
2 June 2014 to 28 February 2014
I really can't sleep sitting up. But I can write songs on planes. It's a trade-off.
So here. This is my new song, composed and played on the flight from Boston to Keflavik, and sung in my Stockholm hotel room a few hours later as I fought to stay awake until a reasonable bedtime.
Methods Out of Favor (4:10)
All my songs kind of sound a little bit the same, which I'm OK with, but this one is at least in a slightly different tempo.
So here. This is my new song, composed and played on the flight from Boston to Keflavik, and sung in my Stockholm hotel room a few hours later as I fought to stay awake until a reasonable bedtime.
Methods Out of Favor (4:10)
All my songs kind of sound a little bit the same, which I'm OK with, but this one is at least in a slightly different tempo.
¶ A little more press · 21 May 2014 listen/tech
A couple new bits of press about Every Noise at Once:
PolicyMic - Discover Incredible New Music You've Never Heard Using This Interactive Map
Daily Dot - Dive into Every Noise at Once, a musical map of genres you didn't know existed
The first one is particularly good in the sense of being written thoughtfully by somebody other than me. The second one is particularly good in the sense of consisting largely of quotes from my answers to their questions.
PolicyMic - Discover Incredible New Music You've Never Heard Using This Interactive Map
Daily Dot - Dive into Every Noise at Once, a musical map of genres you didn't know existed
The first one is particularly good in the sense of being written thoughtfully by somebody other than me. The second one is particularly good in the sense of consisting largely of quotes from my answers to their questions.
¶ Every Noise at Once, more oncely · 20 May 2014 listen/tech
The Every Noise at Once genre-map reduces 13 music-analytical dimensions to 2 visual dimensions.
But if that's still a little too much for you, I've now added a version that reduces the whole genre space to one dimension: a list. But a list that you can sort and filter several different ways!
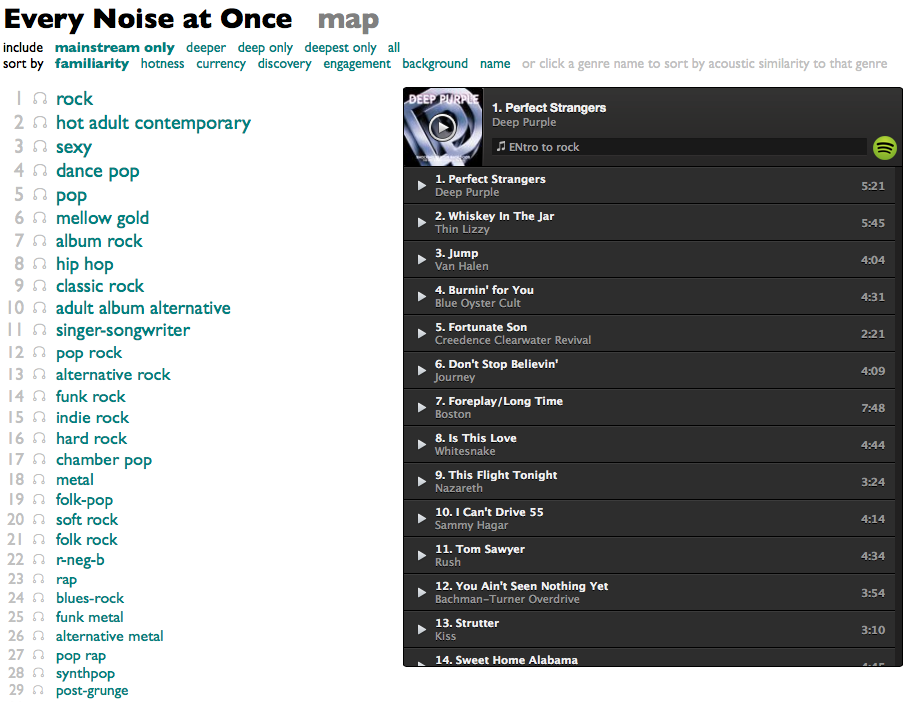
If one dimension is still too profuse and rococo for you, the reduction of the analytical space into zero dimensions is kind of this:
But if that's still a little too much for you, I've now added a version that reduces the whole genre space to one dimension: a list. But a list that you can sort and filter several different ways!
