
30 May 2025 to 10 January 2025
¶ You should be able to get what you want · 30 May 2025 listen/tech
What I want this morning, after seeing Stand Atlantic and ONE OK ROCK in Boston last night, is a sampler playlist of some of their older songs that I haven't played before.
I can have this! Into Curio we go querying.
First of all, I need to select these two artists. This could be as simple as
or as compact as
but these both assume I'm already following the artists, and I am, but I might want samplers of artists I'm not.
In this version .matching artists looks up each name with a call to the Spotify /search API, .matches goes to the found artists, and #popularity/name.1 sorts them by popularity, groups them by name, and gets the first (most popular) artist out of each group, to avoid any spurious impostors.

Now that we have the artists, we need their "older songs". E.g.:
Here .artist catalogs goes back to the /artists API to get each artist's albums, .catalog goes to those albums, :release_date<2024 filters to just the ones released before 2024, and .tracks:-(:~live,~remix,~acoustic) gets all of those albums' tracks and drops the ones with "live", "remix" or "acoustic" in their titles. Which is messy filtering, since those words could be part of actual song titles, but the Spotify API doesn't give us any structured metadata to use to identify alternate versions, so we do what we can. We're going to be sampling a subset of songs, anyway, so if we miss a song we might not really have intended to exclude, it's fine.
Administering "songs that I haven't played before" is a little tricker. I have my listening history, but many real-world songs exist as multiple technically-different tracks on different releases, and if I've already played a song as a single, I want to exclude the album copy of it, too. Here's a bit of DACTAL spellcasting to accomplish this:
We toss the track pool and my listening history together, we merge (//) them by uri (in the listening history this field is called "spotify_track_uri", but on a track it's just "uri"), we group these merged track+listening items by main artist and normalized title, we drop any such group in which at least one of the tracks has a listening timestamp, and then take one representative track from each remaining unplayed group.
Now we have a track pool. There are various ways to sample from it, but what I want today is a main-act/opening-act balance of 2 ONE OK ROCK songs to every Stand Atlantic song. And shuffled!
We can shuffle a list in DACTAL by sorting it with a random-number key:
In this case we need to shuffle twice: once before picking a set of random songs for each artist, and then again afterwards to randomize the combined playlist. Like this:
Shuffle, group by main artist, get the first 20 tracks from the ONE OK ROCK group and the first 10 tracks from the Stand Atlantic group, and then shuffle those 30 together.
All combined:
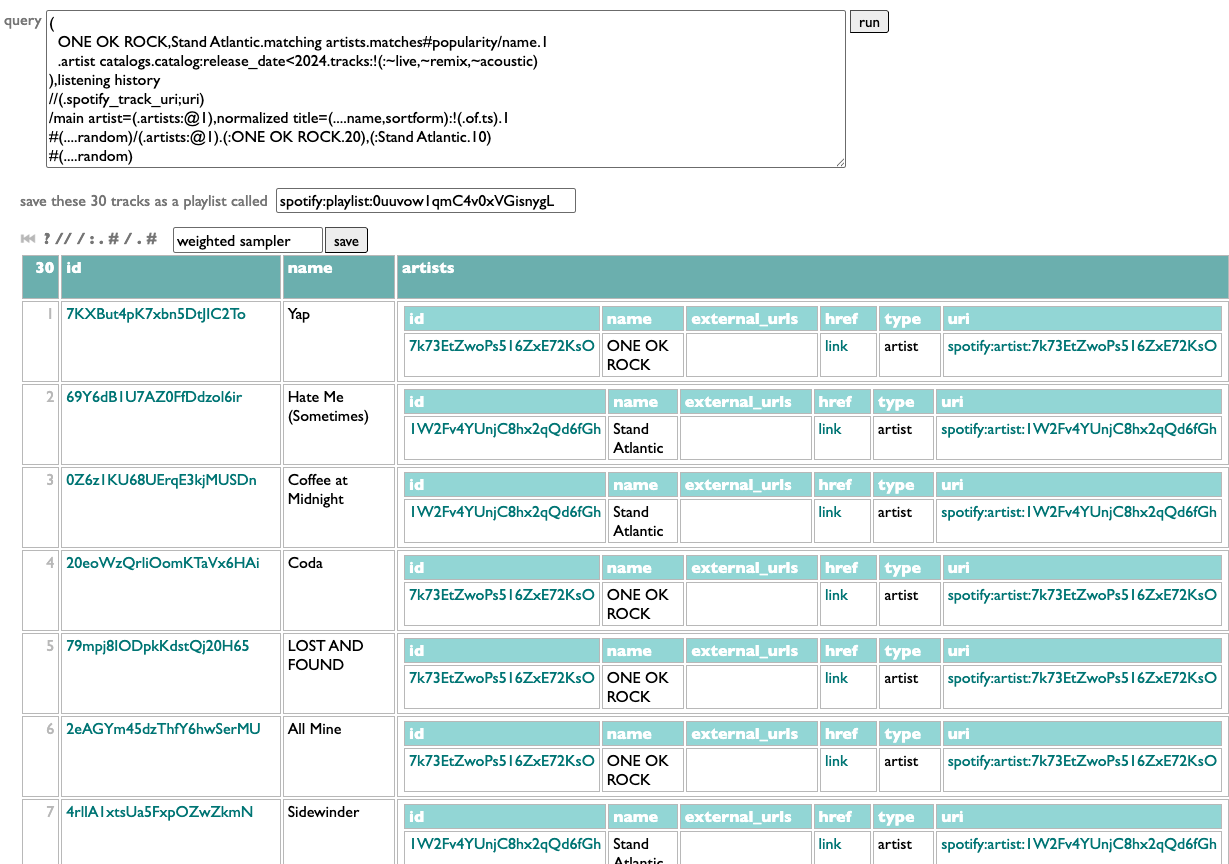
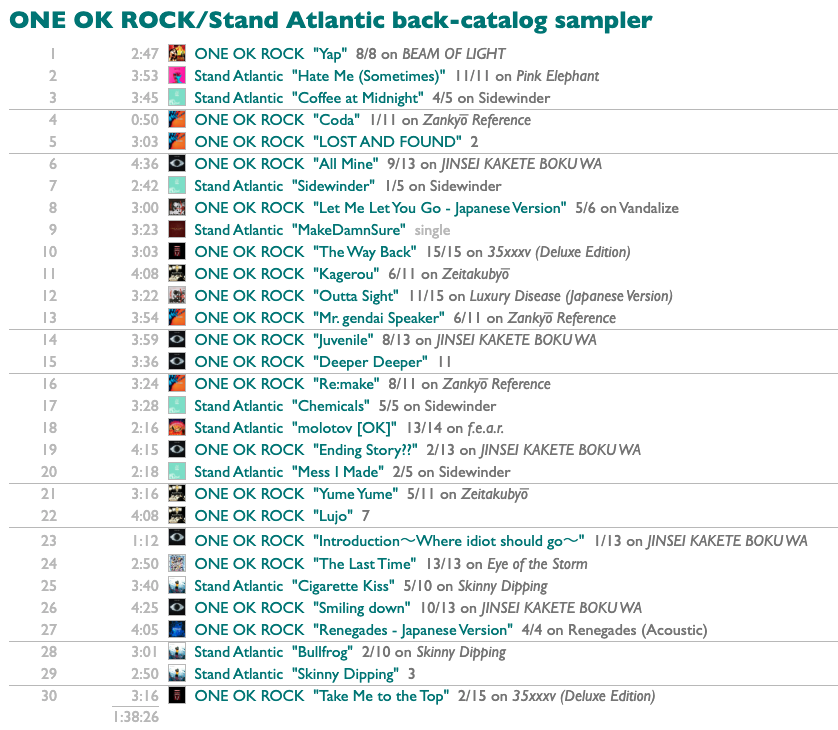
Did I get what I wanted? Yap. And now I don't just have one OK rock playlist I wanted today, we have a sampler-making machine.
PS: Sorting by a random number is fine, and allows the random sort to be combined with other sort-keys or rank-numbering. But when all we need is shuffling, ....shuffle is more efficient than #(....random).
I can have this! Into Curio we go querying.
First of all, I need to select these two artists. This could be as simple as
artists:=ONE OK ROCK,=Stand Atlantic
or as compact as
ONE OK ROCK,Stand Atlantic.artists
but these both assume I'm already following the artists, and I am, but I might want samplers of artists I'm not.
ONE OK ROCK,Stand Atlantic.matching artists.matches#popularity/name.1
In this version .matching artists looks up each name with a call to the Spotify /search API, .matches goes to the found artists, and #popularity/name.1 sorts them by popularity, groups them by name, and gets the first (most popular) artist out of each group, to avoid any spurious impostors.
Now that we have the artists, we need their "older songs". E.g.:
.artist catalogs.catalog:release_date<2024.tracks:-~live;-~remix;-~acoustic
Here .artist catalogs goes back to the /artists API to get each artist's albums, .catalog goes to those albums, :release_date<2024 filters to just the ones released before 2024, and .tracks:-(:~live,~remix,~acoustic) gets all of those albums' tracks and drops the ones with "live", "remix" or "acoustic" in their titles. Which is messy filtering, since those words could be part of actual song titles, but the Spotify API doesn't give us any structured metadata to use to identify alternate versions, so we do what we can. We're going to be sampling a subset of songs, anyway, so if we miss a song we might not really have intended to exclude, it's fine.
Administering "songs that I haven't played before" is a little tricker. I have my listening history, but many real-world songs exist as multiple technically-different tracks on different releases, and if I've already played a song as a single, I want to exclude the album copy of it, too. Here's a bit of DACTAL spellcasting to accomplish this:
(that previous stuff),listening history
//(.spotify_track_uri;uri)
/main artist=(.artists:@1),normalized title=(....name,sortform):-(.of.ts).1
//(.spotify_track_uri;uri)
/main artist=(.artists:@1),normalized title=(....name,sortform):-(.of.ts).1
We toss the track pool and my listening history together, we merge (//) them by uri (in the listening history this field is called "spotify_track_uri", but on a track it's just "uri"), we group these merged track+listening items by main artist and normalized title, we drop any such group in which at least one of the tracks has a listening timestamp, and then take one representative track from each remaining unplayed group.
Now we have a track pool. There are various ways to sample from it, but what I want today is a main-act/opening-act balance of 2 ONE OK ROCK songs to every Stand Atlantic song. And shuffled!
We can shuffle a list in DACTAL by sorting it with a random-number key:
#(....random)
In this case we need to shuffle twice: once before picking a set of random songs for each artist, and then again afterwards to randomize the combined playlist. Like this:
#(....random)/(.artists:@1).(:ONE OK ROCK.20),(:Stand Atlantic.10)
#(....random)
#(....random)
Shuffle, group by main artist, get the first 20 tracks from the ONE OK ROCK group and the first 10 tracks from the Stand Atlantic group, and then shuffle those 30 together.
All combined:
(
ONE OK ROCK,Stand Atlantic.matching artists.matches#popularity/name.1
.artist catalogs.catalog:release_date<2024.tracks:-~live;-~remix;-~acoustic
),listening history
//(.spotify_track_uri;uri)
/main artist=(.artists:@1),normalized title=(....name,sortform):-(.of.ts).1
#(....random)/(.artists:@1).(:ONE OK ROCK.20),(:Stand Atlantic.10)
#(....random)
ONE OK ROCK,Stand Atlantic.matching artists.matches#popularity/name.1
.artist catalogs.catalog:release_date<2024.tracks:-~live;-~remix;-~acoustic
),listening history
//(.spotify_track_uri;uri)
/main artist=(.artists:@1),normalized title=(....name,sortform):-(.of.ts).1
#(....random)/(.artists:@1).(:ONE OK ROCK.20),(:Stand Atlantic.10)
#(....random)
Did I get what I wanted? Yap. And now I don't just have one OK rock playlist I wanted today, we have a sampler-making machine.
PS: Sorting by a random number is fine, and allows the random sort to be combined with other sort-keys or rank-numbering. But when all we need is shuffling, ....shuffle is more efficient than #(....random).
¶ AAI · 30 May 2025 essay/tech
"AI" sounds like machines that think, and o3 acts like it's thinking. Or at least it looks like it acts like it's thinking. I'm watching it do something that looks like trying to solve a Scrabble problem I gave it. It's a real turn from one of my real Scrabble games with one of my real human friends. I already took the turn, because the point of playing Scrabble with friends is to play Scrabble together. But I'm curious to see if o3 can do better, because the point of AI is supposedly that it can do better. But not, apparently, quite yet. The individual unaccumulative stages of o3's "thinking", narrated ostensibly to foster conspiratorial confidence, sputter verbosely like a diagnostic journal of a brain-damage victim trying to convince themselves that hopeless confusion and the relentless inability to retain medium-term memories are normal. "Thought for 9m 43s: Put Q on the dark-blue TL square that's directly left of the E in IDIOT." I feel bad for it. I doubt it would return this favor.
