIY version)
- paste your client ID and secret into the boxes
- hit Enter
Now you have power.
The new version of NRbG is a little different from the old one. Instead of a list of all the genres in the world, it has a text box. Type a genre name there and hit Enter, and it will start looking for new releases by artists in or around that genre that came out in the last release week (from Saturday through Friday, because Friday is the traditional music-industry release day).
After a while it might start finding some.
The orange letters are the first letters of each song-title, and you can click on them to hear samples. If a new release has songs that already came out some other way, they will (usually) be grayed out here, like with the gray S above for the advance single "Sekuyiso Isikhathi" from THANDAZANI's album Sasibaningi.
If you click "show track URIs", at the bottom, you'll get a list of the URIs for all the new tracks from the releases you have checked in the list, which you can copy and paste into a blank (or existing) Spotify playlist (using command-C, command-V in the Spotify desktop app). There's also a "save playlist" option, which create a new playlist for you directly if you want.
Because I built this for myself, there are a few non-obvious features.
The text box actually takes a list of things, separated by + signs, and the things can each be any of these:
- a genre (e.g. maskandi or gothic symphonic metal)
- a Spotify artist link/URI
- the name of an individual artist, in quotes, like "Nightwish", although this will find the most popular with that name, so URIs are always safer
- a Spotify playlist link/URI, to be interpreted as a list of artists
- @ and then the name of a record label (e.g. @Profound Lore; the spelling has to be exactly right, but see the note later about playlists)
If your list starts with a +, the results will be added to the bottom of the current list; otherwise the current results will be replaced.
The ">>" link encodes your current parameters, so if you click that, you can then bookmark the resulting URL for reuse.
New releases for selected labels, because labels are the only thing that works properly in new-release API searching, are each shown individually, in labeled groups. Everything else in a given list is combined to make a consolidated set of artists, those artists are then checked for their closest related artists (via Fans Also Like), and the whole thus-expanded list of artists is reordered by collective relevance and then checked individually in order for new releases.
If you don't know the exact genre names you want, offhand, you can also just type a partial name and an asterisk, like metal*, and it will give you a list of all the genre names that include that word. Or you could go to everynoise.com and type an artist name into the search box in the top right to see what genres they belong to.
The words "new" and "releases", in "new releases by genre" at the top, are both actually mode controls. "new" switches back and forth between "new", for new-release mode, and "top", for one-top-release-per-artist sampler mode, not constrained by dates. "releases" cycles through "releases" (everything), "albums" (no singles or compilations) and "singles" (no albums or compilations).
If you want to get only 1 track per release, for sampler purposes, you can put "1/" before your list. Or indeed any number and then a "/". This will pick the most popular however-many tracks on each release, and gray out the rest (and exclude them from the URI list) like the non-new tracks on new releases.
You might notice that this app, although it requires your API keys, does not itself log into your Spotify account. This is intentional. Many Spotify features are personalized for you in complicated ways, if you are logged in, and for exploratory purposes we don't want that. This means, too, that this app cannot access or modify your personal information. But if you want to control its behavior by giving it more information, it can look up non-private playlists, so that's the mechanism.
If you use a playlist as input (yours or anybody else's), it will look for new releases by the primary artists of the tracks in that playlist and their related artists, but excluding the specific releases already in the playlist. So if you, like me, spend a lot of time using this tool every Friday to make a playlist of new releases you want to hear, you can put that playlist's URI back into the same tool and it will check to see if there's anything else related that you might have missed.
In addition, once you've set up your API keys and NRbG is working, the playlist-profile page in the everynoise research tools also gets a couple added features for finding new releases. Put a playlist link or URI into that view, and it already shows you genres and record labels for every track in the list. But scroll to the bottom of the page, and you'll also see something like this:
The "see new releases" line gives you three links to NRbG for different ways of expanding on this list, each with a set of parameters pre-filled from the data in this playlist.
And, for one last bonus feature, you can check an earlier week by putting that week's Friday date (in YYYY-MM-DD format) at the beginning of your input as an override, like this:
and hit Enter to get:
You can even check whole years by including just a year, although be warned, in both cases, that release-date data gets unreliable pretty quickly once you go back beyond the very recent past.
I don't know what else I'll do with this. Probably more, because it's fun. Feedback, error reports and ideas are all welcome, in the meantime.
See what you find.
¶ Corners of the world · 25 July 2024 listen/tech
I'm keeping a running list of book-related media links at the bottom of this post, but here are a few new things from an interestingly global week:
- I'm featured in an article about AI and the future in the French magazine Usbek & Rica this month. My copy hasn't arrvied yet, and I think it's in French, so I'm as curious as anybody what I said.
- Iveta Hajdakova and Tom Hoy at the London international consulting group Stripe Partners, who I know from some work they did for Spotify while I was there, interviewed me about algorithms and music for their Viewpoints series.
- There's an interview/feature with/about me and You Have Not Yet Heard Your Favourite Song both in print and online in the Polish magazine Polityka.
- I'll be making my second ever visit to the southern hemisphere, and first to New Zealand and Australia, to appear in conversation at Going Global Music Summit 2024 in Auckland, August 29-30, and then BIGSOUND 2024 in Brisbane, September 2-6!

- I'm featured in an article about AI and the future in the French magazine Usbek & Rica this month. My copy hasn't arrvied yet, and I think it's in French, so I'm as curious as anybody what I said.
- Iveta Hajdakova and Tom Hoy at the London international consulting group Stripe Partners, who I know from some work they did for Spotify while I was there, interviewed me about algorithms and music for their Viewpoints series.
- There's an interview/feature with/about me and You Have Not Yet Heard Your Favourite Song both in print and online in the Polish magazine Polityka.
- I'll be making my second ever visit to the southern hemisphere, and first to New Zealand and Australia, to appear in conversation at Going Global Music Summit 2024 in Auckland, August 29-30, and then BIGSOUND 2024 in Brisbane, September 2-6!
¶ Filter domes, "made for you", and the kind of personalization that even makes personalization worse · 21 June 2024 listen/tech
Filter "bubbles" are charmingly weightless, delightful to pop. Sure, there's a slight soapy residue afterwards, but check your backpack: there are probably still a few old hand-sanitizer packets you shoved in there during the pandemic. Except sometimes you reach out, flirtatiously, to pop the shimmering bubble, and hit an intransigence made of polarized glass. Less bubble, more dome.
Spotify generates a lot of playlists that are "made for you", which generally means they have been aggressively adjusted to prioritize your previous listening. This is excellent for comfort, but terrible for exploration.
For example, Spotify is currently giving me a Synthwave Mix playlist on my Made For You page. I like synthwave, but I haven't been paying much focused attention to it lately, so it would be useful to me to hear what's going on there. "My" Synthwave Mix is made for me, though, so what it suggests is going on in synthwave is a) the handful of synthwave-adjacent bands I already specifically follow, and b) a lot of other bands I also already follow who are very definitely not synthwave.
I have a tool for this, though. If you stick the link to a Spotify made-for-you playlist into this:
https://everynoise.com/playlistprofile.cgi, e.g. Synthwave Mix
you can see what that playlist looks like before it gets personalized. In my case, this is almost completely different from what I end up with; only one artist* from the underlying source playlist ends up in my personalized version. That's not a lot of discovery potential. If there were a product feature to turn off the personalization, at least I could have discovered something here. Agency unlocks curiosity.
But since there are still, for the moment, better tools for genre exploration, I'm content to just ignore almost everything they make for me. In practice there is exactly one personalized Spotify playlist I use: Release Radar. This one is different because you actually do have some control over it, albeit not in a way that is totally apparent from looking at it. Release Radar will do its own inscrutable magic for you if you let it, but first it will find you new releases by artists you Follow. So if you follow enough artists, you can crowd out the "suggestions" and get a very useful release monitor. I follow 5124 artists, but you probably don't have to be that obsessive if you aren't me. Release Radar maxes out at 200 tracks. Even with 5124 artists to monitor, there are usually not more than 200 of them with new releases in any given week, so this is OK-ish. If you aren't me it's probably way more than enough.
In weeks when there are fewer than 200 new releases by artists I follow, Release Radar will fill out the rest of the 200 tracks with releases from the previous 3 weeks. This is an earnest idea, but counter-productive for me, personally, because I monitor new releases every week and I don't want to have the old tracks shown to me again as if they are new. So I generally stick my Release Radar playlist into the same playlist viewer linked above, where I can see the release dates of the tracks, and extract just the ones from the current week into a new playlist.
I usually do this first, and only really look at the new tracks once they're in the new playlist. This morning I went for a run before I'd done this, so I just put on Release Radar itself. The older tracks come at the end, and I wasn't going to be out for 12 hours, so it didn't matter. Later when I went to make my new-songs-only copy, though, I noticed that the first few tracks in my no-personalization viewer were not the same ones I had just heard. Weird. Flipping back and forth between the two views, it was clear that they were very different. Every Release Radar is unique, so my Release Radar is already filled with my artists, and thus you might think that this is the one time when "made for you" can't do any harm.
But oh, wait. Those older songs. Ugh.
Release Radar actually does assemble the list of new songs by artists I follow, like it's meant to. The pre-personalization view shows that this week 199 of my artists had new releases; only the 200th song in the underlying list is filler from a previous week. But then the made for you filter-dome snaps down, and songs I want to hear from this week are obtusely replaced with older songs by artists Spotify thinks are more familiar to me. Which are exactly the songs I am most likely to already have contemplated in the weeks when they were new. Two algorithms later, I end up with only 79 of the 199 new songs the first algorithm had in mind for me. "Catch all the latest music from artists you follow", Release Radar promises at the top. That's exactly what I want, and exactly what it could give me if it wanted to.
Algorithms, though, don't want things. We want things, and the algorithms do what they are ordered to do. I want all the latest music I might care about. Somebody who still works for Spotify wants something else. If you aren't me, maybe it still doesn't matter. If you only care about a few artists, you won't have this problem. If a streaming service only cares about people who only care about a few artists, they won't fix it**. If they don't employ enough people who care about everything, they may not even know. Maybe what they really want is to not have to care or know, and they have a comfort metric that allows them not to.
But all of this, the domes and the not caring and the not knowing, makes the world worse. I don't want to miss joy in favor of somebody else's obliviously generalized idea of my comfort. Neither should any of us.
* The one artist isn't even actually a synthwave artist. You can't really blame Spotify for that, though, as it's hardly their business to know the internal jargon of zero-cost content makers.
** One might reasonably ask why, given that I no longer work for Spotify, I haven't switched to some other streaming service, and the answer is that whatever they do or don't fix in the app, they still have the most useful programmatic API. That's how the playlist viewer works, and if you want new releases by all the artists you follow bad enough to write code, you can have that, too. And if you're me, now you do. One playlist minus one is zero. Ultimately the only person in "personalization" is the one doing it, and if you want your personalization to be personal, that person has to be you.
[23 August 2024 update: this week the post-processing reduces the underlying 200 songs in my Release Radar to just 30. That's pathetic.]
Spotify generates a lot of playlists that are "made for you", which generally means they have been aggressively adjusted to prioritize your previous listening. This is excellent for comfort, but terrible for exploration.
For example, Spotify is currently giving me a Synthwave Mix playlist on my Made For You page. I like synthwave, but I haven't been paying much focused attention to it lately, so it would be useful to me to hear what's going on there. "My" Synthwave Mix is made for me, though, so what it suggests is going on in synthwave is a) the handful of synthwave-adjacent bands I already specifically follow, and b) a lot of other bands I also already follow who are very definitely not synthwave.
I have a tool for this, though. If you stick the link to a Spotify made-for-you playlist into this:
https://everynoise.com/playlistprofile.cgi, e.g. Synthwave Mix
you can see what that playlist looks like before it gets personalized. In my case, this is almost completely different from what I end up with; only one artist* from the underlying source playlist ends up in my personalized version. That's not a lot of discovery potential. If there were a product feature to turn off the personalization, at least I could have discovered something here. Agency unlocks curiosity.