If one dimension is still too profuse and rococo for you, the reduction of the analytical space into zero dimensions is kind of this:
¶ Drunkard's Rock · 19 May 2014 listen/tech
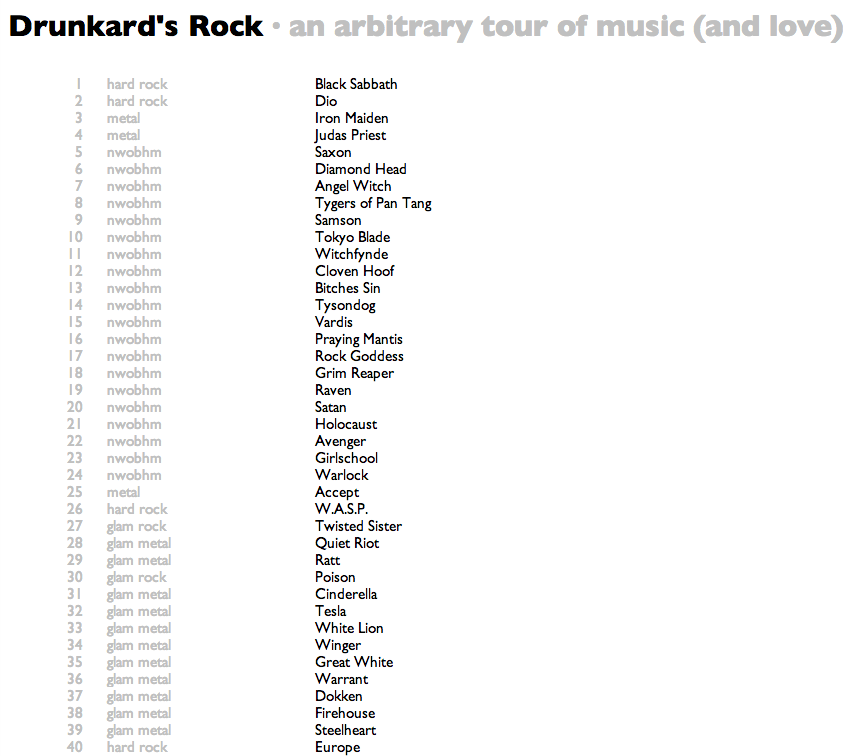
Drunkard's Walk is a mathematical idea involving a random iterative traversal of a multidimensional space.
Drunkard's Rock is an experiment I did to pursue a random iterative traversal of the multidimensional musical artist-similarity space.
In the mathematical version, the drunkard is allowed to retrace their steps, and in fact the point of the problem is to determine the chance of the drunkard randomly arriving home again.
In my version, retracing steps is explicitly disallowed, and thus the drunkard is doomed to wander until the universe expires. Probably it says something about my personality that this seems like the preferable curse to me.
Anyway, I started the calculation with Black Sabbath, both because my own musical evolution sort of started in earnest with Black Sabbath, and because Paul Lamere used Black Sabbath as the reference point in his inversely minded Six Degrees of Black Sabbath, which attempts to find the shortest path between two bands.
My version, to reiterate, just keeps wandering. I guess it is searching for the longest path between Black Sabbath and whatever it finds last. Except I stopped it at 100k steps, because the resulting web page is enormous enough. It will annoy you least if you just leave it alone for a couple minutes while it loads, and then you should be able to scroll around.
Drunkard's Rock is an experiment I did to pursue a random iterative traversal of the multidimensional musical artist-similarity space.
In the mathematical version, the drunkard is allowed to retrace their steps, and in fact the point of the problem is to determine the chance of the drunkard randomly arriving home again.
In my version, retracing steps is explicitly disallowed, and thus the drunkard is doomed to wander until the universe expires. Probably it says something about my personality that this seems like the preferable curse to me.
Anyway, I started the calculation with Black Sabbath, both because my own musical evolution sort of started in earnest with Black Sabbath, and because Paul Lamere used Black Sabbath as the reference point in his inversely minded Six Degrees of Black Sabbath, which attempts to find the shortest path between two bands.