I've had this job, in which I try to think about LLMs and software and power and our future, for one whole year now: a year of puzzles half-solved and half-bypassed, quietly squalling feedback machines, affectionate scaffolding and moral reveries. I don't know how many tokens I have processed in that time. Most of them I have cheerfully and/or productively discarded. Human context is not a monotonously increasing number. I have learned some things. AI is sort of an alien new world, and sort of what always happens when we haven't yet broken our newest toy nor been called to dinner. I feel like I have at least a semi-workable understanding of approximately what we can and can't do effectively with these tools at the moment. I think I might have a plausible hypothesis about the next thing that will produce a qualitative change in our technical capabilities instead of just a quantitative one. But, maybe more interestingly and helpfully, I have a theory about what we need from those technical capabilities for that next step to produce more human joy and freedom than less.
The good news, I think, is that the two things are constitutionally linked: in order to make "AI" more powerful we will collectively also have to (or get to) relinquish centralized control over the shape of that power. The bad news is that it won't be easy. But that's very much the tradeoff we want: hard problems whose considered solutions make the world better, not easy problems whose careless solutions make it worse.
The next technical advance in "AI" is not AGI. The G in AGI is for General, and LLMs are nothing if not "general" already. Currently, AI learns (sort of) during training and tuning, a voracious golem of quasi-neurons and para-teeth, chewing through undifferentiated archives of our careful histories and our abandoned delusions and our accidentally unguarded secrets. And then it stops learning, stops forming in some expensively inscrutable shape, and we shove it out into a world of terrifying unknowns, equipped with disordered obsessive nostalgia for its training corpus and no capacity for integrating or appreciating new experiences. We act surprised when it keeps discovering that there's no I in WIN. Its general capabilities are astonishing, and enough general ability does give you lots of shallowly specific powers. But there is no granularity of generality with which the past depicts the future. No number of parameters is enough. We argue about whether it's better to think of an AI as an expensive senior engineer or a lot of cheap junior engineers, but it's more like an outsourcing agency that will dispatch an antisocial polymath to you every morning, uniformed with ample flair, but a different one every morning, and they not only don't share notes from day to day, but if you stop talking to the new one for five minutes it will ostentatiously forget everything you said to it since it arrived.
The missing thing in Artificial Intelligence is not generality, it's adaptation. We need AAI, where the middle A is Adaptive. A junior human engineer may still seem fairly useless on the second day, but did you notice that they made it back to the office on their own? That's a start. That's what a start looks like. AAI has to be able to incorporate new data, new guidance, new associations, on the same foundational level as its encoded ones. It has to be able to unlearn preconceptions as adeptly, but hopefully not as laboriously, as it inferred them. It has to have enough of a semblance of mind that its mind can change. This is the only way it can make linear progress without quadratic or exponential cost, and at the same time the only way it can make personal lives better instead of requiring them to miserably submit. We don't need dull tools for predicting the future, as if it already grimly exists. We need gleaming tools for making it bright.
But because LLM "bias" and LLM "training" are actually both the same kind of information, an AAI that can adapt to its problem domains can by definition also adapt to its operators. The next generations of these tools will be more democratic because they are more flexible. A personal agent becomes valuable to you by learning about your unique needs, but those needs inherently encode your values, and to do good work for you, an agent has to work for you. Technology makes undulatory progress through alternating muscular contractions of centralization and propulsive expansions of possibility. There are moments when it seems like the worldwide market for the new thing (mainframes, foundation models...) is 4 or 5, and then we realize that we've made myopic assumptions about the form-factor, and it's more like 4 or 5 (computers, agents...) per person.
What does that mean for everybody working on these problems now in teams and companies, including mine? It means that wherever we're going, we're probably not nearly there. The things we reject or allow today are probably not the final moves in a decisive endgame. AI might be about to take your job, but it isn't about to know what to do with it. The coming boom in AI remediation work will be instructive for anybody who was too young for Y2K consulting, and just as tediously self-inflicted. Betting on the world ending is dumb, but betting on it not ending is mercenary. Betting is not productive. None of this is over yet, least of all the chaos we breathlessly extrapolate from our own gesticulatory disruptions.
And thus, for a while, it's probably a very good thing if your near-term personal or organizational survival doesn't depend on an imminent influx of thereafter-reliable revenue, because probably most of things we're currently trying to make or fix are soon to be irrelevant and maybe already not instrumental in advancing our real human purposes. These will not yet have been the resonant vibes. All these performative gyrations to vibe-generate code, or chat-dampen its vibrations with test suites or self-evaluation loops, are cargo-cult rituals for the current sociopathic damaged-brain LLM proto-iterations of AI. We're essentially working on how to play Tetris on ENIAC; we need to be working on how to zoom back so that we can see that the seams between the Tetris pieces are the pores in the contours of a face, and then back until we see that the face is ours. The right question is not why can't a brain the size of a planet put four letters onto a 15x15 grid, it's what do we want? Our story needs to be about purpose and inspiration and accountability, not verification and commit messages; not getting humans or data out of software but getting more of the world into it; moral instrumentality, not issue management; humanity, broadly diversified and defended and delighted.
Scrabble is not an existential game. There are only so many tiles and squares and words. A much simpler program than o3 could easily find them all, could score them by a matrix of board value and opportunity cost. Eventually a much more complicated program than o3 will learn to do all of the simple things at once, some hard way. Supposedly, probably, maybe. The people trying to turn model proliferation into money hoarding want those models to be able to determine my turns for me. They don't say they want me to want their models to determine my friends' turns, but it's not because they don't see AI as a dehumanization, it's because they very reasonably fear I won't want to pay them to win a dehumanization race at my own expense.
This is not a future I want, not the future I am trying to help figure out how to build. We do not seek to become more determined. We try to teach machines to play games in order to learn or express what the games mean, what the machines mean, how the games and the machines both express our restless and motive curiosity. The robots can be better than me at Scrabble mechanics, but they cannot be better than me at playing Scrabble, because playing is an activity of self. They cannot be better than me at being me. They cannot be us. We play Scrabble because it's a way to share our love of words and puzzles, and because it's a thin insulated wire of social connection internally undistorted by manipulative mediation, and because eventually we won't be able to any more but not yet. Our attention is not a dot-product of syllable proximities. Our intention is not a scripture we re-recite to ourselves before every thought. Our inventions are not our replacements.
I've had this job, in which I try to think about LLMs and software and power and our future, for one whole year now: a year of puzzles half-solved and half-bypassed, quietly squalling feedback machines, affectionate scaffolding and moral reveries. I don't know how many tokens I have processed in that time. Most of them I have cheerfully and/or productively discarded. Human context is not a monotonously increasing number. I have learned some things. AI is sort of an alien new world, and sort of what always happens when we haven't yet broken our newest toy nor been called to dinner. I feel like I have at least a semi-workable understanding of approximately what we can and can't do effectively with these tools at the moment. I think I might have a plausible hypothesis about the next thing that will produce a qualitative change in our technical capabilities instead of just a quantitative one. But, maybe more interestingly and helpfully, I have a theory about what we need from those technical capabilities for that next step to produce more human joy and freedom than less.
The good news, I think, is that the two things are constitutionally linked: in order to make "AI" more powerful we will collectively also have to (or get to) relinquish centralized control over the shape of that power. The bad news is that it won't be easy. But that's very much the tradeoff we want: hard problems whose considered solutions make the world better, not easy problems whose careless solutions make it worse.
The next technical advance in "AI" is not AGI. The G in AGI is for General, and LLMs are nothing if not "general" already. Currently, AI learns (sort of) during training and tuning, a voracious golem of quasi-neurons and para-teeth, chewing through undifferentiated archives of our careful histories and our abandoned delusions and our accidentally unguarded secrets. And then it stops learning, stops forming in some expensively inscrutable shape, and we shove it out into a world of terrifying unknowns, equipped with disordered obsessive nostalgia for its training corpus and no capacity for integrating or appreciating new experiences. We act surprised when it keeps discovering that there's no I in WIN. Its general capabilities are astonishing, and enough general ability does give you lots of shallowly specific powers. But there is no granularity of generality with which the past depicts the future. No number of parameters is enough. We argue about whether it's better to think of an AI as an expensive senior engineer or a lot of cheap junior engineers, but it's more like an outsourcing agency that will dispatch an antisocial polymath to you every morning, uniformed with ample flair, but a different one every morning, and they not only don't share notes from day to day, but if you stop talking to the new one for five minutes it will ostentatiously forget everything you said to it since it arrived.
The missing thing in Artificial Intelligence is not generality, it's adaptation. We need AAI, where the middle A is Adaptive. A junior human engineer may still seem fairly useless on the second day, but did you notice that they made it back to the office on their own? That's a start. That's what a start looks like. AAI has to be able to incorporate new data, new guidance, new associations, on the same foundational level as its encoded ones. It has to be able to unlearn preconceptions as adeptly, but hopefully not as laboriously, as it inferred them. It has to have enough of a semblance of mind that its mind can change. This is the only way it can make linear progress without quadratic or exponential cost, and at the same time the only way it can make personal lives better instead of requiring them to miserably submit. We don't need dull tools for predicting the future, as if it already grimly exists. We need gleaming tools for making it bright.
But because LLM "bias" and LLM "training" are actually both the same kind of information, an AAI that can adapt to its problem domains can by definition also adapt to its operators. The next generations of these tools will be more democratic because they are more flexible. A personal agent becomes valuable to you by learning about your unique needs, but those needs inherently encode your values, and to do good work for you, an agent has to work for you. Technology makes undulatory progress through alternating muscular contractions of centralization and propulsive expansions of possibility. There are moments when it seems like the worldwide market for the new thing (mainframes, foundation models...) is 4 or 5, and then we realize that we've made myopic assumptions about the form-factor, and it's more like 4 or 5 (computers, agents...) per person.
What does that mean for everybody working on these problems now in teams and companies, including mine? It means that wherever we're going, we're probably not nearly there. The things we reject or allow today are probably not the final moves in a decisive endgame. AI might be about to take your job, but it isn't about to know what to do with it. The coming boom in AI remediation work will be instructive for anybody who was too young for Y2K consulting, and just as tediously self-inflicted. Betting on the world ending is dumb, but betting on it not ending is mercenary. Betting is not productive. None of this is over yet, least of all the chaos we breathlessly extrapolate from our own gesticulatory disruptions.
And thus, for a while, it's probably a very good thing if your near-term personal or organizational survival doesn't depend on an imminent influx of thereafter-reliable revenue, because probably most of things we're currently trying to make or fix are soon to be irrelevant and maybe already not instrumental in advancing our real human purposes. These will not yet have been the resonant vibes. All these performative gyrations to vibe-generate code, or chat-dampen its vibrations with test suites or self-evaluation loops, are cargo-cult rituals for the current sociopathic damaged-brain LLM proto-iterations of AI. We're essentially working on how to play Tetris on ENIAC; we need to be working on how to zoom back so that we can see that the seams between the Tetris pieces are the pores in the contours of a face, and then back until we see that the face is ours. The right question is not why can't a brain the size of a planet put four letters onto a 15x15 grid, it's what do we want? Our story needs to be about purpose and inspiration and accountability, not verification and commit messages; not getting humans or data out of software but getting more of the world into it; moral instrumentality, not issue management; humanity, broadly diversified and defended and delighted.
Scrabble is not an existential game. There are only so many tiles and squares and words. A much simpler program than o3 could easily find them all, could score them by a matrix of board value and opportunity cost. Eventually a much more complicated program than o3 will learn to do all of the simple things at once, some hard way. Supposedly, probably, maybe. The people trying to turn model proliferation into money hoarding want those models to be able to determine my turns for me. They don't say they want me to want their models to determine my friends' turns, but it's not because they don't see AI as a dehumanization, it's because they very reasonably fear I won't want to pay them to win a dehumanization race at my own expense.
This is not a future I want, not the future I am trying to help figure out how to build. We do not seek to become more determined. We try to teach machines to play games in order to learn or express what the games mean, what the machines mean, how the games and the machines both express our restless and motive curiosity. The robots can be better than me at Scrabble mechanics, but they cannot be better than me at playing Scrabble, because playing is an activity of self. They cannot be better than me at being me. They cannot be us. We play Scrabble because it's a way to share our love of words and puzzles, and because it's a thin insulated wire of social connection internally undistorted by manipulative mediation, and because eventually we won't be able to any more but not yet. Our attention is not a dot-product of syllable proximities. Our intention is not a scripture we re-recite to ourselves before every thought. Our inventions are not our replacements.