But since there are still, for the moment, better tools for genre exploration, I'm content to just ignore almost everything they make for me. In practice there is exactly one personalized Spotify playlist I use: Release Radar. This one is different because you actually do have some control over it, albeit not in a way that is totally apparent from looking at it. Release Radar will do its own inscrutable magic for you if you let it, but first it will find you new releases by artists you Follow. So if you follow enough artists, you can crowd out the "suggestions" and get a very useful release monitor. I follow 5124 artists, but you probably don't have to be that obsessive if you aren't me. Release Radar maxes out at 200 tracks. Even with 5124 artists to monitor, there are usually not more than 200 of them with new releases in any given week, so this is OK-ish. If you aren't me it's probably way more than enough.
In weeks when there are fewer than 200 new releases by artists I follow, Release Radar will fill out the rest of the 200 tracks with releases from the previous 3 weeks. This is an earnest idea, but counter-productive for me, personally, because I monitor new releases every week and I don't want to have the old tracks shown to me again as if they are new. So I generally stick my Release Radar playlist into the same playlist viewer linked above, where I can see the release dates of the tracks, and extract just the ones from the current week into a new playlist.
I usually do this first, and only really look at the new tracks once they're in the new playlist. This morning I went for a run before I'd done this, so I just put on Release Radar itself. The older tracks come at the end, and I wasn't going to be out for 12 hours, so it didn't matter. Later when I went to make my new-songs-only copy, though, I noticed that the first few tracks in my no-personalization viewer were not the same ones I had just heard. Weird. Flipping back and forth between the two views, it was clear that they were very different. Every Release Radar is unique, so my Release Radar is already filled with my artists, and thus you might think that this is the one time when "made for you" can't do any harm.
But oh, wait. Those older songs. Ugh.
Release Radar actually does assemble the list of new songs by artists I follow, like it's meant to. The pre-personalization view shows that this week 199 of my artists had new releases; only the 200th song in the underlying list is filler from a previous week. But then the made for you filter-dome snaps down, and songs I want to hear from this week are obtusely replaced with older songs by artists Spotify thinks are more familiar to me. Which are exactly the songs I am most likely to already have contemplated in the weeks when they were new. Two algorithms later, I end up with only 79 of the 199 new songs the first algorithm had in mind for me. "Catch all the latest music from artists you follow", Release Radar promises at the top. That's exactly what I want, and exactly what it could give me if it wanted to.
Algorithms, though, don't want things. We want things, and the algorithms do what they are ordered to do. I want all the latest music I might care about. Somebody who still works for Spotify wants something else. If you aren't me, maybe it still doesn't matter. If you only care about a few artists, you won't have this problem. If a streaming service only cares about people who only care about a few artists, they won't fix it**. If they don't employ enough people who care about everything, they may not even know. Maybe what they really want is to not have to care or know, and they have a comfort metric that allows them not to.
But all of this, the domes and the not caring and the not knowing, makes the world worse. I don't want to miss joy in favor of somebody else's obliviously generalized idea of my comfort. Neither should any of us.
* The one artist isn't even actually a synthwave artist. You can't really blame Spotify for that, though, as it's hardly their business to know the internal jargon of zero-cost content makers.
** One might reasonably ask why, given that I no longer work for Spotify, I haven't switched to some other streaming service, and the answer is that whatever they do or don't fix in the app, they still have the most useful programmatic API. That's how the playlist viewer works, and if you want new releases by all the artists you follow bad enough to write code, you can have that, too. And if you're me, now you do. One playlist minus one is zero. Ultimately the only person in "personalization" is the one doing it, and if you want your personalization to be personal, that person has to be you.
[23 August 2024 update: this week the post-processing reduces the underlying 200 songs in my Release Radar to just 30. That's pathetic.]
¶ You Have Not Yet Read Your Favourite Book · 20 June 2024 listen/tech
It's probably not the one I wrote. It would be weird if my book were your favorite book. It's a geeky book about music-streaming and music and algorithms and technology and curiosity and morality and where we are right now, and your favorite book should probably be an immortal novel about how we always are, or something you have re-read every year since you were 12 because it reminds you what you love and believe.
But my book about how streaming changes music is also kind of a book about loving and believing things, and the fears and joys that love and belief produce, because everything is if you really think about it, and I wrote a book about this stuff because I really think about it and didn't know how to stop.
As a method of not thinking about something any more, writing the book seems to have been fairly ineffective. I have kept thinking and writing about music and algorithms and technology and humanity. My new job, which doesn't have music anywhere in the wording of the mission, is just as fundamentally about figuring out how to use math and machines to amplify humanity instead of phase-cancelling it.
As an organized explanation of why I think streaming is good for music and music-streaming is good for humanity, though, I made it as coherent as I could. (And then a really good editor goaded me methodically into making it more coherent than that.) If you love music, you might like reading this book while you listen to whatever you are currently discovering or wondering or doubting. It's a book about discovery and wonder and productive doubt.
And it was officially published today.
You Have Not Yet Heard Your Favourite Song; Canbury Press, 2024.
US: bookshop.org or amazon.com or kindle
UK: uk.bookshop.org or amazon.co.uk or kindle UK
France (French): Hachette/Editions Marabout or Amazon.fr, September 2024
Taiwan (Chinese): ECUS Publishing House, December 2024
India (English): The Bombay Circle Press, December 2024
In London: Waterstones or Blackwells or Foyles
In Montreal: featured at Librairie Résonance

Some related links as I notice them:
2025
- One of Mixmag Asia's Six books on how streaming has forever changed our relationship with music, April 23
- A piece about the book in the Czech edition of Wired, February 4
2024
- A terrific review from book_click_deo on Instagram, December 23
- An interview for Fohlapress (or here) in Brazil, December 18
- An appearance on Bob Shami's Soundbreaker podcast, published December 12
- An interview in WNYU's STATIC magazine, December 7
- The Chinese and Indian editions are both out now, December 4
- The Chinese edition is coming! November 23
- Is this the 37th best book of 2024? An audacious claim from the Telegraph, November 17
- Read all the way to the end of this roundup of the best music books of 2024 in the Telegraph for a reminder that my book is optimistic and optimism is good, November 9
- The book and I feature in this Ars Technica story about a wave of junk music with real-artist names on Spotify, October 15
- An interview in the Chartmetric blog How Music Charts, October 9
- A review in The Quietus, September 28
- Carl Wilson and I talk about my book for the Popular Music Books in Process series, September 24
- A whole bonus episode of Your Morning Coffee Podcast, August 30.
- An appearance on the NZ podcast The Fold, August 28
- A article based on an interview with Radio New Zealand in advance of appearing at Going Global, August 28
- A mention on Your Morning Coffee Podcast, August 19 (from about 7:40-10:20) teasing an upcoming special episode with me
- A (second) appearance on Your Morning Coffee Podcast, August 5 (from about 19:09-27:45)
- An interview/feature in the Polish magazine Polityka, July 27
- An interview with Tom and Iveta at Stripe Partners for their Viewpoints series, July 25
- A book citation as part of my introduction into a story about algorithms and music discovery in Mission magazine, July 17 (with the excellent pull-quote "If you don’t want algorithms to feed you passive listening, get active.")
- A conversation with Mark Richardson for the Third Bridge Creative blog, July 9
- A print rendition of the interview from the earlier German radio piece in Die Tageszeitung, July 4
- A conversation with Walt Hickey on the Numlock Sunday podcast, June 30
- An appearance on The Ray D'Arcy Show on RTE Radio 1 Ireland, June 25 (from about 26:10-50:37; clip)
- An interview in the Dutch newsletter Weekly Wav, June 25
- An appearance on Your Morning Coffee Podcast, June 24 (from about 7:00-18:00)
- A conversation on the podcast The Gist, June 20
- A short interview on Newstalk in Ireland, June 19 (with a Cactus World News shout!)
- A radio piece in German on Deutschlandfunk Kultur, June 19 (with blasts of gothic metal and wisps of theremin!)
- A "new book" mention on Tinnitist, June 16
- A review in the Telegraph, June 4; also available via Yahoo News
- A conversation with Chris Dalla Riva in his newsletter Can't Get Much Higher, May 26
- An earlier appearance on Ari Herstand's The New Music Business podcast, April 10, with some book-anticipation towards the end
- The book's page on Goodreads



But my book about how streaming changes music is also kind of a book about loving and believing things, and the fears and joys that love and belief produce, because everything is if you really think about it, and I wrote a book about this stuff because I really think about it and didn't know how to stop.
As a method of not thinking about something any more, writing the book seems to have been fairly ineffective. I have kept thinking and writing about music and algorithms and technology and humanity. My new job, which doesn't have music anywhere in the wording of the mission, is just as fundamentally about figuring out how to use math and machines to amplify humanity instead of phase-cancelling it.
As an organized explanation of why I think streaming is good for music and music-streaming is good for humanity, though, I made it as coherent as I could. (And then a really good editor goaded me methodically into making it more coherent than that.) If you love music, you might like reading this book while you listen to whatever you are currently discovering or wondering or doubting. It's a book about discovery and wonder and productive doubt.
And it was officially published today.
You Have Not Yet Heard Your Favourite Song; Canbury Press, 2024.
US: bookshop.org or amazon.com or kindle
UK: uk.bookshop.org or amazon.co.uk or kindle UK
France (French): Hachette/Editions Marabout or Amazon.fr, September 2024
Taiwan (Chinese): ECUS Publishing House, December 2024
India (English): The Bombay Circle Press, December 2024
In London: Waterstones or Blackwells or Foyles
In Montreal: featured at Librairie Résonance
Some related links as I notice them:
2025
- One of Mixmag Asia's Six books on how streaming has forever changed our relationship with music, April 23
- A piece about the book in the Czech edition of Wired, February 4
2024
- A terrific review from book_click_deo on Instagram, December 23
- An interview for Fohlapress (or here) in Brazil, December 18
- An appearance on Bob Shami's Soundbreaker podcast, published December 12
- An interview in WNYU's STATIC magazine, December 7
- The Chinese and Indian editions are both out now, December 4
- The Chinese edition is coming! November 23
- Is this the 37th best book of 2024? An audacious claim from the Telegraph, November 17
- Read all the way to the end of this roundup of the best music books of 2024 in the Telegraph for a reminder that my book is optimistic and optimism is good, November 9
- The book and I feature in this Ars Technica story about a wave of junk music with real-artist names on Spotify, October 15
- An interview in the Chartmetric blog How Music Charts, October 9
- A review in The Quietus, September 28
- Carl Wilson and I talk about my book for the Popular Music Books in Process series, September 24
- A whole bonus episode of Your Morning Coffee Podcast, August 30.
- An appearance on the NZ podcast The Fold, August 28
- A article based on an interview with Radio New Zealand in advance of appearing at Going Global, August 28
- A mention on Your Morning Coffee Podcast, August 19 (from about 7:40-10:20) teasing an upcoming special episode with me
- A (second) appearance on Your Morning Coffee Podcast, August 5 (from about 19:09-27:45)
- An interview/feature in the Polish magazine Polityka, July 27
- An interview with Tom and Iveta at Stripe Partners for their Viewpoints series, July 25
- A book citation as part of my introduction into a story about algorithms and music discovery in Mission magazine, July 17 (with the excellent pull-quote "If you don’t want algorithms to feed you passive listening, get active.")
- A conversation with Mark Richardson for the Third Bridge Creative blog, July 9
- A print rendition of the interview from the earlier German radio piece in Die Tageszeitung, July 4
- A conversation with Walt Hickey on the Numlock Sunday podcast, June 30
- An appearance on The Ray D'Arcy Show on RTE Radio 1 Ireland, June 25 (from about 26:10-50:37; clip)
- An interview in the Dutch newsletter Weekly Wav, June 25
- An appearance on Your Morning Coffee Podcast, June 24 (from about 7:00-18:00)
- A conversation on the podcast The Gist, June 20
- A short interview on Newstalk in Ireland, June 19 (with a Cactus World News shout!)
- A radio piece in German on Deutschlandfunk Kultur, June 19 (with blasts of gothic metal and wisps of theremin!)
- A "new book" mention on Tinnitist, June 16
- A review in the Telegraph, June 4; also available via Yahoo News
- A conversation with Chris Dalla Riva in his newsletter Can't Get Much Higher, May 26
- An earlier appearance on Ari Herstand's The New Music Business podcast, April 10, with some book-anticipation towards the end
- The book's page on Goodreads
¶ 10 aspirational rules for the moral operation of a music service · 4 June 2024 listen/tech
- The technical goal is to organize music so it is explorable. Exploration rewards curiosity.