My version, to reiterate, just keeps wandering. I guess it is searching for the longest path between Black Sabbath and whatever it finds last. Except I stopped it at 100k steps, because the resulting web page is enormous enough. It will annoy you least if you just leave it alone for a couple minutes while it loads, and then you should be able to scroll around.
¶ 4 Entries for an Audible Glossary · 2 May 2014 listen/tech
Every Noise at Once is a readability-adjusted scatter-plot of musical genres. The music moves from high density on the left to high bounciness on the right, and from high mechanism at the top to high organism at the bottom. Although I do have more words to explain what each of these ideas means, it's maybe better to just hear how the qualities manifest themselves in actual music.
So here are four data-generated sampler playlists of songs that demonstrate the extreme values of these two analytical dimensions:
So here are four data-generated sampler playlists of songs that demonstrate the extreme values of these two analytical dimensions:
| Density | Bounciness |
Mechanism | Organism |
¶ Voices on the Radio, Whispers in Your Ear · 1 May 2014 listen/tech
WBUR ran a story today about The Echo Nest, including such important topics as Massive Amounts of Data and Viking Metal.
Music Freaks At Somerville’s The Echo Nest Fuel The Engine Under Spotify’s Hood
Meanwhile, one thing I did with our Massive Amounts of Data today is make some playlists of quiet, calm music from unlikely sources. Here, for example, are three sets from artists normally known for metal, electronica or hip hop.
Music Freaks At Somerville’s The Echo Nest Fuel The Engine Under Spotify’s Hood
Meanwhile, one thing I did with our Massive Amounts of Data today is make some playlists of quiet, calm music from unlikely sources. Here, for example, are three sets from artists normally known for metal, electronica or hip hop.
I gave a talk on music discovery and genre-mapping at the 2014 EMP Pop Conference in Seattle last weekend. My co-panelist Michaelangelo Matos had the presence of mind to record the audio from this, and mostly the talk was just audio. Actually, I was wearing some really excellent silver pants, but while talking I was behind a podium, so you aren't missing that much. The map I describe at the end is Every Noise at Once.
So if you're curious, the talk is 16:32 long, and you can listen here:
Every Noise at Once @ EMP Pop 2014
And, although this will not make a lot of sense until after you listen to the talk, the playlist I narrate is also available here:
So if you're curious, the talk is 16:32 long, and you can listen here:
Every Noise at Once @ EMP Pop 2014
And, although this will not make a lot of sense until after you listen to the talk, the playlist I narrate is also available here:
In between other tasks at work today, I made some playlists.
¶ New Echoes · 6 March 2014 listen/tech
Music is the thing humans do best, and all the astonishing music in the world, or close enough, is now available online. This is basically more awesome than the grandest future I ever imagined as a kid.
But that's a lot of music. How do we make any kind of sense of it, so that this vast theoretical grandness can have any kind of actual practical significance? How do you listen to anything when you can suddenly hear every noise at once?
Those are questions I am paid to try to help answer. I've been working for a small music-intelligence startup in Somerville called The Echo Nest. We've been running the back-end data-analysis systems that supply recommendations, personalization and music-discovery ideas to a bunch of streaming music services. When I tell people this, they usually say "Like Spotify?" And I say "Yes, like Spotify."
But although we've been working with Spotify in various capacities, and various non-Spotify developers have made applications that combine our things with Spotify's music, we haven't been running the parts of Spotify that we run for other services. This has been an ongoing personal frustration, because Spotify is the most visible on-demand streaming music service in the world, and I've been pretty convinced that we could help them do a dramatically better job.
We are now going to get that chance. The Echo Nest has, in fact, just been wholly acquired by Spotify. Starting today, it's actually my job to try to improve essentially everything about Spotify that matters to me.
And this is only barely the beginning. I think we are, I mean collectively as humanity, only just at the dawn of the era of infinite music. The current streaming-music interaction-models and feature-sets are as much vestiges of our past technical constraints as anything else. It's as if we have jumped from the horse-drawn carriage to the free personal teleporter, suddenly, without the intervening benefit of even basic maps, never mind language translators or cultural history or GPS.