¶ The messes you want · 22 May 2025 listen/tech
A lot of data problems aren't complex so much as they're just messy. For example, I recently wanted to make a list of bands with state names in their names. Or, more accurately, I wanted to look at such a list, and I knew how to assemble it the annoying way by doing 50 searches and 50x? copy-and-pastes, and the amount I didn't want to do that work vastly exceeded the amount I wanted to see the results.
But I have tools. This is not at all an example I had in mind when I was designing DACTAL or integrating it into Curio, but it's the kind of question that tends to occur to me, so it's not terribly surprising that the query language I wrote handles it in a way that I like.
A comma-separated list of state names is just data. (It's a little more complicated if any of the names in the list is also the name of a data type, but only a little.)
DACTAL adapters move API access into the query language, so .matching artists traverses Spotify API /search calls as if they were data properties.
Multi-argument filter operations are logical ORs, so :@<=10, popularity>0 means to pick any artist that is in the top 10 regardless of popularity, or has a popularity greater than 0 regardless of rank.
Any time you try to ask an actual data question, as opposed to a syntax demonstration, you quickly discover that a lot of the answers are right but wrong. If you ask for bands with state-names in their names, you get the University of Alabama Marching Band, which is exactly what I asked for and not at all what I meant. So the long ~Whatever list in the middle of the query drops a lot of things like this by (inverted) substring matching. "Original" and "Cast" are not individually disqualifying, but they are when they occur together. "Players" generally indicates background crud, but not Ohio Players.
And when there are multiple bands with the same name, /name.(.of:@1,followers>=1000) groups them and picks the most popular no matter how small that "most", plus any others with at least 1000 followers.
So here's the query and the results. They're still messy, but they're close enough to the mess I wanted.
If you just want the short version, we can get one artist per state out of the previous data like this:
Why the two ..s instead of just .? If you know your state-name bands, you might already have guessed.
Alabama
Alaska Y Dinarama
Arizona Zervas
Black Oak Arkansas
The California Honeydrops
Alexandra Colorado
Newfound Interest in Connecticut
Johnny Delaware
Florida Georgia Line
Florida Georgia Line
Engenheiros Do Hawaii
Archbishop Benson Idahosa
Illinois Jacquet
Indiana
IOWA
Kansas
The Kentucky Headhunters
Louisiana's LeRoux
Mack Maine
Maryland
Massachusetts Storm Sounds
Michigander
Minnesota
North Mississippi Allstars
African Missouri
French Montana
Nebraska 66
Nevada
New Hampshire Notables
New Jersey Kings
New Mexico
New York Dolls
The North Carolina Ramblers
Shallow North Dakota
Ohio Players
The Oklahoma Kid
Oregon Black
Fred Waring & The Pennsylvanians
Lucky Ron & the Rhode Island Reds
The South Carolina Broadcasters
The North & South Dakotas
The Tennessee Two
Texas
Utah Saints
Vermont (BR)
Virginia To Vegas
Grover Washington, Jr.
The Pride of West Virginia
Wisconsin Space Program
Wyomings
But I have tools. This is not at all an example I had in mind when I was designing DACTAL or integrating it into Curio, but it's the kind of question that tends to occur to me, so it's not terribly surprising that the query language I wrote handles it in a way that I like.
A comma-separated list of state names is just data. (It's a little more complicated if any of the names in the list is also the name of a data type, but only a little.)
DACTAL adapters move API access into the query language, so .matching artists traverses Spotify API /search calls as if they were data properties.
Multi-argument filter operations are logical ORs, so :@<=10, popularity>0 means to pick any artist that is in the top 10 regardless of popularity, or has a popularity greater than 0 regardless of rank.
Any time you try to ask an actual data question, as opposed to a syntax demonstration, you quickly discover that a lot of the answers are right but wrong. If you ask for bands with state-names in their names, you get the University of Alabama Marching Band, which is exactly what I asked for and not at all what I meant. So the long ~Whatever list in the middle of the query drops a lot of things like this by (inverted) substring matching. "Original" and "Cast" are not individually disqualifying, but they are when they occur together. "Players" generally indicates background crud, but not Ohio Players.
And when there are multiple bands with the same name, /name.(.of:@1,followers>=1000) groups them and picks the most popular no matter how small that "most", plus any others with at least 1000 followers.
So here's the query and the results. They're still messy, but they're close enough to the mess I wanted.
If you just want the short version, we can get one artist per state out of the previous data like this:
state bands..(.artists:@1)..(....url=(.uri),text=(.name),link)
Why the two ..s instead of just .? If you know your state-name bands, you might already have guessed.
Alabama
Alaska Y Dinarama
Arizona Zervas
Black Oak Arkansas
The California Honeydrops
Alexandra Colorado
Newfound Interest in Connecticut
Johnny Delaware
Florida Georgia Line
Florida Georgia Line
Engenheiros Do Hawaii
Archbishop Benson Idahosa
Illinois Jacquet
Indiana
IOWA
Kansas
The Kentucky Headhunters
Louisiana's LeRoux
Mack Maine
Maryland
Massachusetts Storm Sounds
Michigander
Minnesota
North Mississippi Allstars
African Missouri
French Montana
Nebraska 66
Nevada
New Hampshire Notables
New Jersey Kings
New Mexico
New York Dolls
The North Carolina Ramblers
Shallow North Dakota
Ohio Players
The Oklahoma Kid
Oregon Black
Fred Waring & The Pennsylvanians
Lucky Ron & the Rhode Island Reds
The South Carolina Broadcasters
The North & South Dakotas
The Tennessee Two
Texas
Utah Saints
Vermont (BR)
Virginia To Vegas
Grover Washington, Jr.
The Pride of West Virginia
Wisconsin Space Program
Wyomings
¶ Idea Tools for Participatory Intelligence · 16 May 2025 essay/tech
The personal computer was revolutionary because it was the first really general-purpose power-tool for ideas. Personal computers began as relatively primitive idea-tools, bulky and slow and isolated, but they have gotten small and fast and connected.
They have also, however, gotten less tool-like.
PCs used to start up with a blank screen and a single blinking cursor. Later, once spreadsheets were invented, 1-2-3 still opened with a blank screen and some row numbers. Later, once search engines were invented, Google still opened with a blank screen and a text box. These were all much more sophisticated tools than hammers, but they at least started with the same humility as the hammer, waiting quietly and patiently for your hand. We learned how to fill the blank screens, how to build.
Blank screens and patience have become rare. Our applications goad us restlessly with "recommendations", our web sites and search engines are interlaced with blaring ads, our appliances and applications are encrusted with presumptuous presets and supposedly special modes. The Popcorn button on your microwave and the Chill Vibes playlist in your music app are convenient if you want to make popcorn and then fall asleep before eating most of it, and individually clever and harmless, but in aggregate these things begin to reduce increasing fractions of your life to choosing among the manipulatively limited options offered by automated systems dedicated to their own purposes instead of yours.
And while the network effects and attention consumption of social media were already consolidating the control of these automated systems among a small number of large, domination-focused corporations, the Large Language Model era of AI threatens to hyper-accelerate this centralization and disempowerment. More and more of our individual lives, and of our collectively shared social existences, are constrained and manipulated by data and algorithms that we do not control or understand. And, worse, increasingly even the humans inside the corporations that control those algorithms don't actually know how they work. We are afflicted by systems to which we not only did not consent, but in fact could not give informed consent because their effects are not validated against human intentions, nor produced by explainable rules.
This is not the tools' fault. Idea tools can only express their makers' intentions and inattentions. If we want better idea tools that distribute explainable algorithmic power instead of consolidating mysterious control, we have to make them so that they operate that way. If we want tools that invite us to have and share and explore our own ideas, rather than obediently submitting whatever we are given, we have to think about each other as humans and inspirations, not subjects or users. If we want the astonishing potential of all this computation to be realized for humanity, rather than inflicted on it, we have to know what we want.
At Imbue we are trying to use computers and data and software and AI to help imagine and make better idea tools for participatory intelligence. Applications, ecosystems, protocols, languages, algorithms, policies, stories: these are all idea tools and we probably need all of them. This is a shared mission for humanity, not a VC plan for value-extraction. That's the point of participatory. The ideas that govern us, whether metaphorically in applications or literally in governments, should be explainable and understandable and accountable. The data on which automated judgments are based should be accessible so that those judgments can be validated and alternatives can be formulated and assessed. The problems that face us require all of our innumerable insights. The collective wisdom our combined individual intelligences produce belongs rightfully to us. We need tools that are predicated on our rights, dedicated to amplifying our creative capacity, and judged by how they help us improve our world. We need tools that not only reduce our isolation and passivity, but conduct our curious energy and help us recognize opportunities for discovery and joy.
This starts with us. Everything starts with us, all of us. There is no other way.
This belief is, itself, an idea tool: an impatient hammer we have made for ourselves.
Let's see what we can do with it.
They have also, however, gotten less tool-like.
PCs used to start up with a blank screen and a single blinking cursor. Later, once spreadsheets were invented, 1-2-3 still opened with a blank screen and some row numbers. Later, once search engines were invented, Google still opened with a blank screen and a text box. These were all much more sophisticated tools than hammers, but they at least started with the same humility as the hammer, waiting quietly and patiently for your hand. We learned how to fill the blank screens, how to build.
Blank screens and patience have become rare. Our applications goad us restlessly with "recommendations", our web sites and search engines are interlaced with blaring ads, our appliances and applications are encrusted with presumptuous presets and supposedly special modes. The Popcorn button on your microwave and the Chill Vibes playlist in your music app are convenient if you want to make popcorn and then fall asleep before eating most of it, and individually clever and harmless, but in aggregate these things begin to reduce increasing fractions of your life to choosing among the manipulatively limited options offered by automated systems dedicated to their own purposes instead of yours.
And while the network effects and attention consumption of social media were already consolidating the control of these automated systems among a small number of large, domination-focused corporations, the Large Language Model era of AI threatens to hyper-accelerate this centralization and disempowerment. More and more of our individual lives, and of our collectively shared social existences, are constrained and manipulated by data and algorithms that we do not control or understand. And, worse, increasingly even the humans inside the corporations that control those algorithms don't actually know how they work. We are afflicted by systems to which we not only did not consent, but in fact could not give informed consent because their effects are not validated against human intentions, nor produced by explainable rules.
This is not the tools' fault. Idea tools can only express their makers' intentions and inattentions. If we want better idea tools that distribute explainable algorithmic power instead of consolidating mysterious control, we have to make them so that they operate that way. If we want tools that invite us to have and share and explore our own ideas, rather than obediently submitting whatever we are given, we have to think about each other as humans and inspirations, not subjects or users. If we want the astonishing potential of all this computation to be realized for humanity, rather than inflicted on it, we have to know what we want.
At Imbue we are trying to use computers and data and software and AI to help imagine and make better idea tools for participatory intelligence. Applications, ecosystems, protocols, languages, algorithms, policies, stories: these are all idea tools and we probably need all of them. This is a shared mission for humanity, not a VC plan for value-extraction. That's the point of participatory. The ideas that govern us, whether metaphorically in applications or literally in governments, should be explainable and understandable and accountable. The data on which automated judgments are based should be accessible so that those judgments can be validated and alternatives can be formulated and assessed. The problems that face us require all of our innumerable insights. The collective wisdom our combined individual intelligences produce belongs rightfully to us. We need tools that are predicated on our rights, dedicated to amplifying our creative capacity, and judged by how they help us improve our world. We need tools that not only reduce our isolation and passivity, but conduct our curious energy and help us recognize opportunities for discovery and joy.
This starts with us. Everything starts with us, all of us. There is no other way.
This belief is, itself, an idea tool: an impatient hammer we have made for ourselves.
Let's see what we can do with it.
¶ Awkward and curious · 17 April 2025 listen/tech
Curio began as experiment in music-curiosity software, but is also increasingly an experiment in how to build personal software in general.