- The product goal is to help listeners find joy. Joy is various.
- The feature goal is to connect individuals to communities. Music is a social energy.
- The business goal is to make money for artists. Not from.
- There should be one reward system, consistently applied. All financial contracts should be public.
- Listeners are entitled to their own data. Their stories, their love.
- Artists are entitled to their own data. Their audiences, their work.
- People are collectively entitled to their collective knowledge. Coherences, congruences.
- Musical taste and preference are emergent transiences of humans, yearned after by empathetic systems. Not imperious instruments of control.
- Never refer to music as “content”, even to yourself.
¶ Lotteries We All Lose · 11 February 2024 listen/tech
The systemic moral imperative seeks the distribution of power over its concentration, and thus the reduction of inequities of power. Money is usually a good proxy for power, so it's tempting to regard any redirection of money to the preexistingly unwealthy as moral. But this is both a dangerous conflation of cause and effect, and an attractive nuisance of potentially misleading measurement.
In fact, the most common nominal redistributions of money in a functionally self-defending power-structure are likely to be ones that specifically do not meaningfully distribute power. Capitalism's idea of charity is billionaires bestowing heroically magnanimous gifts. The recipients of this benevolence do benefit from it, but they do not generally become independently powerful themselves as result. And one of capitalism's favorites forms of structural redistributions of money is the lottery. Lotteries, by which I mean all general systems that assign selective benefits to a minority of the disempowered via processes that are either literally random or effectively random because they are out of the recipients' control, transfer money without conferring agency. Government lotteries usually compound this flaw by appealing to the disempowered and thus acting as a regressive tax, as well.
Jackpot-weighted lotteries, like Mega Millions and Powerball, have one more trick, which is that their biggest prizes can only be portrayed as redirecting money to the unwealthy by disingenuously selective definitions. Any individual jackpot winner is almost certain to have been among the unwealthy before their windfall, so any economic metrics that attribute the win to the collective unwealthy will look superficially progressive. But of course the actual effect is that the winner is moved from the category of the unwealthy to the ranks of the wealthy, at least nominally. The collective state of the unwealthy is unchanged. The power of billionaires is not threatened by the annointment of one more, particularly if the new one gets money without any of the other entitlements that usually help the rich stay rich, and is thus likely to either fall back out of the category of the wealthy by their own mismanagement, or at least spend their money on predictable signifiers of wealth and thus offer no systemic disruption.
A lottery is an algorithm, and of course the same moral calculus applies to all algorithms, particularly ones that operate directly as social or cultural systems. A music-recommendation algorithm is systemically moral if it reduces inequities of power among listeners and artists. Disproportionately concentrating streams among the most popular artists is straightforwardly regressive, but distributing streams to less popular artists is not itself necessarily progressive. A morally progressive algorithm distributes agency: it gives listeners more control, or it encourages and facilitates their curiosity; it helps artists find and build community and thus career sustainability. Holistically, it rewards cultural validation, and thus shifts systemic effects from privilege and lotteries towards accessibility and meritocracies.
The algorithms I wrote to generate playlists for the genre system I used to run at Spotify were not explicitly conceived as moral machines, but they inevitably expressed things I believed by virtue of my involvement, and thus were sometimes part of how I came to understand aspects of my own beliefs. They were proximally motivated by curiosity, but curiosity encodes an underlying faith in the distribution of value, so systems designed to reflect and magnify curiosity will tend towards decentralization, towards resistance against the gravity of power even if they aren't consciously counterposed, ideologically, against the power itself. The premise of the genre system was that genres are communities, and so most of its algorithms tried to use fairly simple math to capture the collective tastes of particular communities of music fans.
The algorithm for generating 2023 in Maskandi, for example, compared the listening of Maskandi fans to global totals in order to find the new 2023 songs that were most disproportionately played by those people.

Or, to phrase this from the world into streaming data, rather than vice versa, there is a thing in the world called Maskandi, a fabulously fluttery and buoyant Zulu folk-pop style, and there is an audience of people for whom that is what they mean when they say "music", and their collective listening contains culturally unique collective knowledge. Using math to collate that collective knowledge can allow us to discover the self-organization of music that it represents. If we do this right, we do not need to rely on individual experts approximating collective love with subjective opinions. If we do this right, we support a real human community's self-awareness and power of identity in a way that it cannot easily support itself. There's no magic source of truth about what "right" consists of, which is the challenge of the exercise but also exactly why it's worthwhile to attempt. For 12 years I spent most of my work life devising algorithms like this, running them, learning how to cross-check the cultural implications of the results, and then iterating in search of more and better revealed wisdom.
In general, I found that collective listening knowledge is not especially elusive or cryptic. Streaming is not inherently performative, so most people listen in ways that seem likely to be earnest expressions of their love. That love can be collated with very simple math. Simple math that produces specific results is good because it's easy to adjust and evaluate. You might argue, I suppose, that simple math, by virtue of its simplicity, does not establish competitive advantages. If music services all have the same music, and music players all have the same basic controls, then services are differentiated by their algorithms, and more complex algorithms are harder for competitors to replicate.
I offer, conversely, the rueful observation that in the last 12 years no other major music service has developed a cultural taxonomy of even remotely the same scale as the genre system we built at the Echo Nest and Spotify, while all of them have implemented versions of opaque personalization based on machine learning. ML recommendations are an arms-race with only temporary advantages. The machines don't actually learn, they always start over from nothing. ML engineers, too, can be trained from nothing or bought from other industries, without needing special love. But machines that do not run on love will not produce it.
In particular, ML algorithms tend to drift towards lottery effects. Vector embeddings, even if they are trained on human cultural input like playlist co-occurence, tend to introduce non-cultural computational artifacts by their nature. And thus we get things like this set of music my Spotify daylist recently gave me:

You don't need to hear the music behind these images to guess that it's mostly aggressive metalcore, but if you happen to know a lot about metalcore you could also notice that you probably have not heard of most of these bands. I am not a big fan of this very specific niche of metal, personally, which is the first thing wrong with this set as a personalized result for me. Bad results aren't disturbing because they're bad. Algorithms don't always work, for many reasons.
But as I scanned through these songs, I couldn't help noticing that they all sounded very similar. And as I poked through the artist links, trying to understand what this set of bands represents, I quickly realized that it doesn't. These bands are not all from any one place, they do not appear together on any particular playlists, their fans do not also like each other. They are not collectively part of a real-world community. Many of them have fewer than 100 monthly listeners, sometimes a lot fewer, and thus probably do not even individually represent real-world communities. They do appear to be real bands, rather than opportunistic constructs or AI interpolations, and in general they aren't bad examples of this kind of thing.
But they didn't end up on my list by merit or effort. They ended up here because Spotify uses ML techniques to group songs by acoustic characteristics, and this is one of the inputs into the vector embeddings that produce recommendations for daylist, Discover Weekly and other ML-driven personalized playlists. Acoustic similarity isn't completely random on the level of Powerball, but it's not a cultural meritocracy, and it's not a model for giving artists or listeners agency. Picking unknown artists out of the vast unheard tiers of streaming music is not an act of cultural incubation or stewardship, it's a mechanism of control. There are thousands of bands who sound like this. If you are one of the almost-thousands who are not randomly on my list, there's no action you can take to change this. If any one band ever gets famous this way, and statistically this is bound to happen rarely but eventually, you can be pretty sure we'll hear about it in self-congratulatory press releases that do not feature everyone else left behind. One exception doesn't change the rules. Lottery exposure offers a fleeting illusion of access, but if you didn't build it, you can't sustain it, either. You might hope, if you are in one of these lucky bands that reached me, that millions of not quite metalcore fans also got sets like this on a Friday afternoon, but two Friday afternoons later these bands are still obscure, still isolated. Losing lottery tickets do not make you luckier, but worse, lucking into more listeners this way doesn't give you an audience with any unifying rationale or presence, or a community to join. You can't learn from randomness, you can only hold still and hope it somehow picks you again.
This is exactly what the power-structure wants: listeners holding still to see what daylist tells them to listen to on Friday afternoon, artists holding still hoping to be chosen. Measure this control by money and it looks virtuous, taking a few streams from the most saturated songs and sprinkling them sparingly across the thirstiest. Measure it by alleviated thirst, though, and it evaporates. Or, rather, it condenses, but only into the reservoirs of the machine itself. Audit the beneficiaries and you might find that they aren't even random. ML's idea of the distribution of power is enough unpredictability to distract from its own motivations. My idea of the future of music is not a chaos engine printing rigged lottery tickets that mostly don't even pay for themselves. It's a future that we build. It's a future we could build faster with better tools, and algorithms can be those tools. But only if they are handed to us, with intelligible instructions, as we are in productive motion. Only if they are designed not to give us each little jolts of seemingly new power for which we can yearn, but to give all of us, together, currents of shared power with which our yearning can be expressed and redeemed.
In fact, the most common nominal redistributions of money in a functionally self-defending power-structure are likely to be ones that specifically do not meaningfully distribute power. Capitalism's idea of charity is billionaires bestowing heroically magnanimous gifts. The recipients of this benevolence do benefit from it, but they do not generally become independently powerful themselves as result. And one of capitalism's favorites forms of structural redistributions of money is the lottery. Lotteries, by which I mean all general systems that assign selective benefits to a minority of the disempowered via processes that are either literally random or effectively random because they are out of the recipients' control, transfer money without conferring agency. Government lotteries usually compound this flaw by appealing to the disempowered and thus acting as a regressive tax, as well.
Jackpot-weighted lotteries, like Mega Millions and Powerball, have one more trick, which is that their biggest prizes can only be portrayed as redirecting money to the unwealthy by disingenuously selective definitions. Any individual jackpot winner is almost certain to have been among the unwealthy before their windfall, so any economic metrics that attribute the win to the collective unwealthy will look superficially progressive. But of course the actual effect is that the winner is moved from the category of the unwealthy to the ranks of the wealthy, at least nominally. The collective state of the unwealthy is unchanged. The power of billionaires is not threatened by the annointment of one more, particularly if the new one gets money without any of the other entitlements that usually help the rich stay rich, and is thus likely to either fall back out of the category of the wealthy by their own mismanagement, or at least spend their money on predictable signifiers of wealth and thus offer no systemic disruption.
A lottery is an algorithm, and of course the same moral calculus applies to all algorithms, particularly ones that operate directly as social or cultural systems. A music-recommendation algorithm is systemically moral if it reduces inequities of power among listeners and artists. Disproportionately concentrating streams among the most popular artists is straightforwardly regressive, but distributing streams to less popular artists is not itself necessarily progressive. A morally progressive algorithm distributes agency: it gives listeners more control, or it encourages and facilitates their curiosity; it helps artists find and build community and thus career sustainability. Holistically, it rewards cultural validation, and thus shifts systemic effects from privilege and lotteries towards accessibility and meritocracies.
The algorithms I wrote to generate playlists for the genre system I used to run at Spotify were not explicitly conceived as moral machines, but they inevitably expressed things I believed by virtue of my involvement, and thus were sometimes part of how I came to understand aspects of my own beliefs. They were proximally motivated by curiosity, but curiosity encodes an underlying faith in the distribution of value, so systems designed to reflect and magnify curiosity will tend towards decentralization, towards resistance against the gravity of power even if they aren't consciously counterposed, ideologically, against the power itself. The premise of the genre system was that genres are communities, and so most of its algorithms tried to use fairly simple math to capture the collective tastes of particular communities of music fans.
The algorithm for generating 2023 in Maskandi, for example, compared the listening of Maskandi fans to global totals in order to find the new 2023 songs that were most disproportionately played by those people.
Or, to phrase this from the world into streaming data, rather than vice versa, there is a thing in the world called Maskandi, a fabulously fluttery and buoyant Zulu folk-pop style, and there is an audience of people for whom that is what they mean when they say "music", and their collective listening contains culturally unique collective knowledge. Using math to collate that collective knowledge can allow us to discover the self-organization of music that it represents. If we do this right, we do not need to rely on individual experts approximating collective love with subjective opinions. If we do this right, we support a real human community's self-awareness and power of identity in a way that it cannot easily support itself. There's no magic source of truth about what "right" consists of, which is the challenge of the exercise but also exactly why it's worthwhile to attempt. For 12 years I spent most of my work life devising algorithms like this, running them, learning how to cross-check the cultural implications of the results, and then iterating in search of more and better revealed wisdom.