For the world of music to become something we actually inhabit, natively, as opposed to a bunch of awkward phone icons into which we try to contort our curiosity and wonder, or a vast unknown from which we cower and seek familiar comfortable retreats, it's going to take a lot more than "Play me more stuff like Dave Matthews, but do a better job of it." It's going to require that we belatedly render this vast world navigable, and chart it accurately and compellingly, and put sensible enough control panels on the teleporters that you have some prayer of not just constantly zapping yourself 60' deep into an exotic undiscovered faraway cliff face.
So that's what I'm going to be working on now.
[PS: I no longer remember anything memorable or inspiring or even intelligible anybody ever said to introduce my previous acquisitions, but by way of explaining the Echo Nest purchase, Spotify CEO Daniel Ek said this: "At Spotify, we want to get people to listen to more music."]
[PPS: And it's going to take a little while to get Echo Nest + Spotify things actually hooked up and working, but here's some music to listen to in the meantime.]
But that's a lot of music. How do we make any kind of sense of it, so that this vast theoretical grandness can have any kind of actual practical significance? How do you listen to anything when you can suddenly hear every noise at once?
Those are questions I am paid to try to help answer. I've been working for a small music-intelligence startup in Somerville called The Echo Nest. We've been running the back-end data-analysis systems that supply recommendations, personalization and music-discovery ideas to a bunch of streaming music services. When I tell people this, they usually say "Like Spotify?" And I say "Yes, like Spotify."
But although we've been working with Spotify in various capacities, and various non-Spotify developers have made applications that combine our things with Spotify's music, we haven't been running the parts of Spotify that we run for other services. This has been an ongoing personal frustration, because Spotify is the most visible on-demand streaming music service in the world, and I've been pretty convinced that we could help them do a dramatically better job.
We are now going to get that chance. The Echo Nest has, in fact, just been wholly acquired by Spotify. Starting today, it's actually my job to try to improve essentially everything about Spotify that matters to me.
And this is only barely the beginning. I think we are, I mean collectively as humanity, only just at the dawn of the era of infinite music. The current streaming-music interaction-models and feature-sets are as much vestiges of our past technical constraints as anything else. It's as if we have jumped from the horse-drawn carriage to the free personal teleporter, suddenly, without the intervening benefit of even basic maps, never mind language translators or cultural history or GPS.
For the world of music to become something we actually inhabit, natively, as opposed to a bunch of awkward phone icons into which we try to contort our curiosity and wonder, or a vast unknown from which we cower and seek familiar comfortable retreats, it's going to take a lot more than "Play me more stuff like Dave Matthews, but do a better job of it." It's going to require that we belatedly render this vast world navigable, and chart it accurately and compellingly, and put sensible enough control panels on the teleporters that you have some prayer of not just constantly zapping yourself 60' deep into an exotic undiscovered faraway cliff face.
So that's what I'm going to be working on now.
[PS: I no longer remember anything memorable or inspiring or even intelligible anybody ever said to introduce my previous acquisitions, but by way of explaining the Echo Nest purchase, Spotify CEO Daniel Ek said this: "At Spotify, we want to get people to listen to more music."]
[PPS: And it's going to take a little while to get Echo Nest + Spotify things actually hooked up and working, but here's some music to listen to in the meantime.]
¶ We Built This City On · 28 February 2014 listen/tech
My colleague Paul Lamere, at The Echo Nest, has been looking at music listening by listener region and artist: most distinctive artists, favorite artists and anti-preferences.
Here, to go along with that, is a breakdown of music genres by the home cities of the artists responsible:
We Built This City On
Some of these are kind of duh, like "chicago house" being the top genre for Chicago. But as always in data-anything, some obviousness is what gives us the courage to believe the things we didn't already think.
Here, to go along with that, is a breakdown of music genres by the home cities of the artists responsible:
We Built This City On
Some of these are kind of duh, like "chicago house" being the top genre for Chicago. But as always in data-anything, some obviousness is what gives us the courage to believe the things we didn't already think.