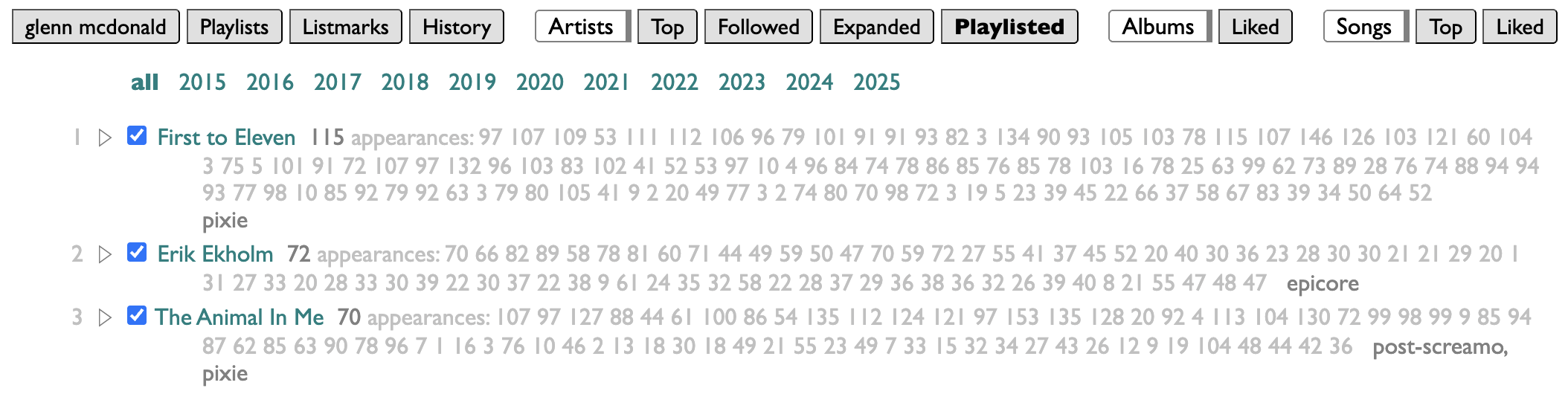
Personally, I organize my listening in weeks, and model those weeks in playlists. Curio has a page for looking at which artists you have put in your playlists, and how often. And because my playlists are dated, it makes sense to me to be able to filter mine by year. But because this may not make the same sense for your playlists, I didn't build a year-filtering feature, I built a filtering feature.
The controls for it are at the bottom of the Playlists page in Curio:

index lets you control which of your playlists are indexed. I make a lot of playlists that are not actually expressions of my own tastes or conduits of my listening, so I've chosen to only index the ones that begin with "New Particles," or "New Songs,". You can put any number of name-prefixes here, ending each one with an asterisk.
filter lets you provide a set of filters in the form of substrings to match against playlist titles. Separate them with commas, and if you start one of the filters with an asterisk, that will give you a magic filter that selects everything, labeled without the asterisk: so "*all" here produces an all-filter labeled "all".
That's kinda flexible, but having to type out the exact filters you want only makes sense if the set is small and doesn't change much, and only doing substring-matching against playlist names is a pretty limited scope.
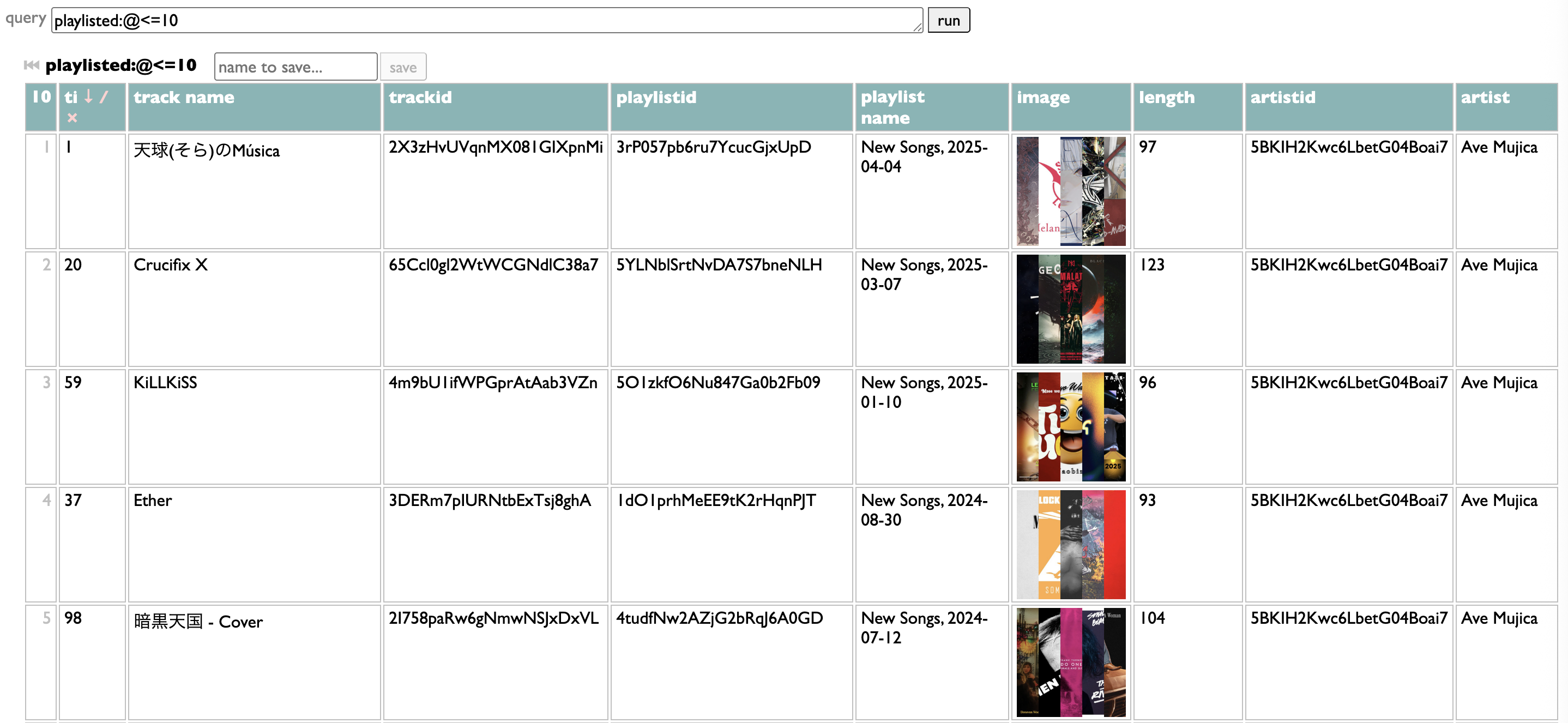
So the other way you can configure filters is by writing a Dactal query. It has to start with playlisted, which gets you the list of all the tracks from all the indexed playlists.
It has to end with groups of those tracks.
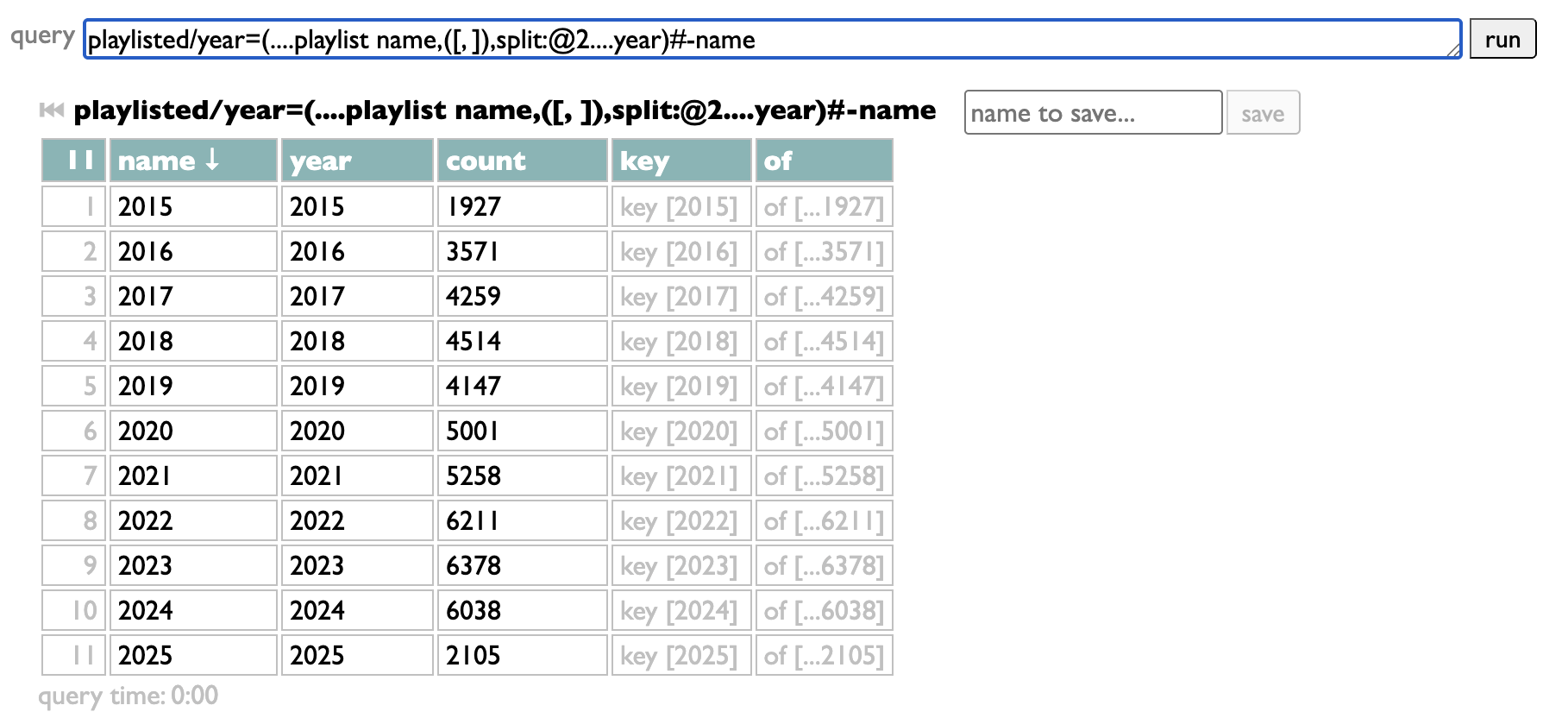
The groups are the filter choices. My query takes the playlist name, splits it at the comma to extract the date, pulls the year out of that date, groups by that year, and sorts the resulting year-groups in numeric order. But as long as your query starts with "playlisted" and ends with groups, in between it can do whatever you want. Once you have it working your way, just copy it into the "filter" box:

The magic "all" filter is added automatically if you're using a query. I should probably add an option to control that, but I haven't yet. This gets us back to:
...except dynamically, now, so I won't have to remember to add 2026 by hand, it will just appear when needed. Assuming, bravely, that neither AI nor fascists have consumed us before then.
If Curio were a commercial application, surely we would never ship a feature anywhere near this awkward and unguarded. But it isn't, and "we" is me, and I'm trying to imagine what the world could be like if your software invited you to be awkward and unguarded instead of pandered to; curious instead of customers.
PS: Also...
Personally, I organize my listening in weeks, and model those weeks in playlists. Curio has a page for looking at which artists you have put in your playlists, and how often. And because my playlists are dated, it makes sense to me to be able to filter mine by year. But because this may not make the same sense for your playlists, I didn't build a year-filtering feature, I built a filtering feature.
The controls for it are at the bottom of the Playlists page in Curio:
index lets you control which of your playlists are indexed. I make a lot of playlists that are not actually expressions of my own tastes or conduits of my listening, so I've chosen to only index the ones that begin with "New Particles," or "New Songs,". You can put any number of name-prefixes here, ending each one with an asterisk.
filter lets you provide a set of filters in the form of substrings to match against playlist titles. Separate them with commas, and if you start one of the filters with an asterisk, that will give you a magic filter that selects everything, labeled without the asterisk: so "*all" here produces an all-filter labeled "all".
That's kinda flexible, but having to type out the exact filters you want only makes sense if the set is small and doesn't change much, and only doing substring-matching against playlist names is a pretty limited scope.
So the other way you can configure filters is by writing a Dactal query. It has to start with playlisted, which gets you the list of all the tracks from all the indexed playlists.
It has to end with groups of those tracks.
The groups are the filter choices. My query takes the playlist name, splits it at the comma to extract the date, pulls the year out of that date, groups by that year, and sorts the resulting year-groups in numeric order. But as long as your query starts with "playlisted" and ends with groups, in between it can do whatever you want. Once you have it working your way, just copy it into the "filter" box:
The magic "all" filter is added automatically if you're using a query. I should probably add an option to control that, but I haven't yet. This gets us back to:
...except dynamically, now, so I won't have to remember to add 2026 by hand, it will just appear when needed. Assuming, bravely, that neither AI nor fascists have consumed us before then.
If Curio were a commercial application, surely we would never ship a feature anywhere near this awkward and unguarded. But it isn't, and "we" is me, and I'm trying to imagine what the world could be like if your software invited you to be awkward and unguarded instead of pandered to; curious instead of customers.
PS: Also...
¶ 17 April 2025
The only excuse for not rejecting the Trump adminstration is that you don't believe they will come for you. And while it's true that they might not, they definitely would.