In general, I found that collective listening knowledge is not especially elusive or cryptic. Streaming is not inherently performative, so most people listen in ways that seem likely to be earnest expressions of their love. That love can be collated with very simple math. Simple math that produces specific results is good because it's easy to adjust and evaluate. You might argue, I suppose, that simple math, by virtue of its simplicity, does not establish competitive advantages. If music services all have the same music, and music players all have the same basic controls, then services are differentiated by their algorithms, and more complex algorithms are harder for competitors to replicate.
I offer, conversely, the rueful observation that in the last 12 years no other major music service has developed a cultural taxonomy of even remotely the same scale as the genre system we built at the Echo Nest and Spotify, while all of them have implemented versions of opaque personalization based on machine learning. ML recommendations are an arms-race with only temporary advantages. The machines don't actually learn, they always start over from nothing. ML engineers, too, can be trained from nothing or bought from other industries, without needing special love. But machines that do not run on love will not produce it.
In particular, ML algorithms tend to drift towards lottery effects. Vector embeddings, even if they are trained on human cultural input like playlist co-occurence, tend to introduce non-cultural computational artifacts by their nature. And thus we get things like this set of music my Spotify daylist recently gave me:
You don't need to hear the music behind these images to guess that it's mostly aggressive metalcore, but if you happen to know a lot about metalcore you could also notice that you probably have not heard of most of these bands. I am not a big fan of this very specific niche of metal, personally, which is the first thing wrong with this set as a personalized result for me. Bad results aren't disturbing because they're bad. Algorithms don't always work, for many reasons.
But as I scanned through these songs, I couldn't help noticing that they all sounded very similar. And as I poked through the artist links, trying to understand what this set of bands represents, I quickly realized that it doesn't. These bands are not all from any one place, they do not appear together on any particular playlists, their fans do not also like each other. They are not collectively part of a real-world community. Many of them have fewer than 100 monthly listeners, sometimes a lot fewer, and thus probably do not even individually represent real-world communities. They do appear to be real bands, rather than opportunistic constructs or AI interpolations, and in general they aren't bad examples of this kind of thing.
But they didn't end up on my list by merit or effort. They ended up here because Spotify uses ML techniques to group songs by acoustic characteristics, and this is one of the inputs into the vector embeddings that produce recommendations for daylist, Discover Weekly and other ML-driven personalized playlists. Acoustic similarity isn't completely random on the level of Powerball, but it's not a cultural meritocracy, and it's not a model for giving artists or listeners agency. Picking unknown artists out of the vast unheard tiers of streaming music is not an act of cultural incubation or stewardship, it's a mechanism of control. There are thousands of bands who sound like this. If you are one of the almost-thousands who are not randomly on my list, there's no action you can take to change this. If any one band ever gets famous this way, and statistically this is bound to happen rarely but eventually, you can be pretty sure we'll hear about it in self-congratulatory press releases that do not feature everyone else left behind. One exception doesn't change the rules. Lottery exposure offers a fleeting illusion of access, but if you didn't build it, you can't sustain it, either. You might hope, if you are in one of these lucky bands that reached me, that millions of not quite metalcore fans also got sets like this on a Friday afternoon, but two Friday afternoons later these bands are still obscure, still isolated. Losing lottery tickets do not make you luckier, but worse, lucking into more listeners this way doesn't give you an audience with any unifying rationale or presence, or a community to join. You can't learn from randomness, you can only hold still and hope it somehow picks you again.
This is exactly what the power-structure wants: listeners holding still to see what daylist tells them to listen to on Friday afternoon, artists holding still hoping to be chosen. Measure this control by money and it looks virtuous, taking a few streams from the most saturated songs and sprinkling them sparingly across the thirstiest. Measure it by alleviated thirst, though, and it evaporates. Or, rather, it condenses, but only into the reservoirs of the machine itself. Audit the beneficiaries and you might find that they aren't even random. ML's idea of the distribution of power is enough unpredictability to distract from its own motivations. My idea of the future of music is not a chaos engine printing rigged lottery tickets that mostly don't even pay for themselves. It's a future that we build. It's a future we could build faster with better tools, and algorithms can be those tools. But only if they are handed to us, with intelligible instructions, as we are in productive motion. Only if they are designed not to give us each little jolts of seemingly new power for which we can yearn, but to give all of us, together, currents of shared power with which our yearning can be expressed and redeemed.
¶ Algorithms and Humility (and All the Days the Music Doesn't Die) · 3 February 2024 listen/tech
When you go to an artist's page on Spotify, there's a big Play button at the top. This seems reasonable enough. Playing their music isn't necessarily what you want to do, but it's one of the most likely things. What does it mean, exactly, to "Play an artist", as opposed to playing a particular release? Hit the button and pay attention to the track-sequence you get, and you can quickly figure out what Spotify has chosen to make it do, which is that it plays the artist's 10 Popular tracks in descending popularity order. After that it gets a tiny bit trickier to follow, because it goes through the artist's releases, and those releases are listed right there on the artist page, but the playback order usually doesn't match the display order. But poke around and you'll find that the playback order matches the Discography order (what you get to via the "Show all" link next to the list of "Popular releases"), which is reverse-chronological in principle, although release-dates are a contentious data-field so good luck with that.
This is reasonable behavior, not least because it's explainable, but it's not always the greatest listening experience. What you probably want, I think, if you just hit Play without picking your own starting point, is a sampler of the artist's songs. Their 10 most popular songs are a subset, but not always a great sample. They might all come from the same album, they might include multiple versions of the same song, they might include intros or interstitial tracks that don't actually make sense on their own. And a reverse-chron trudge through literally all the artist's releases, after those first 10 popular tracks, is not a "sample" at all.
This bothered me, so at one point pretty early in my long time at Spotify I spent a little while seeing if I could devise an algorithm to create a better sample-order. It wasn't especially complicated, but it tried to diversify the selection by album, and to group song-versions in order to understand singles as part of their album's eras, and not play the same real-world song over and over due to minor variations. It rarely produced the same summary of an artist's career that a knowledgeable human fan would have, because it didn't have any real cultural insight to work with, but it did a decently non-idiotic job for most artists. I felt pretty good about claiming that it was a better default introduction to an artist than playing the 10 most popular tracks and then every single release.
That wasn't what we ended up doing with the idea, though. Invisible improvements are unglamorous. Instead, it became A Product. That product was the "This Is" artist-playlist series. And because Products make Claims, this new playlist series got an ambitious tagline: "This is [artist name]. The essential tracks, all in one playlist."
Here, apropos of today's anniversary of The Big Bopper's untimely death, is the contents of This Is The Big Bopper:
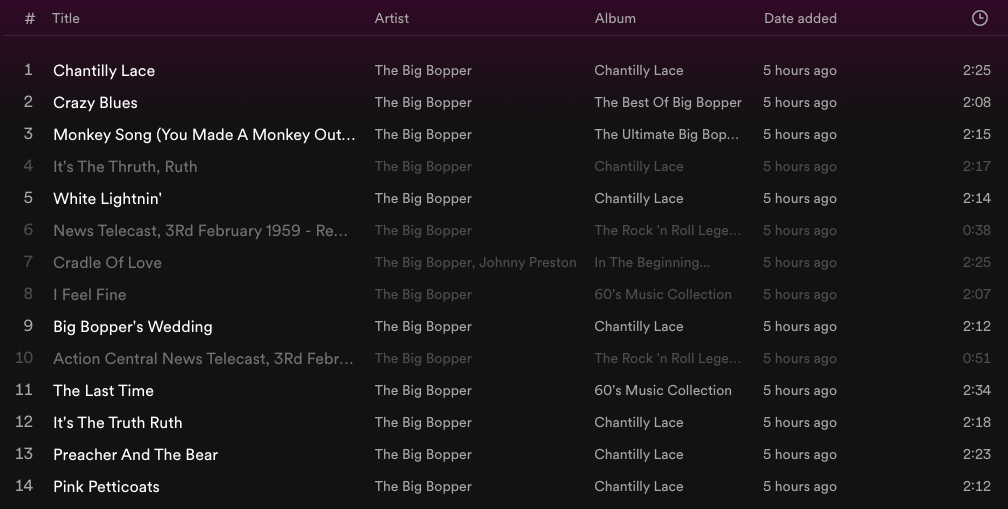
You can see, I think, that the execution has not quite lived up to the premise. The algorithm has done its best to vary the order of nominal source albums, but The Big Bopper didn't make any albums while he was alive, so all of these are actually posthumous compilations. He didn't record very much, period, so in an attempt to make a playlist that isn't just his two hits, the rules have picked a bunch of tracks that aren't even available for streaming, including a couple of sub-1:00 news clips that we are probably happy to be forced to skip, and a very dubiously misspelled "It's the Thruth, Ruth" that probably shouldn't have been released in the first place. But even without those, it makes little musical sense to describe this set as "all the essential tracks". Most of these are no more "essential" than the others, and the official a-side of his first single, "Purple People Eater Meets the Witch Doctor" ("Chantilly Lace" was the nominal b-side of this), is missing.
As an unseen track-order for a sampler, though, this isn't terrible. It improves on the default play-button behavior by not playing the same songs 3 or 4 times each, at least. I'm pretty sure my original version of this algorithm had a duration-filter that would have eliminated the news clips, and an availability filter that would have blocked the Thruth. The algorithm, itself, was a small useful thing that improved the world a little bit. That's all, as its author, I ever claimed about it.
The claims we make, about our algorithms, are a different thing from what they are. I was not in charge of the claims Spotify ended up attaching to this one. I believe that algorithmic intermediation of culture should be done with relentless humility and care. This is not the attitude generally adopted by tech-product marketing. "All the essential tracks" is a more compelling premise than "a slightly better sample-order", for sure. I wouldn't have used it, because the algorithm doesn't deliver it. Marketing doesn't care.
Does it matter? In this case, maybe it doesn't matter a lot. In truth there's probably only one "essential" Big Bopper song, and it's "American Pie". You've achieved a minimally acceptable cultural literacy if you know what Don McLean's memorial is about, and extra credit if you can hum "La Bamba" and any Buddy Holly song that isn't actually by Weezer. The Big Bopper is, sadly, a lot more famous for dying in a plane crash than he is for anything he sang. If you hit his Play button and get "Chantilly Lace", that's already more than most people know.
The This Is series has gone on to be pretty popular. It's exciting to get a This Is playlist, as an artist, because it suggests that you have "essential" tracks. But that, too, is a marketing claim with no inherent grounding. The criteria for generating them are logistic, not cultural, and the thresholds have been adjusted downwards over time. I have one, and my music is as non-essential as you can get without employing AI. Illusory validation caters to vanity, and subtly devalues actual validation.
Taken in collective aggregate, these tech-marketing tendencies to oversell the significance of algorithms, and in particular the hubris in making cultural claims about the results of mostly-uncultural computation, are a sort of pervasive reverse-gaslighting, substituting brightly confident light where it should be modestly dim. And every little cognitive dissonance like this that we accept erodes either our actual awareness of misrepresented reality, or our trust in systems, or both.
But here's the thing. At the end, there's still music. The algorithms have no soul for music to save. We do. Our machines can only gaslight us if we grant them authority. So don't. They serve at our pleasure, but sometimes they work. You don't have to trust them to cherish them when they help. The past doesn't always organize itself, and math and patterns of our listening can tell us things we only almost already knew. Here's another of my attempts to put songs in algorithmic order:

This one tries to re-center the universe of music on any individual artist of your choosing, and then follow a vague spiralish pattern outwards in every direction at once. If we start with The Big Bopper, does it reconstruct the Music that Died that day? I don't know, I wasn't even born yet. But this math started from the The Big Bopper and rediscovered Buddy Holly and Ritchie Valens without knowing it should, so that's an interesting start. Is it "canonical"? No, of course not, the title is my rueful joke, and there's a note at the bottom that explains what I'm attempting. If you think algorithms themselves are the problem, I'm definitely part of it. I believe in attempts. If I had written the blurb for This Is, it would probably have said "An earnest algorithmic attempt at finding the maybe-essential tracks." Marketing doesn't talk that way. It isn't earnest, and it certainly isn't self-aware of how earnest it isn't.