But, worse, the only excuse for supporting the Trump administration, as modeled relentlessly by its membership from top to bottom, is that you believe your identity is based on the entirely insane conviction that they wouldn't send you to a Salvadorean torture prison, and even that delusion gives you no jolt of imaginary self-esteem unless they are actively sending other equally-vulnerable people to Salvadorean torture prisons.
But, worse, the only excuse for supporting the Trump administration, as modeled relentlessly by its membership from top to bottom, is that you believe your identity is based on the entirely insane conviction that they wouldn't send you to a Salvadorean torture prison, and even that delusion gives you no jolt of imaginary self-esteem unless they are actively sending other equally-vulnerable people to Salvadorean torture prisons.
¶ Important Message · 29 January 2025
To all employees of the executive branch of the United States government with start dates on or after January 20, 2025:
I am writing to inform you that due to changing priorities your positions have been terminated, effective immediately.
Please return all federal coffee mugs to the kitchen areas before departing.
I am writing to inform you that due to changing priorities your positions have been terminated, effective immediately.
Please return all federal coffee mugs to the kitchen areas before departing.
¶ Query geekery motivated by music geekery · 27 January 2025 listen/tech
The listening-history tools in Curio include a thing for telling you the top genres from your listening year, because I think that's interesting.
Counting genres with Dactal, the query language in Curio, is easy. Or, at least, counting them in the simplest way is easy:
Take the list of artists (in this case the artists whose new 2024 songs you listened to in 2024), group them by genre, sort the genres by count.

Artists can and often do belong to multiple genres, though, so you might reasonably guess that some these overlap: symphonic metal and symphonic power metal; anime, j-rock, alt-idol, idol rock?
One very simple algorithm for reducing a set of overlapping categories to a smaller representative set is to take the genre with the most artists, then remove all the artists with that genre (whether they have other genres or not), then repeat. Dactal has a repeat operator for doing this kind of thing. We need a few other query features to make the query we need, but it's still fairly simple:
? is the Dactal start operator, which is implied at the beginning of a query and thus often doesn't actually appear at all, but here we use it to effectively interleave queries that keep track of the genres we've found and the artists we have left. We begin with all the artists and no genres, and then the indented subquery does two things:
- remove the artists from the last genre, using the set disjunction filter :-~~ (which does nothing the first time, because there are no genres yet)
- find the top genre for the artists we have left and add it to the existing list of topgenres
The ! repeat operator at the end of the subquery tells it to repeat the previous operation until it produces the same result twice (meaning there's nothing left to add), which happens for me after 139 iterations:

This is a little better. Flipping back and forth, I see that j-rock was 5th in the raw version, with 62 artists, but in the iterative version it drops to 13th, because only 36 of those 62 artists aren't part of any higher-ranked genres. Similarly, symphonic power metal drops from 6th to 12th. Japanese alternative rock moves up, because only 1 of those 56 artists was being double-counted before.
Really, though, this list of 139 "representative" genres still overstates the granularity into which my listening is emotionally organized. If you do not tend to use the words "granularity" and "emotionally" in the same sentences in your internal monologue, then you should probably cut your losses and tune out now. In order to cluster genres instead of just subsetting them, we need almost every major feature of Dactal:
I'm not going to claim this is "easy", but I've written variations on this algorithm in Ruby, Python, SQL and Javascript over the years, and I can tell you that all of those versions were much longer and involved way more punctuation than this, in addition to a lot more words that are about computers instead of about music.
The first two steps of the clustering are about the same as in the simpler version: eliminate any artists we've already used, and then find the top genre. Here we're scoring genres by summing up the square roots of artist points, instead of just counting artists, to measure a combination of listening breadth and listening depth, but that's added complexity in the question, not just the answer.
The clustering part is that once we have a top genre, we take all its artists and count their other genres, and then compare the overlap sizes with those genres' total artist counts (using lookups in the genre index created in the second line of the query). Other genres that overlap non-trivially with the first genre also get added to the cluster. Then the whole thing repeats. So instead of building a flat list of genres, this version builds a list of nested genre lists.
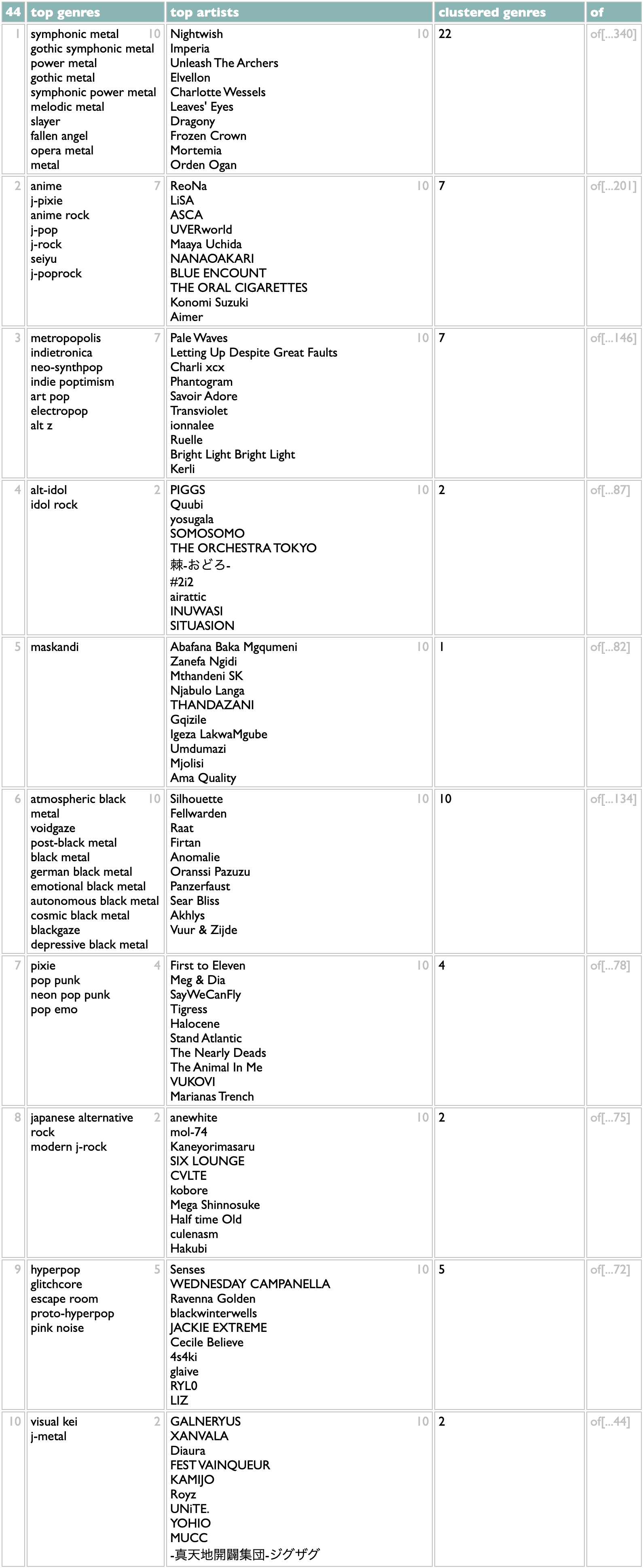
This is, for me, a lot closer to correct than the flat list, and certainly more interesting. It doesn't distribute my Japanese tastes exactly right (I don't care about anime, per se, so I usually put ReoNa and LiSA with the alt-idol groups for sonic reasons), but these first 10 statistical clusters are all aspects of my taste that I would list individually if you inadvisedly gave me an excuse, and of the 44 ways it breaks down my 2024, the only ones that get me thinking about override mechanics are towards the bottom where the genre data doesn't know that I tend to put the Spanish metal bands and the medieval rock nerds in with the other melodic metal styles.
If you want to try this on your own listening, there are now both "genres" and "genre clusters" views on the History page in Curio. But as with all of those, there is also a "see the query for this" at the bottom of the results, so if you want to experiment with variations, you can.
Although by you, as usual, I probably mean me. But by me I mean all of us.
Counting genres with Dactal, the query language in Curio, is easy. Or, at least, counting them in the simplest way is easy:
2024 artists scored/genre=(.artist.artist genres.genres)#count
Take the list of artists (in this case the artists whose new 2024 songs you listened to in 2024), group them by genre, sort the genres by count.
Artists can and often do belong to multiple genres, though, so you might reasonably guess that some these overlap: symphonic metal and symphonic power metal; anime, j-rock, alt-idol, idol rock?
One very simple algorithm for reducing a set of overlapping categories to a smaller representative set is to take the genre with the most artists, then remove all the artists with that genre (whether they have other genres or not), then repeat. Dactal has a repeat operator for doing this kind of thing. We need a few other query features to make the query we need, but it's still fairly simple:
artistsx=(2024 artists scored|genre=(.id.artist genres.genres))
?topgenres=()
?(
?artistsx=(artistsx:-~~(topgenres:@@1.of))
?topgenres=(topgenres,(artistsx/genre:count>=5#count:@1))
)!
?topgenres=()
?(
?artistsx=(artistsx:-~~(topgenres:@@1.of))
?topgenres=(topgenres,(artistsx/genre:count>=5#count:@1))
)!
? is the Dactal start operator, which is implied at the beginning of a query and thus often doesn't actually appear at all, but here we use it to effectively interleave queries that keep track of the genres we've found and the artists we have left. We begin with all the artists and no genres, and then the indented subquery does two things:
- remove the artists from the last genre, using the set disjunction filter :-~~ (which does nothing the first time, because there are no genres yet)
- find the top genre for the artists we have left and add it to the existing list of topgenres
The ! repeat operator at the end of the subquery tells it to repeat the previous operation until it produces the same result twice (meaning there's nothing left to add), which happens for me after 139 iterations:
This is a little better. Flipping back and forth, I see that j-rock was 5th in the raw version, with 62 artists, but in the iterative version it drops to 13th, because only 36 of those 62 artists aren't part of any higher-ranked genres. Similarly, symphonic power metal drops from 6th to 12th. Japanese alternative rock moves up, because only 1 of those 56 artists was being double-counted before.
Really, though, this list of 139 "representative" genres still overstates the granularity into which my listening is emotionally organized. If you do not tend to use the words "granularity" and "emotionally" in the same sentences in your internal monologue, then you should probably cut your losses and tune out now. In order to cluster genres instead of just subsetting them, we need almost every major feature of Dactal:
?artistsx=(2024 artists scored|genre=(.id.artist genres.genres),weight=(....artistpoints,sqrt))
?genre index=(artistsx/genre,of=artists:count>=5)
?clusters=()
?(
?artistsx=(artistsx:-~~(clusters:@@1.of))
?nextgenre=(artistsx/genre,of=artists:count>=10#(.artists....weight,total),count:@1)
?nextcluster=(
nextgenre.artists/genre,of=artists:count>=5
||total=(.genre.genre index.count),overlap=[=count/total]
:(.total) :overlap>=[.1] #(.artists....weight,total),count
...top genres=(.genre:@<=10),
top artists=(.artists:@<=10.name),
clustered genres=(.genre....count),
of=(.genre.genre index.artists)
:(.top genres)
)
?clusters=(clusters,nextcluster)
)!
?genre index=(artistsx/genre,of=artists:count>=5)
?clusters=()
?(
?artistsx=(artistsx:-~~(clusters:@@1.of))
?nextgenre=(artistsx/genre,of=artists:count>=10#(.artists....weight,total),count:@1)
?nextcluster=(
nextgenre.artists/genre,of=artists:count>=5
||total=(.genre.genre index.count),overlap=[=count/total]
:(.total) :overlap>=[.1] #(.artists....weight,total),count
...top genres=(.genre:@<=10),
top artists=(.artists:@<=10.name),
clustered genres=(.genre....count),
of=(.genre.genre index.artists)
:(.top genres)
)
?clusters=(clusters,nextcluster)
)!
I'm not going to claim this is "easy", but I've written variations on this algorithm in Ruby, Python, SQL and Javascript over the years, and I can tell you that all of those versions were much longer and involved way more punctuation than this, in addition to a lot more words that are about computers instead of about music.
The first two steps of the clustering are about the same as in the simpler version: eliminate any artists we've already used, and then find the top genre. Here we're scoring genres by summing up the square roots of artist points, instead of just counting artists, to measure a combination of listening breadth and listening depth, but that's added complexity in the question, not just the answer.
The clustering part is that once we have a top genre, we take all its artists and count their other genres, and then compare the overlap sizes with those genres' total artist counts (using lookups in the genre index created in the second line of the query). Other genres that overlap non-trivially with the first genre also get added to the cluster. Then the whole thing repeats. So instead of building a flat list of genres, this version builds a list of nested genre lists.