But where self-awareness is systemically missing, we can sometimes reintroduce it ourselves. Not always, but sometimes. We don't have to let overselling trick us into thinking every oversold thing underperforms. We don't have to let premature marketing hubris scare us away from experimentation and helpful progress. Defuse their claim of essentiality with a now-knowing smirk, and those This Is playlists can be interesting. This may not be a canonical path, but it might still take us somewhere. That's something. We can let it be enough. Let algorithms work when they work for us, and fail cheerfully when they don't, and this will be yet another of all the days that music doesn't die.
This is reasonable behavior, not least because it's explainable, but it's not always the greatest listening experience. What you probably want, I think, if you just hit Play without picking your own starting point, is a sampler of the artist's songs. Their 10 most popular songs are a subset, but not always a great sample. They might all come from the same album, they might include multiple versions of the same song, they might include intros or interstitial tracks that don't actually make sense on their own. And a reverse-chron trudge through literally all the artist's releases, after those first 10 popular tracks, is not a "sample" at all.
This bothered me, so at one point pretty early in my long time at Spotify I spent a little while seeing if I could devise an algorithm to create a better sample-order. It wasn't especially complicated, but it tried to diversify the selection by album, and to group song-versions in order to understand singles as part of their album's eras, and not play the same real-world song over and over due to minor variations. It rarely produced the same summary of an artist's career that a knowledgeable human fan would have, because it didn't have any real cultural insight to work with, but it did a decently non-idiotic job for most artists. I felt pretty good about claiming that it was a better default introduction to an artist than playing the 10 most popular tracks and then every single release.
That wasn't what we ended up doing with the idea, though. Invisible improvements are unglamorous. Instead, it became A Product. That product was the "This Is" artist-playlist series. And because Products make Claims, this new playlist series got an ambitious tagline: "This is [artist name]. The essential tracks, all in one playlist."
Here, apropos of today's anniversary of The Big Bopper's untimely death, is the contents of This Is The Big Bopper:
You can see, I think, that the execution has not quite lived up to the premise. The algorithm has done its best to vary the order of nominal source albums, but The Big Bopper didn't make any albums while he was alive, so all of these are actually posthumous compilations. He didn't record very much, period, so in an attempt to make a playlist that isn't just his two hits, the rules have picked a bunch of tracks that aren't even available for streaming, including a couple of sub-1:00 news clips that we are probably happy to be forced to skip, and a very dubiously misspelled "It's the Thruth, Ruth" that probably shouldn't have been released in the first place. But even without those, it makes little musical sense to describe this set as "all the essential tracks". Most of these are no more "essential" than the others, and the official a-side of his first single, "Purple People Eater Meets the Witch Doctor" ("Chantilly Lace" was the nominal b-side of this), is missing.
As an unseen track-order for a sampler, though, this isn't terrible. It improves on the default play-button behavior by not playing the same songs 3 or 4 times each, at least. I'm pretty sure my original version of this algorithm had a duration-filter that would have eliminated the news clips, and an availability filter that would have blocked the Thruth. The algorithm, itself, was a small useful thing that improved the world a little bit. That's all, as its author, I ever claimed about it.
The claims we make, about our algorithms, are a different thing from what they are. I was not in charge of the claims Spotify ended up attaching to this one. I believe that algorithmic intermediation of culture should be done with relentless humility and care. This is not the attitude generally adopted by tech-product marketing. "All the essential tracks" is a more compelling premise than "a slightly better sample-order", for sure. I wouldn't have used it, because the algorithm doesn't deliver it. Marketing doesn't care.
Does it matter? In this case, maybe it doesn't matter a lot. In truth there's probably only one "essential" Big Bopper song, and it's "American Pie". You've achieved a minimally acceptable cultural literacy if you know what Don McLean's memorial is about, and extra credit if you can hum "La Bamba" and any Buddy Holly song that isn't actually by Weezer. The Big Bopper is, sadly, a lot more famous for dying in a plane crash than he is for anything he sang. If you hit his Play button and get "Chantilly Lace", that's already more than most people know.
The This Is series has gone on to be pretty popular. It's exciting to get a This Is playlist, as an artist, because it suggests that you have "essential" tracks. But that, too, is a marketing claim with no inherent grounding. The criteria for generating them are logistic, not cultural, and the thresholds have been adjusted downwards over time. I have one, and my music is as non-essential as you can get without employing AI. Illusory validation caters to vanity, and subtly devalues actual validation.
Taken in collective aggregate, these tech-marketing tendencies to oversell the significance of algorithms, and in particular the hubris in making cultural claims about the results of mostly-uncultural computation, are a sort of pervasive reverse-gaslighting, substituting brightly confident light where it should be modestly dim. And every little cognitive dissonance like this that we accept erodes either our actual awareness of misrepresented reality, or our trust in systems, or both.
But here's the thing. At the end, there's still music. The algorithms have no soul for music to save. We do. Our machines can only gaslight us if we grant them authority. So don't. They serve at our pleasure, but sometimes they work. You don't have to trust them to cherish them when they help. The past doesn't always organize itself, and math and patterns of our listening can tell us things we only almost already knew. Here's another of my attempts to put songs in algorithmic order:
This one tries to re-center the universe of music on any individual artist of your choosing, and then follow a vague spiralish pattern outwards in every direction at once. If we start with The Big Bopper, does it reconstruct the Music that Died that day? I don't know, I wasn't even born yet. But this math started from the The Big Bopper and rediscovered Buddy Holly and Ritchie Valens without knowing it should, so that's an interesting start. Is it "canonical"? No, of course not, the title is my rueful joke, and there's a note at the bottom that explains what I'm attempting. If you think algorithms themselves are the problem, I'm definitely part of it. I believe in attempts. If I had written the blurb for This Is, it would probably have said "An earnest algorithmic attempt at finding the maybe-essential tracks." Marketing doesn't talk that way. It isn't earnest, and it certainly isn't self-aware of how earnest it isn't.
But where self-awareness is systemically missing, we can sometimes reintroduce it ourselves. Not always, but sometimes. We don't have to let overselling trick us into thinking every oversold thing underperforms. We don't have to let premature marketing hubris scare us away from experimentation and helpful progress. Defuse their claim of essentiality with a now-knowing smirk, and those This Is playlists can be interesting. This may not be a canonical path, but it might still take us somewhere. That's something. We can let it be enough. Let algorithms work when they work for us, and fail cheerfully when they don't, and this will be yet another of all the days that music doesn't die.
¶ We Will Know Ourselves by Our Love; We Will Know You By What You Let Go · 1 February 2024 listen/tech
Collective listening is a cultural investment. Collected listening data can be valuable for music streaming services' selfish business purposes, of course, but it's generated by music and listeners, and should be valuable to the world and to music first.
It was my job, for a while, to try to turn music-listening data into cultural knowledge. My opinion, from doing that, is that there are four fundamental kinds of socially valuable music-cultural knowledge that can be learned, with a little attentive work but no need for inscrutable magic, from listening.
The first is popularity. The most fundamental change in our knowledge about music and love, from the physical era to the streaming era, is that we now know what every listener plays, instead of only what they buy. In its simplest form this produces playcounts, and thus the most basic form of streaming transparency and accountability is showing those playcounts. Streaming services have to track plays for royalty purposes, obviously, but music accounting is done by track, and cultural accounting is done by recording and song. At a minimum, we consider the single and the reappearance of that same exact audio on the subsequent album to be one cultural unit, not two, and thus want to see the total plays for both tracks combined in both places. Most major current services do this adequately, albeit at different levels of precision (and one major service glaringly does not display playcounts at all). But really, as people we know that the live version of a song is the same song as the studio version, and if we ask each other what the most popular song on a live album is, we do not mean which of those literal live recordings has been played the most, we mean which of those compositions has been conjured into the air the most across all its minor variations. So far no service has attempted to show this human version of popularity in public, although probably all of them have some internal representation of the idea for their own purposes. (I have worked on various logistical and cultural issues around song identity and disambiguation over the course of my time in music data, but never on the actual mechanics of music recognition, ala Shazam.)
The second kind of knowledge, derived from the first, is currency. We would like to know, I think, what music people are playing "now". Ariana Grande's new song is currently hotter than her old ones, even though it is nowhere near the total playcount of the old ones yet. This can be calculated with windows of data-eligibility, or by prorating plays by age, and most major services do some version of this, but only share it selectively. Spotify, for example, uses an internal version of currency to select and rank an artist's 10 most "Popular" tracks, but only those 10, and the only numbers you actually see there and elsewhere in the app are the all-time playcounts. I worked on a currency algorithm at the Echo Nest, before we were acquired by Spotify, but it's hard to do this very well without actual listening data, and the one Spotify had already devised from better data, without us, produced better results without being any more complicated.
The third kind of knowledge, moving a big step beyond basic transparency, is similarity. Humans listen to music non-randomly, and thus the patterns of our listening encode relationships between songs and between artists. Most current services have some notion of song similarity for use in song radio and other song-level recommendations, and also some notion of artist similarity for behind-the-scenes use in artist radio and more explicit use as some kind of exploratory artist-level navigation ("Related Artists", "Similar Artists", "Fans Also Like", etc.).
I worked on multiple generations of these algorithms in my 12 years at the Echo Nest and then Spotify, and as of my departure in December 2023 the dataset for the "Fans Also Like" lists you see on artists pages in the Spotify app was my personal work. In my time there I had many occasions to compare competing similarity algorithms, both in and out of music, and in a better world less encumbered by petty confidentiality clauses, I would cheerfully bore you with the tradeoffs between them at great length. In my experience simple methods can always beat complicated methods because they're so much easier to evaluate and improve, and time spent refining the inputs is usually at least as productive as tweaking the algorithms themselves, but much less appealing in engineering terms. I consider the calculated similarity network of ~3 million Spotify artists, as I left it, to be a historically monumental achievement of collective listening made mostly possible by streaming itself, but having had to do a lot of internal lobbying on behalf of the musical cogency of similarity results over the years, I am forced to concede that my personal stubbornness is more relevant than any one individual ought to be in this process. Spotify still has my code, but stripped of my will and belief I'm not sure it will thrive or even survive. My individual layoff doesn't necessarily express a Spotify corporate opinion on any larger subject, but it's hard to deny that if Spotify cared, organizationally, about giving the assisted self-organization of the world's listening back to the world, my individual production role in this specific form of it would have been a trivial and uncontroversial excuse for not letting me go. If they give up on this whole feature as a result of one person's absence, it will be a tragic and unforced loss for everybody.
The fourth key form of music knowledge, moving up one more level of abstraction from pairwise similarity, is genre. Genres are the vocabulary by which we understand and discuss music, and genres as communities are the way in which music clusters together in the world. Genres are communities of artists and/or listeners and/or practice, and usually some combination of all three. AI music will be meaningless and inherently point-missing if it attempts to apply sonic criteria without any references to communities of creation or reception, and it will turn out be just one more non-scary new tool in the long history of creative tools if it ends up rooted in how communities sing to themselves about their love. There is no "post-genre" music future, or at least no non-nihilistic one, because music creates genres as it goes.
There are three ecosystemic ways to approach the data-modeling of musical genres: you can let artists self-identify, you can crowd-source categorization from listeners, or you can moderate some combination of those inputs with human expertise.
Two of those ways don't work. Artists self-identify aspirationally, not categorically. If you try to make a radio station of all the rappers who describe themselves as simply "hip hop", you will get a useless pool of 75,000 artists from which most will never be selected. Listeners, conversely, describe music contextually, so two different listeners' "indie pop" playlists may be using the phrase "indie pop" in totally unrelated ways, and thus may have no cultural connection at all. But motivated humans, especially if they know some things about music and are willing to learn more, can mediate these difficulties and channel noisy signals into guided and supervised extrapolations.
You might expect that a global music-streaming service, in recognition of its dependence on music and thus its responsibility to steward music culture, would have a large dedicated team working constantly on systematic, culturally-attuned genre-modeling. Spotify did not. It had editors making playlists, which is sometimes a form of genre curation and sometimes is not. It had ML engineers trying to find correlations between words in playlist titles and tracks, despite playlist titles very much not being a track-tagging interface at all, never mind a genre-categorization tool. It had a handful of people doing specific genre-curation work, mostly on our own initiative because we knew it was worthwhile. And it had me maintaining the genre system, with all its algorithms and all its curation tools. I invented the system (at the Echo Nest, before we were even acquired), I ran it, I supervised it, I tweaked it, I defended it, I believed in it, I helped people apply it to other music and business problems. I had a Slack trigger on the word "genre", so you could summon me from anywhere in Spotify by just typing it. The system grew from hundreds of genres to thousands. My own personal site, everynoise.com (which also predated the Spotify acquisition), was a way to share a sprawling holistic view of it that would never have made sense inside a black-and-green Spotify window or even a white Rdio window before that. I never managed, in ten years of trying, to get genres integrated into the actual daily Spotify music experience (I wanted there to be a list of Fans Also Like genres on artist pages right under the list of Fans Also Like artists; both of these are forms of cultural context and collective knowledge), but I know, from years of emails and stories and other people's independent enthusiasm (including, only shortly before the layoffs, this one in The Pudding, which said "an always-updating catalog of 6,000 genre is groundbreaking" with unfortunate foreshadowing) that I wasn't the only person who understood the value of this whole earnest and unruly and seemingly-endless project.
Will I be proven wrong about the "endless" part? Here, again, we cannot simply conclude that Spotify does not care about genres and music culture because I got laid off. The code remains. Some of the other people who did genre-curation work are still there. Spotify could just keep the internal system running, even if nobody but me would have the inclination or expertise to improve it any further. And maybe they will. I hope they will. It doesn't cost much in computing terms. Spotify is the world's most dominant music-streaming service and genres are how music evolves and exists. Surely one cares about the other.
But if they cared, and one person in a still-8000-person company is basically the smallest practical unit of care, keeping me around would have been self-evidently worthwhile. The genre system wasn't even the only thing I did. The genre system and Fans Also Like weren't even the only things I did. The genre system and Fans Also Like and Wrapped weren't even the only things I did. The public toys I made were the tiniest fraction of my work. If everything I did do wasn't enough, maybe they don't care, and maybe all these things will be unceremoniously abandoned.
But what comes from us, and is made out of our love, of course we can and will rebuild over and over. Spotify is not the only collector of collective listening. These were not the first attempts to connect artists through their shared fans, or to model the genres into which we assemble, and they were never going to be the last. Maybe we will look back on these meager, patchwork networks of only 3 million artists, and only 6000 genres, like we keep the absurdly self-important book reports our kids wrote when they were 9. We are proud of their care and their ambition, not their page-counts. We remember what they dreamed of becoming, and then we hug the people they are in the midst of becoming, and then we think about what we are going to do and become tomorrow.
It was my job, for a while, to try to turn music-listening data into cultural knowledge. My opinion, from doing that, is that there are four fundamental kinds of socially valuable music-cultural knowledge that can be learned, with a little attentive work but no need for inscrutable magic, from listening.
The first is popularity. The most fundamental change in our knowledge about music and love, from the physical era to the streaming era, is that we now know what every listener plays, instead of only what they buy. In its simplest form this produces playcounts, and thus the most basic form of streaming transparency and accountability is showing those playcounts. Streaming services have to track plays for royalty purposes, obviously, but music accounting is done by track, and cultural accounting is done by recording and song. At a minimum, we consider the single and the reappearance of that same exact audio on the subsequent album to be one cultural unit, not two, and thus want to see the total plays for both tracks combined in both places. Most major current services do this adequately, albeit at different levels of precision (and one major service glaringly does not display playcounts at all). But really, as people we know that the live version of a song is the same song as the studio version, and if we ask each other what the most popular song on a live album is, we do not mean which of those literal live recordings has been played the most, we mean which of those compositions has been conjured into the air the most across all its minor variations. So far no service has attempted to show this human version of popularity in public, although probably all of them have some internal representation of the idea for their own purposes. (I have worked on various logistical and cultural issues around song identity and disambiguation over the course of my time in music data, but never on the actual mechanics of music recognition, ala Shazam.)
The second kind of knowledge, derived from the first, is currency. We would like to know, I think, what music people are playing "now". Ariana Grande's new song is currently hotter than her old ones, even though it is nowhere near the total playcount of the old ones yet. This can be calculated with windows of data-eligibility, or by prorating plays by age, and most major services do some version of this, but only share it selectively. Spotify, for example, uses an internal version of currency to select and rank an artist's 10 most "Popular" tracks, but only those 10, and the only numbers you actually see there and elsewhere in the app are the all-time playcounts. I worked on a currency algorithm at the Echo Nest, before we were acquired by Spotify, but it's hard to do this very well without actual listening data, and the one Spotify had already devised from better data, without us, produced better results without being any more complicated.
The third kind of knowledge, moving a big step beyond basic transparency, is similarity. Humans listen to music non-randomly, and thus the patterns of our listening encode relationships between songs and between artists. Most current services have some notion of song similarity for use in song radio and other song-level recommendations, and also some notion of artist similarity for behind-the-scenes use in artist radio and more explicit use as some kind of exploratory artist-level navigation ("Related Artists", "Similar Artists", "Fans Also Like", etc.).
I worked on multiple generations of these algorithms in my 12 years at the Echo Nest and then Spotify, and as of my departure in December 2023 the dataset for the "Fans Also Like" lists you see on artists pages in the Spotify app was my personal work. In my time there I had many occasions to compare competing similarity algorithms, both in and out of music, and in a better world less encumbered by petty confidentiality clauses, I would cheerfully bore you with the tradeoffs between them at great length. In my experience simple methods can always beat complicated methods because they're so much easier to evaluate and improve, and time spent refining the inputs is usually at least as productive as tweaking the algorithms themselves, but much less appealing in engineering terms. I consider the calculated similarity network of ~3 million Spotify artists, as I left it, to be a historically monumental achievement of collective listening made mostly possible by streaming itself, but having had to do a lot of internal lobbying on behalf of the musical cogency of similarity results over the years, I am forced to concede that my personal stubbornness is more relevant than any one individual ought to be in this process. Spotify still has my code, but stripped of my will and belief I'm not sure it will thrive or even survive. My individual layoff doesn't necessarily express a Spotify corporate opinion on any larger subject, but it's hard to deny that if Spotify cared, organizationally, about giving the assisted self-organization of the world's listening back to the world, my individual production role in this specific form of it would have been a trivial and uncontroversial excuse for not letting me go. If they give up on this whole feature as a result of one person's absence, it will be a tragic and unforced loss for everybody.
The fourth key form of music knowledge, moving up one more level of abstraction from pairwise similarity, is genre. Genres are the vocabulary by which we understand and discuss music, and genres as communities are the way in which music clusters together in the world. Genres are communities of artists and/or listeners and/or practice, and usually some combination of all three. AI music will be meaningless and inherently point-missing if it attempts to apply sonic criteria without any references to communities of creation or reception, and it will turn out be just one more non-scary new tool in the long history of creative tools if it ends up rooted in how communities sing to themselves about their love. There is no "post-genre" music future, or at least no non-nihilistic one, because music creates genres as it goes.
There are three ecosystemic ways to approach the data-modeling of musical genres: you can let artists self-identify, you can crowd-source categorization from listeners, or you can moderate some combination of those inputs with human expertise.
Two of those ways don't work. Artists self-identify aspirationally, not categorically. If you try to make a radio station of all the rappers who describe themselves as simply "hip hop", you will get a useless pool of 75,000 artists from which most will never be selected. Listeners, conversely, describe music contextually, so two different listeners' "indie pop" playlists may be using the phrase "indie pop" in totally unrelated ways, and thus may have no cultural connection at all. But motivated humans, especially if they know some things about music and are willing to learn more, can mediate these difficulties and channel noisy signals into guided and supervised extrapolations.
You might expect that a global music-streaming service, in recognition of its dependence on music and thus its responsibility to steward music culture, would have a large dedicated team working constantly on systematic, culturally-attuned genre-modeling. Spotify did not. It had editors making playlists, which is sometimes a form of genre curation and sometimes is not. It had ML engineers trying to find correlations between words in playlist titles and tracks, despite playlist titles very much not being a track-tagging interface at all, never mind a genre-categorization tool. It had a handful of people doing specific genre-curation work, mostly on our own initiative because we knew it was worthwhile. And it had me maintaining the genre system, with all its algorithms and all its curation tools. I invented the system (at the Echo Nest, before we were even acquired), I ran it, I supervised it, I tweaked it, I defended it, I believed in it, I helped people apply it to other music and business problems. I had a Slack trigger on the word "genre", so you could summon me from anywhere in Spotify by just typing it. The system grew from hundreds of genres to thousands. My own personal site, everynoise.com (which also predated the Spotify acquisition), was a way to share a sprawling holistic view of it that would never have made sense inside a black-and-green Spotify window or even a white Rdio window before that. I never managed, in ten years of trying, to get genres integrated into the actual daily Spotify music experience (I wanted there to be a list of Fans Also Like genres on artist pages right under the list of Fans Also Like artists; both of these are forms of cultural context and collective knowledge), but I know, from years of emails and stories and other people's independent enthusiasm (including, only shortly before the layoffs, this one in The Pudding, which said "an always-updating catalog of 6,000 genre is groundbreaking" with unfortunate foreshadowing) that I wasn't the only person who understood the value of this whole earnest and unruly and seemingly-endless project.
Will I be proven wrong about the "endless" part? Here, again, we cannot simply conclude that Spotify does not care about genres and music culture because I got laid off. The code remains. Some of the other people who did genre-curation work are still there. Spotify could just keep the internal system running, even if nobody but me would have the inclination or expertise to improve it any further. And maybe they will. I hope they will. It doesn't cost much in computing terms. Spotify is the world's most dominant music-streaming service and genres are how music evolves and exists. Surely one cares about the other.
But if they cared, and one person in a still-8000-person company is basically the smallest practical unit of care, keeping me around would have been self-evidently worthwhile. The genre system wasn't even the only thing I did. The genre system and Fans Also Like weren't even the only things I did. The genre system and Fans Also Like and Wrapped weren't even the only things I did. The public toys I made were the tiniest fraction of my work. If everything I did do wasn't enough, maybe they don't care, and maybe all these things will be unceremoniously abandoned.
But what comes from us, and is made out of our love, of course we can and will rebuild over and over. Spotify is not the only collector of collective listening. These were not the first attempts to connect artists through their shared fans, or to model the genres into which we assemble, and they were never going to be the last. Maybe we will look back on these meager, patchwork networks of only 3 million artists, and only 6000 genres, like we keep the absurdly self-important book reports our kids wrote when they were 9. We are proud of their care and their ambition, not their page-counts. We remember what they dreamed of becoming, and then we hug the people they are in the midst of becoming, and then we think about what we are going to do and become tomorrow.
¶ bemused complicated partial credit layoff friday morning · 26 January 2024 listen/tech
The glum Digital Music News headline reads "Spotify Daylist is Blowing Up—Too Bad the Creator Was Laid Off", and although I haven't specifically talked to the person who came up with Daylist since the layoffs, I don't think they were affected in this round. The explanation in the body of the story is a little more specific:

This is mostly true in what it actually says. I wasn't the only person working on the Spotify genre-categorization project, but I started it, I ran it, I wrote all of its tools and algorithms, and I worked on many applications of it to internal problems and app features. Without me it probably will not survive. And that genre system is one of the ingredients that feeds into Daylist.
The DMN piece is derived from an earlier article at TechCrunch, where the assertion is more carefully phrased: "Spotify’s astrology-like Daylists go viral, but the company’s micro-genre mastermind was let go last month". And more carefully reported:

...

The "look no further" flourish is misguided, since I didn't curate every individual genre myself, and maybe didn't personally configure any of the ones they cite. We did not make up the name "egg punk", either.
USA Today, drawing from both of these stories, kept the plot twist out of the headline ("How to find your Spotify Daylist: Changing playlists that capture 'every version of you'") and saved it for a rueful final paragraph:
The judicious "help" there is fair enough. And as none of these say, in addition to working on genres I was also a prolific source of this kind of internal personalization experiment, and thus part of an environment that encouraged it.
Daylist itself was absolutely not my doing, though. You'd have to ask its creator about their influences, but so far I haven't seen Spotify give public named credit for the feature, and in a period of sweeping layoffs, in particular, I encourage you to take note of the general corporate reluctance to acknowledge individual work. But while we're at it, I did not have anything to do with Discover Weekly, nor did anybody from the Echo Nest, which was the startup whose acquisition brought me to Spotify and which I did not found. These are not secret details, and a reporter could easily discover them by asking questions. None of three people who wrote those three articles about Daylist talked to me before publishing them.