This is, for me, a lot closer to correct than the flat list, and certainly more interesting. It doesn't distribute my Japanese tastes exactly right (I don't care about anime, per se, so I usually put ReoNa and LiSA with the alt-idol groups for sonic reasons), but these first 10 statistical clusters are all aspects of my taste that I would list individually if you inadvisedly gave me an excuse, and of the 44 ways it breaks down my 2024, the only ones that get me thinking about override mechanics are towards the bottom where the genre data doesn't know that I tend to put the Spanish metal bands and the medieval rock nerds in with the other melodic metal styles.
If you want to try this on your own listening, there are now both "genres" and "genre clusters" views on the History page in Curio. But as with all of those, there is also a "see the query for this" at the bottom of the results, so if you want to experiment with variations, you can.
Although by you, as usual, I probably mean me. But by me I mean all of us.
¶ What we know · 14 January 2025 listen/tech
The thing I worked on the longest, in my Echo Nest / Spotify time, was calculating artist similarity. In the Echo Nest days, when we didn't have direct listening data, we derived scores for pairs of artists based on patterns of shared descriptive words found in web pages about each of them. Or, more accurately, web pages maybe about them, because figuring out whether any given blob of text that contains a given string of letters is about a band whose name is that same string of letters, at all never mind in a descriptively useful sense, is hard.
Once we got swallowed by Spotify, of course, we had all the listening-data plankton we could krill. The goal of "collaborative filtering", taken most lowercasely, is to extract collective knowledge from collected data. The Spotify feature this work powered was called (eventually) Fans Also Like, and one of my greatest organizational triumphs at Spotify was that after many years of technical work and political lobbying, I succeeded in making this feature live up to its name. For about a year and a half, starting around April 2023, the Spotify artist page Fans Also Like lists were really an algebraic formulation of getting each artist's fans, not just listeners, and finding out what other artists they disproportionately also liked. And nothing else. You only saw the first 20 results for each artist, but the underlying dataset behind this went deeper, and I think was a genuinely unprecedented collective cultural achievement of the Spotify audience.
Most of the complexity of doing this well, if by "well" you mean reflecting actual patterns of human interest as opposed to round-off error in vector embeddings or clandestine margin-chiseling, which you should, was actually in the quantification of "fan". I would not be able to explain all the details of that process from memory, even if I were allowed to, but the core idea is that the more you raise the threshold of fandom, the better similarity signal you get from the listening patterns of those fans, but the fewer artists are included, so if you want both precision and recall, you have to get creative.
And of course you have to get data, to begin with. We cannot recreate the lost Fans Also Like network from outside of Spotify, because we cannot get their dataset of fan/artist pairs. Or, really, our dataset, because it's our listening.
If you happen to have pairs of any kind of data, though, doing simple math to extract similarity of one half of those pairs based on the co-reference patterns of the other half is easy. In fact, if you have that pair data in JSON, you can load it into the spec/doc/test/playground page for Dactal and do it right now.
For example, over at AlbumOfTheYear.org they aggregate album-of-the-year lists from many other publications and produce a scored meta-ranking of the year's albums. But this dataset of publication/album pairs also encodes patterns of implicit knowledge about album similarity based on the tendencies of publications to list albums together, and about publication similarity based on the tendencies of albums to appeal to publications together.
Here's how to extract it using Dactal:
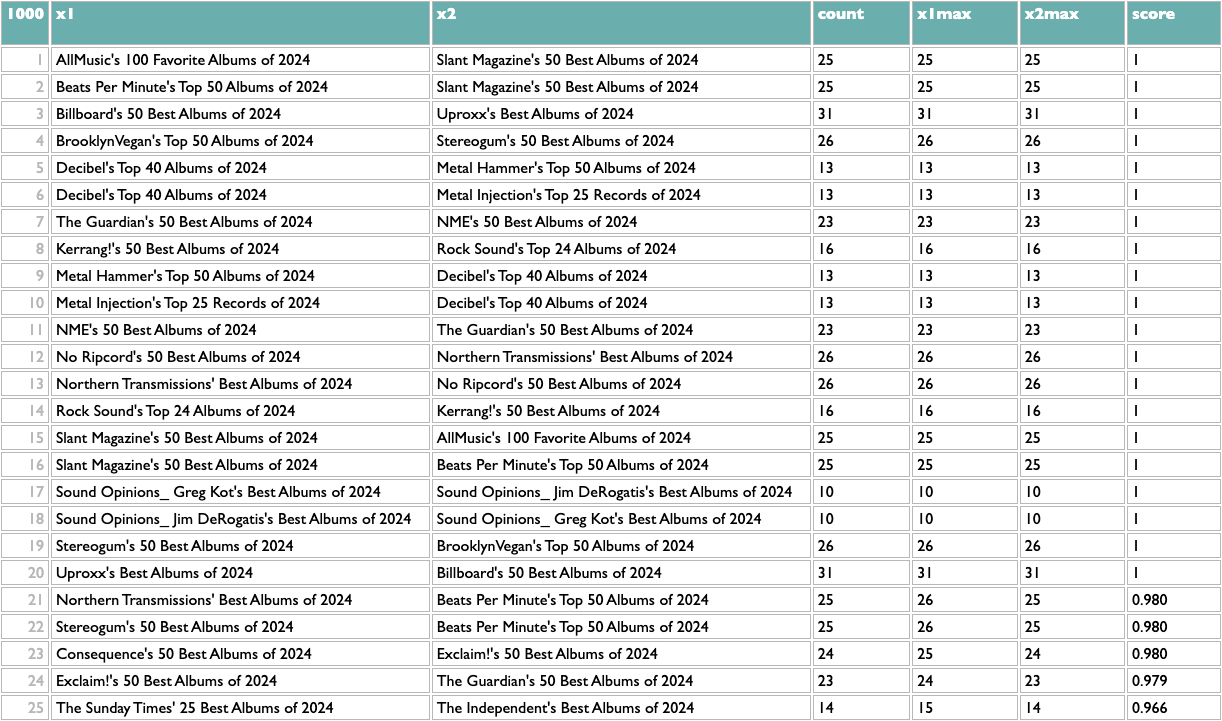
The first orange line is specific to this data, my extraction from the AOTY lists, but all it needs to produce is a two-column list with x and y. Like this:
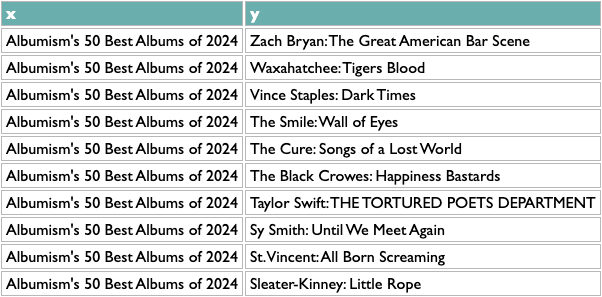
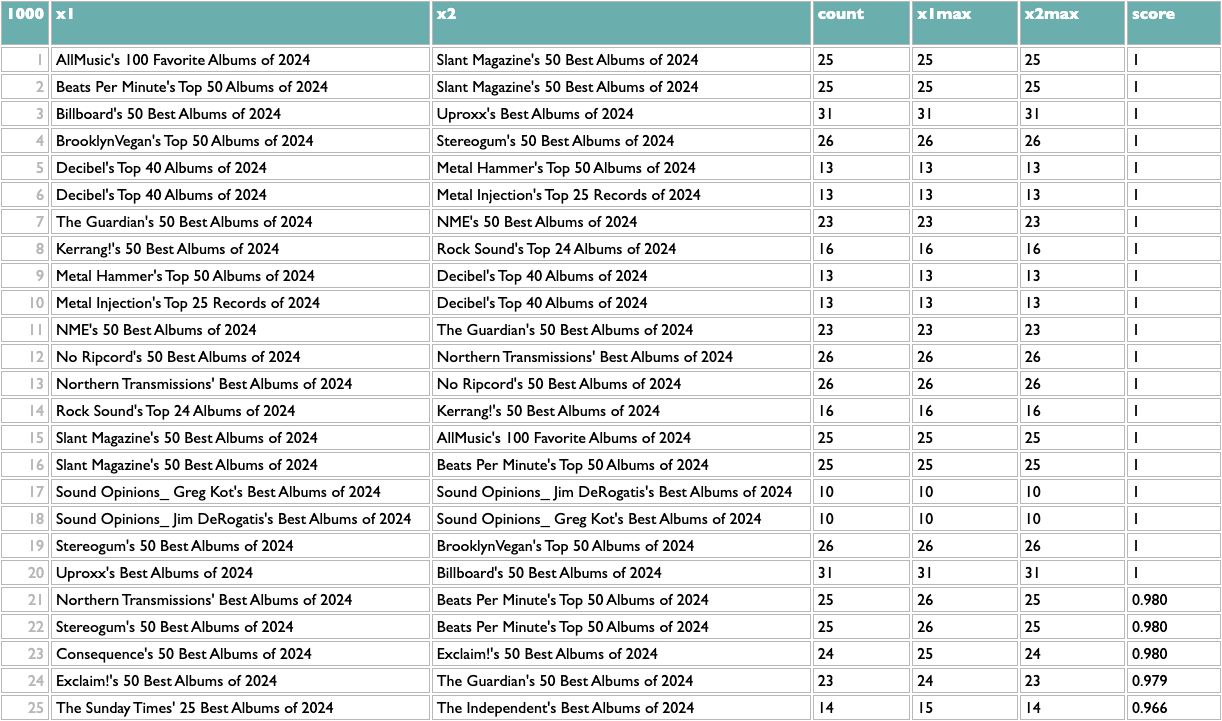
Once you have any x/y list like this, the rest of the query works the same. The scoring logic here (which isn't what I used at Spotify, but you probably aren't dealing with 600 million people listening to 10 million artists) counts the overlap between any pair of x based on y, and then scales that by the maximum overlaps of both parts of the pair. So a score of 1 means that both things in that pair are each other's closest match. The calculation is asymmetric because one part of a pair may be the other's closest match but not vice versa. If you read about music online you may know that, e.g., Decibel and Metal Hammer are both metal-specific, The Guardian and NME are both British, and BrooklynVegan and Stereogum are both read by the kind of people who read BrooklynVegan and Stereogum, so the top of those results passes a basic sanity check.