And although the Daylist feature itself is charming and viral, and I support its existence, it also demonstrates three recurring biases in music personalization that are worth noting for their wider implications.
The most obvious one is that Daylist is based explicitly on the premise that listening is organized by, or at least varies according to, weekdays and dayparts. It is not the first Spotify feature to stipulate this idea, and clearly there are listeners for which it is relevant. But I think both schedule-driven and the similar activity-driven models of listening (workout music, study music, dinner music..) tend to encourage a functional disengagement from music itself. Daylist mitigates this by describing its daypart modes in mostly non-functional terms, including sometimes genres and other musical terminology, and of course you aren't required to listen to nothing but Daylist and thus it isn't obliged to provide all important cultural nutrients. But the eager every-few-hours updating does make a more active bid for constant attention than most other personalization features. Discover Weekly and Release Radar are only weekly, and short. Daily Mix is only (roughly) daily, although it's both endless and multiple. I don't think the cultural potential of having all the world's music online is exactly maximized by encouraging you to spend every Tuesday afternoon the same way you supposedly always have.
The second common personalization bias in Daylist is that it manifestly draws from a large internal catalog of ideas, but you have no control over which subset you are allowed to see, and there is no way to explore the whole idea-space yourself. This parsimonious control-model is not at all unique to Spotify, but it's certainly pervasive in Spotify personalization features, from the type and details of recommendations you see on the Home page to the Mixes you get to the genre and mood filters in your Library. Daylist's decisions about your identity are friendly but unilateral. It's not a conversation. To its credit, Daylist is the first of these features that explains its judgments in interactive form, so you can tap a genre or adjective and see what that individual idea attempts to represent. But this enables only shallow exploration of the local neighborhood of the space. There's still no way to see a complete list of available terms or jump to a particular one even if you somehow know it exists. Obviously everynoise.com demonstrates my strong counterbias towards expansive openness and unrestricted exploration, but one might note that even after 10 years of me working on this genre project at Spotify, there's no place other than my own personal site to see the whole list of genres.
And the third common personalization bias demonstrated unapologetically by Daylist is the endemic tech-company fondness for unsupervised machine learning over explicit human curation. As you can see for yourself by comparing the "genre" mixes you find through Daylists with the corresponding genre pages on everynoise, the genre system is only one of Daylist's inputs. All the non-genre moods and vibes in Daylist obviously come from a different system, but even the genre terms are also filtered through other influences. I did help with those other systems, too, creditwise, but I didn't invent and wasn't running them.
Nor, honestly, do I trust them. You will learn to trust or distrust your own Daylists, if you spend time listening to them or even just inspecting them, but if you follow conversations about them online to get a wider sample than just your own, you will quickly find that they do not always make sense. Mine, right now, claims to be giving me japanese metal and visual kei, but much of it is actually idol rock and a mysterious number of <100-listener Russian metalcore bands that I have never played and which have no evident connection to bands I have. The "Japanese Metal" mix is mostly Japanese, but only sporadically metal. The "Visual Kei" mix is mostly Japanese, and does contain some visual kei, but you'd have to already know what visual kei is to pick those songs out. The "Laptop" mix opens with Morbid Angel's "Visions from the Dark Side", a song that not only was not made on a laptop (to put it mildly), but which narrowly predates the commercial availability of laptops entirely.
The genre system was not error-proof, either. But it was built on intelligible math, it was overseen by humans, and those humans had both the technical tools and moral motivation to fix errors. We did not have a "laptop" genre because "laptop" is not a community of artists or listeners or practice, but if we had, and the system had put Morbid Angel on it, I would have stopped all other work until I was 100% confident I understood why such an egregious error had happened and had taken actions to both prevent that error from recurring and improve the monitoring processes to instill programmatic vigilance against that kind of error.
But once you commit to machine learning, instead of explicit math, you mostly give up on predictability. This doesn't prevent you from detecting errors, but it means you will generally find it hard to correct errors when you detect them, and even harder to prevent new ones from happening. The more complicated your systems, the weirder their failure modes, and the weirder the failures get, the harder it is to anticipate them or their consequences. If you delegate "learning" to machines, what you really mean is that you have given up on the humans learning. The real peril of LLM AI is not that ChatGPT hallucinates, it's that ChatGPT appears to be generating new ideas in such a way that it's tempting to think you don't need to pay people to do that any more. But people having written is why ChatGPT works at all. If generative AI arrives at human truths, sometimes or ever, it's because humans discovered those truths first, and wrote them down. Every problem you turn over to interpolative machines is a problem that will never thereafter be solved in a new way, that will never produce any new truths.
The problem with a music service laying off its genre curator is not the pettiness of firing the person responsible for a shiny new brand-moment. I was responsible for some previous shiny new brand-moments, too, as recently as less than a week before the layoff, but not this one and mere ungratefulness is sad but not systemically destabilizing. Daylist was made by other people, and will be maintained by other people. The problem is that I insisted on putting human judgment and obstinate stewardship in the path of demand-generation, and if that isn't enough to keep you from getting laid off from a music-streaming company, it's hard to imagine anybody else having the idiotic courage to keep trying it.
This is mostly true in what it actually says. I wasn't the only person working on the Spotify genre-categorization project, but I started it, I ran it, I wrote all of its tools and algorithms, and I worked on many applications of it to internal problems and app features. Without me it probably will not survive. And that genre system is one of the ingredients that feeds into Daylist.
The DMN piece is derived from an earlier article at TechCrunch, where the assertion is more carefully phrased: "Spotify’s astrology-like Daylists go viral, but the company’s micro-genre mastermind was let go last month". And more carefully reported:
...
The "look no further" flourish is misguided, since I didn't curate every individual genre myself, and maybe didn't personally configure any of the ones they cite. We did not make up the name "egg punk", either.
USA Today, drawing from both of these stories, kept the plot twist out of the headline ("How to find your Spotify Daylist: Changing playlists that capture 'every version of you'") and saved it for a rueful final paragraph:
The judicious "help" there is fair enough. And as none of these say, in addition to working on genres I was also a prolific source of this kind of internal personalization experiment, and thus part of an environment that encouraged it.
Daylist itself was absolutely not my doing, though. You'd have to ask its creator about their influences, but so far I haven't seen Spotify give public named credit for the feature, and in a period of sweeping layoffs, in particular, I encourage you to take note of the general corporate reluctance to acknowledge individual work. But while we're at it, I did not have anything to do with Discover Weekly, nor did anybody from the Echo Nest, which was the startup whose acquisition brought me to Spotify and which I did not found. These are not secret details, and a reporter could easily discover them by asking questions. None of three people who wrote those three articles about Daylist talked to me before publishing them.
And although the Daylist feature itself is charming and viral, and I support its existence, it also demonstrates three recurring biases in music personalization that are worth noting for their wider implications.
The most obvious one is that Daylist is based explicitly on the premise that listening is organized by, or at least varies according to, weekdays and dayparts. It is not the first Spotify feature to stipulate this idea, and clearly there are listeners for which it is relevant. But I think both schedule-driven and the similar activity-driven models of listening (workout music, study music, dinner music..) tend to encourage a functional disengagement from music itself. Daylist mitigates this by describing its daypart modes in mostly non-functional terms, including sometimes genres and other musical terminology, and of course you aren't required to listen to nothing but Daylist and thus it isn't obliged to provide all important cultural nutrients. But the eager every-few-hours updating does make a more active bid for constant attention than most other personalization features. Discover Weekly and Release Radar are only weekly, and short. Daily Mix is only (roughly) daily, although it's both endless and multiple. I don't think the cultural potential of having all the world's music online is exactly maximized by encouraging you to spend every Tuesday afternoon the same way you supposedly always have.
The second common personalization bias in Daylist is that it manifestly draws from a large internal catalog of ideas, but you have no control over which subset you are allowed to see, and there is no way to explore the whole idea-space yourself. This parsimonious control-model is not at all unique to Spotify, but it's certainly pervasive in Spotify personalization features, from the type and details of recommendations you see on the Home page to the Mixes you get to the genre and mood filters in your Library. Daylist's decisions about your identity are friendly but unilateral. It's not a conversation. To its credit, Daylist is the first of these features that explains its judgments in interactive form, so you can tap a genre or adjective and see what that individual idea attempts to represent. But this enables only shallow exploration of the local neighborhood of the space. There's still no way to see a complete list of available terms or jump to a particular one even if you somehow know it exists. Obviously everynoise.com demonstrates my strong counterbias towards expansive openness and unrestricted exploration, but one might note that even after 10 years of me working on this genre project at Spotify, there's no place other than my own personal site to see the whole list of genres.
And the third common personalization bias demonstrated unapologetically by Daylist is the endemic tech-company fondness for unsupervised machine learning over explicit human curation. As you can see for yourself by comparing the "genre" mixes you find through Daylists with the corresponding genre pages on everynoise, the genre system is only one of Daylist's inputs. All the non-genre moods and vibes in Daylist obviously come from a different system, but even the genre terms are also filtered through other influences. I did help with those other systems, too, creditwise, but I didn't invent and wasn't running them.
Nor, honestly, do I trust them. You will learn to trust or distrust your own Daylists, if you spend time listening to them or even just inspecting them, but if you follow conversations about them online to get a wider sample than just your own, you will quickly find that they do not always make sense. Mine, right now, claims to be giving me japanese metal and visual kei, but much of it is actually idol rock and a mysterious number of <100-listener Russian metalcore bands that I have never played and which have no evident connection to bands I have. The "Japanese Metal" mix is mostly Japanese, but only sporadically metal. The "Visual Kei" mix is mostly Japanese, and does contain some visual kei, but you'd have to already know what visual kei is to pick those songs out. The "Laptop" mix opens with Morbid Angel's "Visions from the Dark Side", a song that not only was not made on a laptop (to put it mildly), but which narrowly predates the commercial availability of laptops entirely.
The genre system was not error-proof, either. But it was built on intelligible math, it was overseen by humans, and those humans had both the technical tools and moral motivation to fix errors. We did not have a "laptop" genre because "laptop" is not a community of artists or listeners or practice, but if we had, and the system had put Morbid Angel on it, I would have stopped all other work until I was 100% confident I understood why such an egregious error had happened and had taken actions to both prevent that error from recurring and improve the monitoring processes to instill programmatic vigilance against that kind of error.
But once you commit to machine learning, instead of explicit math, you mostly give up on predictability. This doesn't prevent you from detecting errors, but it means you will generally find it hard to correct errors when you detect them, and even harder to prevent new ones from happening. The more complicated your systems, the weirder their failure modes, and the weirder the failures get, the harder it is to anticipate them or their consequences. If you delegate "learning" to machines, what you really mean is that you have given up on the humans learning. The real peril of LLM AI is not that ChatGPT hallucinates, it's that ChatGPT appears to be generating new ideas in such a way that it's tempting to think you don't need to pay people to do that any more. But people having written is why ChatGPT works at all. If generative AI arrives at human truths, sometimes or ever, it's because humans discovered those truths first, and wrote them down. Every problem you turn over to interpolative machines is a problem that will never thereafter be solved in a new way, that will never produce any new truths.
The problem with a music service laying off its genre curator is not the pettiness of firing the person responsible for a shiny new brand-moment. I was responsible for some previous shiny new brand-moments, too, as recently as less than a week before the layoff, but not this one and mere ungratefulness is sad but not systemically destabilizing. Daylist was made by other people, and will be maintained by other people. The problem is that I insisted on putting human judgment and obstinate stewardship in the path of demand-generation, and if that isn't enough to keep you from getting laid off from a music-streaming company, it's hard to imagine anybody else having the idiotic courage to keep trying it.
¶ New Releases by...Something · 25 January 2024 listen/tech
Whatever my job is or, currently, isn't, I still really want to know about new music, and there were exactly two excellent methods for this and I made them both and I'm not allowed to use either one any more. So I keep poking at approaches to this problem using public tools, and the Spotify API is still the best of these. I've gone so far as to implement a version of the obviously-intractable brute-force approach of getting a genre's artists, expanding to all those artists' Fans Also Like artists (refcounting along the way), and then getting the catalog for each artist in the resulting longer list in order to filter their releases by release-date.
This does sort of work, eventually. It's not especially convincing for coverage, because the public API only exposes 20 Fans Also Like artists, where the internal Spotify datasource behind that (at least as long as they keep maintaining the similar-artist system I wrote) had up to 250 for each seed artist. And it takes just about forever, because it requires thousands of individual queries, and even with only one instance of it running my API key quickly hits its rate-limit and gets throttled to wait in between calls.
As I have noted, Spotify could mostly fix this problem by enabling genre: filtering in the /search API when searching for "albums" (which actually means releases despite my 10 years of trying to persuade a nominal music service to take the difference between singles and albums seriously), since this API already has a tag:new filter for getting new releases (from the last 2 weeks, which is also kind of arbitrary but at least means the last full release-week is always completely covered). There's already internal data for artists' "extended" genres, which is the extrapolated version using collective artist similarity. Or at least there is if they keep maintaining the genre system I wrote.
You can see exactly how viable this is, if you're curious and not unmanageably triggered by a thing that takes the shape of our loss without salving it, because the search API does already allow release searches to be filtered by label: the same way it could allow searching by genre. Any API app could do this, there's nothing special about my access or techniques here. But I looked and didn't find one, so I made it. This is what my job was like, too, and apparently I was literally correct when I used to say that I'd be doing it even if they weren't paying me.
Thus: New Releases by Label for, e.g., a list of 58 metal-related labels.

The chances are decent that if too many people try this at once it will slow down or die, too, but for each label it requires as few as two queries: one to get that label's new releases (in pages of 50 if a single label has more than 50 new releases from the last two weeks), and then at least one follow-up query (in pages of 20) to get those albums' tracks. This is reasonable overhead.
Labels are no direct substitute for genres, obviously, not least because if you care about music you need not also care about labels or whether artists are even on one.
And even if you do care about labels, label data is messy. It's something of a stretch to call it "label data", in the current music-distribution ecosystem. There's a text field for "label", and humans type stuff into it. If the humans doing a given bit of typing are diligent, and none of the other undiligent humans stray into the diligent namespaces by accident or nefarity, then you can kind of pretend it's data. I spent a while in my former job trying to do slightly better than this by aggressively normalizing name-variations and algorithmically distinguishing between actual labels and whatever words people who aren't on labels would type into that box, with some success:
I see there that my past-job self could have combined "Hell's Headbangers" and "Hells Headbangers Records" by removing apostrophes, which either didn't occur to me or caused more problems than it solved, and I no longer remember which and can't check.
There are, though, many labels that exist to release a certain kind of music according to some kind of unifying principle, and those principles tend to align with genres, or more accurately tend to be part of the social structure that builds music-based communities, which are what I usually mean when I talk about genres. So this approach is wildly incomplete, but seems at least potentially helpful to me. You can try it with some labels you like, and see if it helps you, too.
The one small catch with this is that the API label filter is very literal. You have to know the exact way the label you're looking for is typed in the "label" fields. And, inconveniently, that label field does not actually appear in the Spotify app.** What you see instead are the copyright and publishing credits, at the bottom of an album's tracklist like this:

You might guess that the "label" here could be either "AFM Records" or "Soulfood Music Distribution GmbH", and as it turns out "AFM Records" is right, but it didn't have to be either of those and guessing is tedious anyway.
But I have a thing for exercising my petty annoyances about how to display albums, already, so if you look up an artist in the everynoise research tools, you can now see each release's label next to its release date.
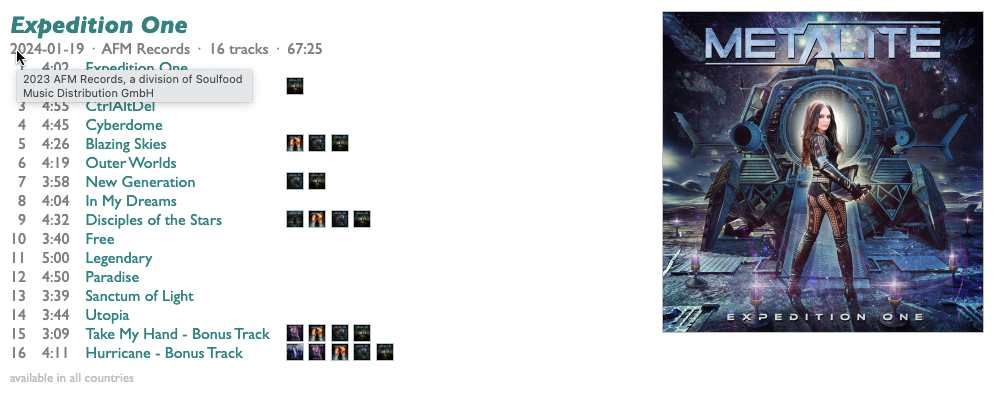
But looking labels up album by album is tedious, too. The one automated tool left in my new-release workflow is Release Radar, which provides a subsistence level of new-release awareness if you take the time to follow all the artists you know you care about. And I have a thing for exercising my petty annoyances about how to display playlists, too, so I added a label column to it, which you can even click on to sort or group a whole playlist by label:
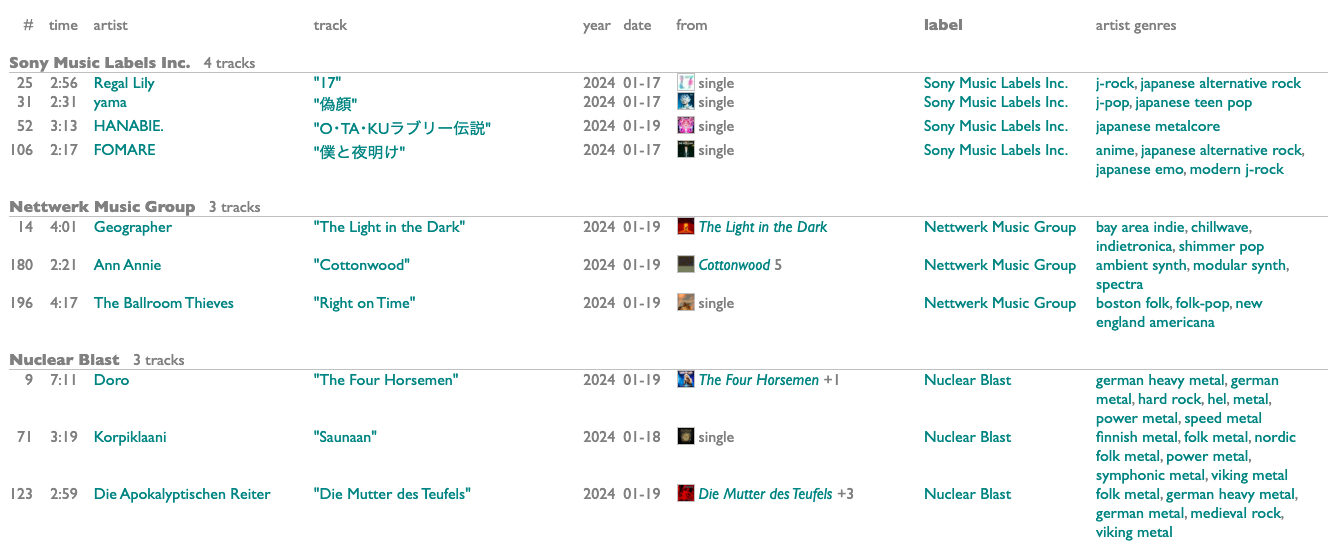
And if your playlist happens to represent a subset of new releases you know you care about, look at the bottom of that page for a little helpful link to feed all the labels from a given playlist back into New Releases by Label.

Obviously it would be better if there was also a link to find new releases from this playlist's genres, instead of just its labels, and of course that's what this link used to do. And could do, again, in a better future.
We will get better futures. That is, we'll get them if we build them, and we will build them, one way or another, because it's too annoying not having them.
** 1/30: An alert reader notes that the label actually is available in the Spotify app, not on the release itself but in the Song Credits dialog for any of its songs, at the bottom labeled "Source".
This does sort of work, eventually. It's not especially convincing for coverage, because the public API only exposes 20 Fans Also Like artists, where the internal Spotify datasource behind that (at least as long as they keep maintaining the similar-artist system I wrote) had up to 250 for each seed artist. And it takes just about forever, because it requires thousands of individual queries, and even with only one instance of it running my API key quickly hits its rate-limit and gets throttled to wait in between calls.
As I have noted, Spotify could mostly fix this problem by enabling genre: filtering in the /search API when searching for "albums" (which actually means releases despite my 10 years of trying to persuade a nominal music service to take the difference between singles and albums seriously), since this API already has a tag:new filter for getting new releases (from the last 2 weeks, which is also kind of arbitrary but at least means the last full release-week is always completely covered). There's already internal data for artists' "extended" genres, which is the extrapolated version using collective artist similarity. Or at least there is if they keep maintaining the genre system I wrote.
You can see exactly how viable this is, if you're curious and not unmanageably triggered by a thing that takes the shape of our loss without salving it, because the search API does already allow release searches to be filtered by label: the same way it could allow searching by genre. Any API app could do this, there's nothing special about my access or techniques here. But I looked and didn't find one, so I made it. This is what my job was like, too, and apparently I was literally correct when I used to say that I'd be doing it even if they weren't paying me.
Thus: New Releases by Label for, e.g., a list of 58 metal-related labels.
The chances are decent that if too many people try this at once it will slow down or die, too, but for each label it requires as few as two queries: one to get that label's new releases (in pages of 50 if a single label has more than 50 new releases from the last two weeks), and then at least one follow-up query (in pages of 20) to get those albums' tracks. This is reasonable overhead.
Labels are no direct substitute for genres, obviously, not least because if you care about music you need not also care about labels or whether artists are even on one.
And even if you do care about labels, label data is messy. It's something of a stretch to call it "label data", in the current music-distribution ecosystem. There's a text field for "label", and humans type stuff into it. If the humans doing a given bit of typing are diligent, and none of the other undiligent humans stray into the diligent namespaces by accident or nefarity, then you can kind of pretend it's data. I spent a while in my former job trying to do slightly better than this by aggressively normalizing name-variations and algorithmically distinguishing between actual labels and whatever words people who aren't on labels would type into that box, with some success:
I see there that my past-job self could have combined "Hell's Headbangers" and "Hells Headbangers Records" by removing apostrophes, which either didn't occur to me or caused more problems than it solved, and I no longer remember which and can't check.
There are, though, many labels that exist to release a certain kind of music according to some kind of unifying principle, and those principles tend to align with genres, or more accurately tend to be part of the social structure that builds music-based communities, which are what I usually mean when I talk about genres. So this approach is wildly incomplete, but seems at least potentially helpful to me. You can try it with some labels you like, and see if it helps you, too.
The one small catch with this is that the API label filter is very literal. You have to know the exact way the label you're looking for is typed in the "label" fields. And, inconveniently, that label field does not actually appear in the Spotify app.** What you see instead are the copyright and publishing credits, at the bottom of an album's tracklist like this:
You might guess that the "label" here could be either "AFM Records" or "Soulfood Music Distribution GmbH", and as it turns out "AFM Records" is right, but it didn't have to be either of those and guessing is tedious anyway.
But I have a thing for exercising my petty annoyances about how to display albums, already, so if you look up an artist in the everynoise research tools, you can now see each release's label next to its release date.
But looking labels up album by album is tedious, too. The one automated tool left in my new-release workflow is Release Radar, which provides a subsistence level of new-release awareness if you take the time to follow all the artists you know you care about. And I have a thing for exercising my petty annoyances about how to display playlists, too, so I added a label column to it, which you can even click on to sort or group a whole playlist by label:
And if your playlist happens to represent a subset of new releases you know you care about, look at the bottom of that page for a little helpful link to feed all the labels from a given playlist back into New Releases by Label.
Obviously it would be better if there was also a link to find new releases from this playlist's genres, instead of just its labels, and of course that's what this link used to do. And could do, again, in a better future.
We will get better futures. That is, we'll get them if we build them, and we will build them, one way or another, because it's too annoying not having them.
** 1/30: An alert reader notes that the label actually is available in the Spotify app, not on the release itself but in the Song Credits dialog for any of its songs, at the bottom labeled "Source".