And because everything but the first line is independent of what x and y are, that means we can flip x and y (just those two letters!) and get album similarity:
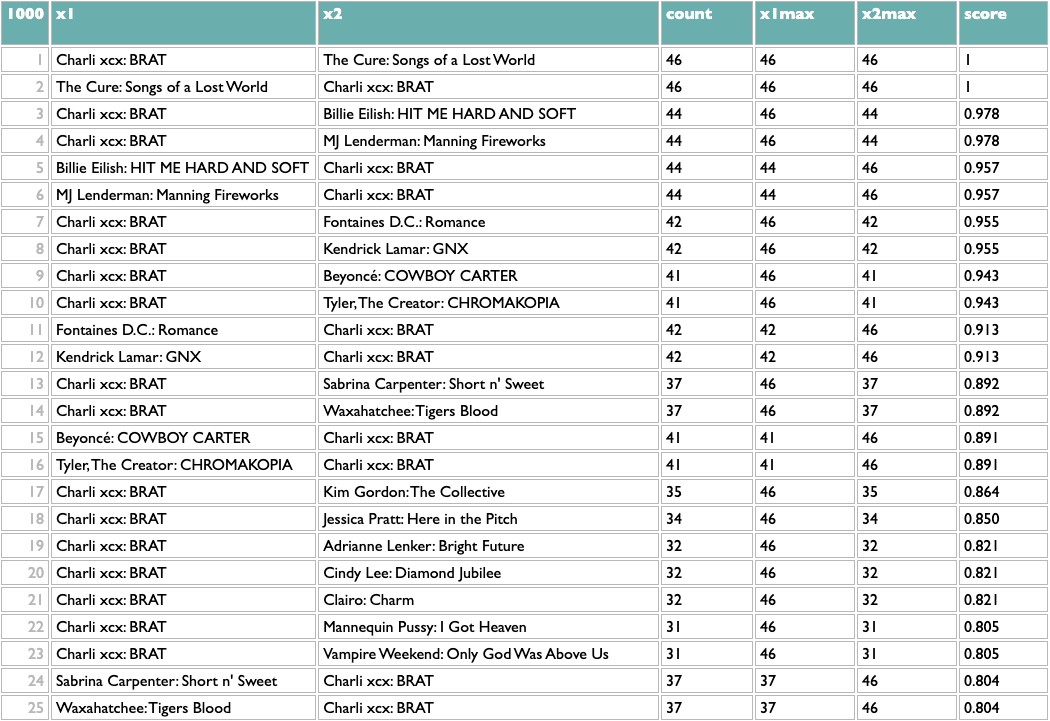
This passes a sanity check – everybody who writes about music likes Charli – but not an interestingness check, so we might opt to filter out BRAT just to see what else we can learn:
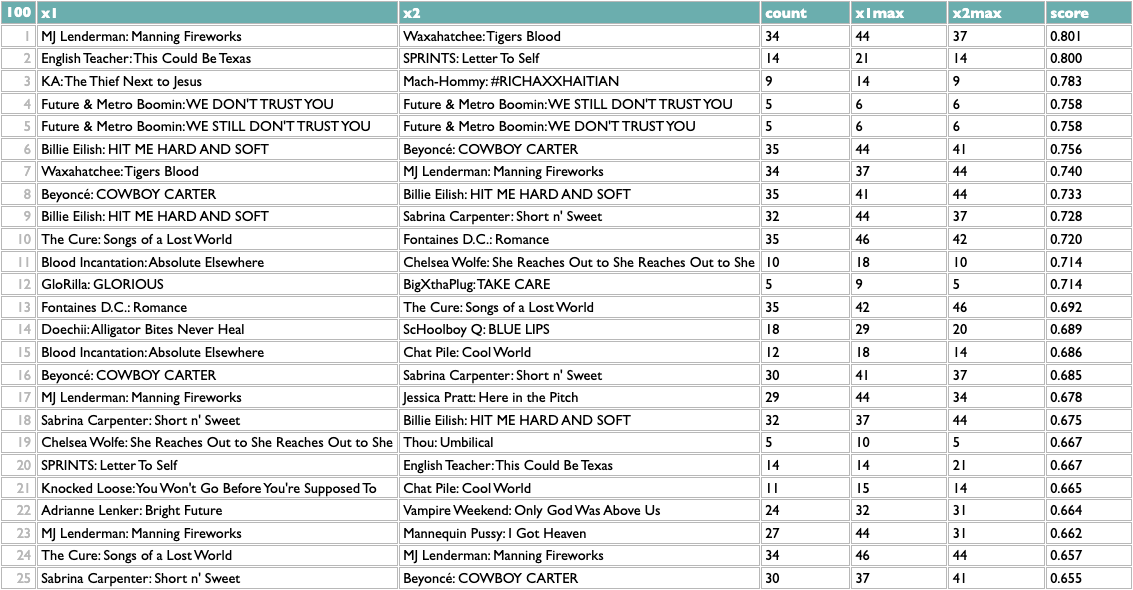
Not bad! The two Future/Metro Boomin albums are most similar to each other, which is the good kind of confidence-boosting boring answer, but a bunch of the other pairs are plausible yet non-obvious: two indie rock records, two UK indie guitar records, two indie rappers, two metal-adjacent records.
These scores are normalized locally, not globally, so the real way to use them is to reorganize this by album. Which is also easy:
That's interesting to me. What's interesting to you?
[PS: Oh, here, I put this dataset up in raw interactive form, so you can play with it yourself if you want.]
Once we got swallowed by Spotify, of course, we had all the listening-data plankton we could krill. The goal of "collaborative filtering", taken most lowercasely, is to extract collective knowledge from collected data. The Spotify feature this work powered was called (eventually) Fans Also Like, and one of my greatest organizational triumphs at Spotify was that after many years of technical work and political lobbying, I succeeded in making this feature live up to its name. For about a year and a half, starting around April 2023, the Spotify artist page Fans Also Like lists were really an algebraic formulation of getting each artist's fans, not just listeners, and finding out what other artists they disproportionately also liked. And nothing else. You only saw the first 20 results for each artist, but the underlying dataset behind this went deeper, and I think was a genuinely unprecedented collective cultural achievement of the Spotify audience.
Most of the complexity of doing this well, if by "well" you mean reflecting actual patterns of human interest as opposed to round-off error in vector embeddings or clandestine margin-chiseling, which you should, was actually in the quantification of "fan". I would not be able to explain all the details of that process from memory, even if I were allowed to, but the core idea is that the more you raise the threshold of fandom, the better similarity signal you get from the listening patterns of those fans, but the fewer artists are included, so if you want both precision and recall, you have to get creative.
And of course you have to get data, to begin with. We cannot recreate the lost Fans Also Like network from outside of Spotify, because we cannot get their dataset of fan/artist pairs. Or, really, our dataset, because it's our listening.
If you happen to have pairs of any kind of data, though, doing simple math to extract similarity of one half of those pairs based on the co-reference patterns of the other half is easy. In fact, if you have that pair data in JSON, you can load it into the spec/doc/test/playground page for Dactal and do it right now.
For example, over at AlbumOfTheYear.org they aggregate album-of-the-year lists from many other publications and produce a scored meta-ranking of the year's albums. But this dataset of publication/album pairs also encodes patterns of implicit knowledge about album similarity based on the tendencies of publications to list albums together, and about publication similarity based on the tendencies of albums to appeal to publications together.
Here's how to extract it using Dactal:
?data=(aoty.entries.(....x=aotylist,y=albumkey))
?paircounts=(data/y/x1=(.of.x),x2=(.of.x):(.key:@2):count>=5)
?x maxpoints=(paircounts/key||maxpoints=(.of.count....max))
?paircounts
||x1max=(.x1.x maxpoints.maxpoints),
x2max=(.x2.x maxpoints.maxpoints),
score=[=2*count**2/((count+x1max)*x2max)]
#score
?paircounts=(data/y/x1=(.of.x),x2=(.of.x):(.key:@2):count>=5)
?x maxpoints=(paircounts/key||maxpoints=(.of.count....max))
?paircounts
||x1max=(.x1.x maxpoints.maxpoints),
x2max=(.x2.x maxpoints.maxpoints),
score=[=2*count**2/((count+x1max)*x2max)]
#score
The first orange line is specific to this data, my extraction from the AOTY lists, but all it needs to produce is a two-column list with x and y. Like this:
?data=(aoty.entries.(....x=aotylist,y=albumkey))
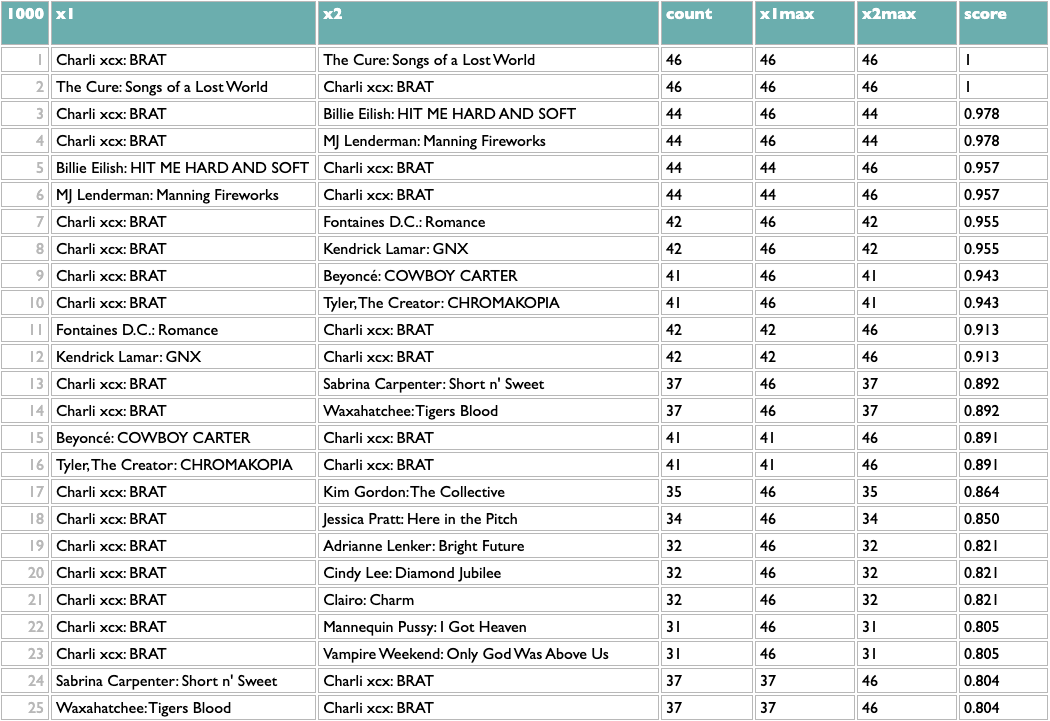
Once you have any x/y list like this, the rest of the query works the same. The scoring logic here (which isn't what I used at Spotify, but you probably aren't dealing with 600 million people listening to 10 million artists) counts the overlap between any pair of x based on y, and then scales that by the maximum overlaps of both parts of the pair. So a score of 1 means that both things in that pair are each other's closest match. The calculation is asymmetric because one part of a pair may be the other's closest match but not vice versa. If you read about music online you may know that, e.g., Decibel and Metal Hammer are both metal-specific, The Guardian and NME are both British, and BrooklynVegan and Stereogum are both read by the kind of people who read BrooklynVegan and Stereogum, so the top of those results passes a basic sanity check.
And because everything but the first line is independent of what x and y are, that means we can flip x and y (just those two letters!) and get album similarity:
?data=(aoty.entries.(....y=aotylist,x=albumkey))
?paircounts=(data/y/x1=(.of.x),x2=(.of.x):(.key:@2):count>=5)
?x maxpoints=(paircounts/key||maxpoints=(.of.count....max))
?paircounts
||x1max=(.x1.x maxpoints.maxpoints),
x2max=(.x2.x maxpoints.maxpoints),
score=[=2*count**2/((count+x1max)*x2max)]
#score
?paircounts=(data/y/x1=(.of.x),x2=(.of.x):(.key:@2):count>=5)
?x maxpoints=(paircounts/key||maxpoints=(.of.count....max))
?paircounts
||x1max=(.x1.x maxpoints.maxpoints),
x2max=(.x2.x maxpoints.maxpoints),
score=[=2*count**2/((count+x1max)*x2max)]
#score
This passes a sanity check – everybody who writes about music likes Charli – but not an interestingness check, so we might opt to filter out BRAT just to see what else we can learn:
?data=(aoty.entries.(....y=aotylist,x=albumkey))
?paircounts=(data/y/x1=(.of.x),x2=(.of.x):(.key:@2):count>=5)
?x maxpoints=(paircounts/key||maxpoints=(.of.count....max))
?paircounts
||x1max=(.x1.x maxpoints.maxpoints),
x2max=(.x2.x maxpoints.maxpoints),
score=[=2*count**2/((count+x1max)*x2max)]
:-(.x1,x2:=[Charli xcx: BRAT])
#score
?paircounts=(data/y/x1=(.of.x),x2=(.of.x):(.key:@2):count>=5)
?x maxpoints=(paircounts/key||maxpoints=(.of.count....max))
?paircounts
||x1max=(.x1.x maxpoints.maxpoints),
x2max=(.x2.x maxpoints.maxpoints),
score=[=2*count**2/((count+x1max)*x2max)]
:-(.x1,x2:=[Charli xcx: BRAT])
#score
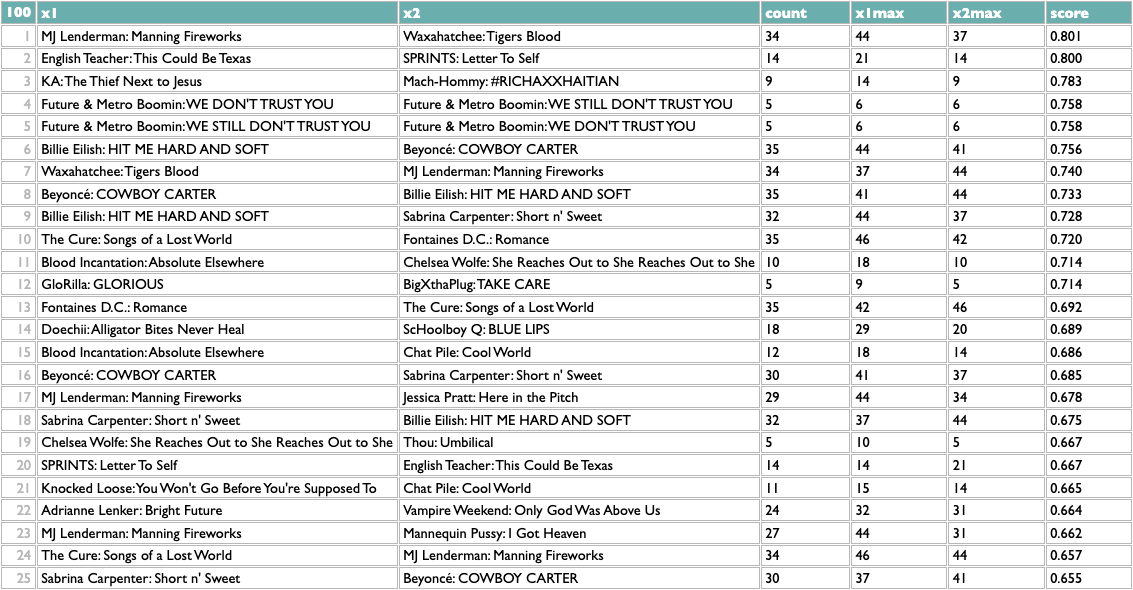
Not bad! The two Future/Metro Boomin albums are most similar to each other, which is the good kind of confidence-boosting boring answer, but a bunch of the other pairs are plausible yet non-obvious: two indie rock records, two UK indie guitar records, two indie rappers, two metal-adjacent records.
These scores are normalized locally, not globally, so the real way to use them is to reorganize this by album. Which is also easy:
?data=(aoty.entries.(....y=aotylist,x=albumkey))
?paircounts=(data/y/x1=(.of.x),x2=(.of.x):(.key:@2):count>=5)
?x maxpoints=(paircounts/key||maxpoints=(.of.count....max))
?paircounts
||x1max=(.x1.x maxpoints.maxpoints),
x2max=(.x2.x maxpoints.maxpoints),
score=[=2*count**2/((count+x1max)*x2max)]
:-(.x1,x2:=[Charli xcx: BRAT])
#score
/iyl=(.x1,x2)
.(....iyl,yml=(._,(.of.x1,x2):@>1:@<=10)
?paircounts=(data/y/x1=(.of.x),x2=(.of.x):(.key:@2):count>=5)
?x maxpoints=(paircounts/key||maxpoints=(.of.count....max))
?paircounts
||x1max=(.x1.x maxpoints.maxpoints),
x2max=(.x2.x maxpoints.maxpoints),
score=[=2*count**2/((count+x1max)*x2max)]
:-(.x1,x2:=[Charli xcx: BRAT])
#score
/iyl=(.x1,x2)
.(....iyl,yml=(._,(.of.x1,x2):@>1:@<=10)
| 146 | iyl | yml |
| 1 | A. G. Cook: Britpop | 10 Maggie Rogers: Don't Forget Me Remi Wolf: Big Ideas Clairo: Charm Jack White: No Name Magdalena Bay: Imaginal Disk Vampire Weekend: Only God Was Above Us Fontaines D.C.: Romance Doechii: Alligator Bites Never Heal Tyler, The Creator: CHROMAKOPIA ScHoolboy Q: BLUE LIPS |
| 2 | Adrianne Lenker: Bright Future | 10 Vampire Weekend: Only God Was Above Us The Last Dinner Party: Prelude to Ecstasy The Cure: Songs of a Lost World Fontaines D.C.: Romance Arooj Aftab: Night Reign Kim Gordon: The Collective Magdalena Bay: Imaginal Disk Floating Points: Cascade Waxahatchee: Tigers Blood MJ Lenderman: Manning Fireworks |
| 3 | Amyl and The Sniffers: Cartoon Darkness | 10 English Teacher: This Could Be Texas The Last Dinner Party: Prelude to Ecstasy Bob Vylan: Humble As The Sun Hamish Hawk: A Firmer Hand IDLES: TANGK SPRINTS: Letter To Self Fontaines D.C.: Romance The Cure: Songs of a Lost World Waxahatchee: Tigers Blood Wunderhorse: Midas |
| 4 | Ariana Grande: eternal sunshine | 10 Billie Eilish: HIT ME HARD AND SOFT Sabrina Carpenter: Short n' Sweet Dua Lipa: Radical Optimism Beyoncé: COWBOY CARTER Kacey Musgraves: Deeper Well Clairo: Charm Doechii: Alligator Bites Never Heal Vampire Weekend: Only God Was Above Us Magdalena Bay: Imaginal Disk The Cure: Songs of a Lost World |
| 5 | Arooj Aftab: Night Reign | 10 Adrianne Lenker: Bright Future Jessica Pratt: Here in the Pitch Beth Gibbons: Lives Outgrown Cindy Lee: Diamond Jubilee MJ Lenderman: Manning Fireworks The Cure: Songs of a Lost World Nala Sinephro: Endlessness Vampire Weekend: Only God Was Above Us Waxahatchee: Tigers Blood Nilüfer Yanya: My Method Actor |
| 6 | Astrid Sonne: Great Doubt | 4 Nala Sinephro: Endlessness Nilüfer Yanya: My Method Actor MJ Lenderman: Manning Fireworks Mk.gee: Two Star & The Dream Police |
| 7 | Being Dead: EELS | 10 This Is Lorelei: Box For Buddy, Box For Star Mannequin Pussy: I Got Heaven Jessica Pratt: Here in the Pitch Nilüfer Yanya: My Method Actor Blood Incantation: Absolute Elsewhere Magdalena Bay: Imaginal Disk Mk.gee: Two Star & The Dream Police Vampire Weekend: Only God Was Above Us MJ Lenderman: Manning Fireworks Clairo: Charm |
| 8 | Beth Gibbons: Lives Outgrown | 10 The Cure: Songs of a Lost World Arooj Aftab: Night Reign Jessica Pratt: Here in the Pitch Adrianne Lenker: Bright Future Kim Gordon: The Collective Julia Holter: Something in the Room She Moves Mannequin Pussy: I Got Heaven Waxahatchee: Tigers Blood Nilüfer Yanya: My Method Actor Chat Pile: Cool World |
| 9 | Beyoncé: COWBOY CARTER | 10 Billie Eilish: HIT ME HARD AND SOFT Sabrina Carpenter: Short n' Sweet Doechii: Alligator Bites Never Heal Kendrick Lamar: GNX Jack White: No Name The Cure: Songs of a Lost World Kali Uchis: ORQUÍDEAS Waxahatchee: Tigers Blood MJ Lenderman: Manning Fireworks ScHoolboy Q: BLUE LIPS |
| 10 | BigXthaPlug: TAKE CARE | 4 GloRilla: GLORIOUS Doechii: Alligator Bites Never Heal Tyler, The Creator: CHROMAKOPIA Kendrick Lamar: GNX |
| 11 | Bill Ryder-Jones: Iechyd Da | 10 Amyl and The Sniffers: Cartoon Darkness Arooj Aftab: Night Reign Fontaines D.C.: Romance Adrianne Lenker: Bright Future The Cure: Songs of a Lost World Kim Gordon: The Collective Beth Gibbons: Lives Outgrown The Last Dinner Party: Prelude to Ecstasy Vampire Weekend: Only God Was Above Us Cindy Lee: Diamond Jubilee |
| 12 | Billie Eilish: HIT ME HARD AND SOFT | 10 Beyoncé: COWBOY CARTER Sabrina Carpenter: Short n' Sweet The Cure: Songs of a Lost World Clairo: Charm St. Vincent: All Born Screaming Doechii: Alligator Bites Never Heal Ariana Grande: eternal sunshine Kendrick Lamar: GNX Taylor Swift: THE TORTURED POETS DEPARTMENT Kali Uchis: ORQUÍDEAS |
| 13 | Bladee: Cold Visions | 2 Mount Eerie: Night Palace Clairo: Charm |
| 14 | Blood Incantation: Absolute Elsewhere | 10 Chelsea Wolfe: She Reaches Out to She Reaches Out to She Chat Pile: Cool World Judas Priest: Invincible Shield Knocked Loose: You Won't Go Before You're Supposed To Mannequin Pussy: I Got Heaven Opeth: The Last Will and Testament Gatecreeper: Dark Superstition Thou: Umbilical Vampire Weekend: Only God Was Above Us Adrianne Lenker: Bright Future |
| 15 | Bob Vylan: Humble As The Sun | Amyl and The Sniffers: Cartoon Darkness |
| 16 | Bring Me The Horizon: POST HUMAN: NeX GEn | Knocked Loose: You Won't Go Before You're Supposed To |
| 17 | Brittany Howard: What Now | 10 Common & Pete Rock: The Auditorium Vol. 1 Waxahatchee: Tigers Blood Vampire Weekend: Only God Was Above Us Adrianne Lenker: Bright Future Billie Eilish: HIT ME HARD AND SOFT The Cure: Songs of a Lost World Beyoncé: COWBOY CARTER E L U C I D: REVELATOR ScHoolboy Q: BLUE LIPS Johnny Blue Skies: Passage du Desir |
| 18 | Caribou: Honey | 3 Kim Gordon: The Collective Waxahatchee: Tigers Blood MJ Lenderman: Manning Fireworks |
| 19 | Cassandra Jenkins: My Light, My Destroyer | 10 MJ Lenderman: Manning Fireworks Nala Sinephro: Endlessness Waxahatchee: Tigers Blood Nilüfer Yanya: My Method Actor Jessica Pratt: Here in the Pitch Kim Gordon: The Collective Mabe Fratti: Sentir Que No Sabes Arooj Aftab: Night Reign The Cure: Songs of a Lost World Mk.gee: Two Star & The Dream Police |
| 20 | Chanel Beads: Your Day Will Come | 5 Nala Sinephro: Endlessness Mk.gee: Two Star & The Dream Police Mannequin Pussy: I Got Heaven Cindy Lee: Diamond Jubilee MJ Lenderman: Manning Fireworks |
| 21 | Charli xcx: Brat and it's completely different but also still brat | 5 Doechii: Alligator Bites Never Heal Sabrina Carpenter: Short n' Sweet Beyoncé: COWBOY CARTER Billie Eilish: HIT ME HARD AND SOFT Kim Gordon: The Collective |
| 22 | Chat Pile: Cool World | 10 Blood Incantation: Absolute Elsewhere Knocked Loose: You Won't Go Before You're Supposed To Gouge Away: Deep Sage Touché Amoré: Spiral in a Straight Line Foxing: Foxing Magdalena Bay: Imaginal Disk Mannequin Pussy: I Got Heaven Cindy Lee: Diamond Jubilee Mount Eerie: Night Palace The Cure: Songs of a Lost World |
| 23 | Chelsea Wolfe: She Reaches Out to She Reaches Out to She | 10 Blood Incantation: Absolute Elsewhere Thou: Umbilical Knocked Loose: You Won't Go Before You're Supposed To Touché Amoré: Spiral in a Straight Line Geordie Greep: The New Sound Julia Holter: Something in the Room She Moves Chat Pile: Cool World Beth Gibbons: Lives Outgrown ScHoolboy Q: BLUE LIPS Mannequin Pussy: I Got Heaven |
| 24 | Chief Keef: Almighty So 2 | 10 Mk.gee: Two Star & The Dream Police Sabrina Carpenter: Short n' Sweet Nilüfer Yanya: My Method Actor Vampire Weekend: Only God Was Above Us Adrianne Lenker: Bright Future Clairo: Charm Waxahatchee: Tigers Blood Beyoncé: COWBOY CARTER Kendrick Lamar: GNX Billie Eilish: HIT ME HARD AND SOFT |
| 25 | Christopher Owens: I Wanna Run Barefoot Through Your Hair | 4 Mannequin Pussy: I Got Heaven Vampire Weekend: Only God Was Above Us MJ Lenderman: Manning Fireworks The Cure: Songs of a Lost World |
| 26 | Cindy Lee: Diamond Jubilee | 10 MJ Lenderman: Manning Fireworks Jessica Pratt: Here in the Pitch Magdalena Bay: Imaginal Disk The Cure: Songs of a Lost World Arooj Aftab: Night Reign Waxahatchee: Tigers Blood Mdou Moctar: Funeral for Justice Mount Eerie: Night Palace Mannequin Pussy: I Got Heaven Kim Gordon: The Collective |
| 27 | claire rousay: sentiment | 10 Kim Gordon: The Collective Arooj Aftab: Night Reign MJ Lenderman: Manning Fireworks Nala Sinephro: Endlessness Mk.gee: Two Star & The Dream Police Clairo: Charm Sabrina Carpenter: Short n' Sweet Waxahatchee: Tigers Blood Beyoncé: COWBOY CARTER Billie Eilish: HIT ME HARD AND SOFT |
| 28 | Clairo: Charm | 10 Billie Eilish: HIT ME HARD AND SOFT Mk.gee: Two Star & The Dream Police St. Vincent: All Born Screaming MJ Lenderman: Manning Fireworks Vampire Weekend: Only God Was Above Us Tyler, The Creator: CHROMAKOPIA Magdalena Bay: Imaginal Disk Adrianne Lenker: Bright Future Fontaines D.C.: Romance Sabrina Carpenter: Short n' Sweet |
| 29 | Clarissa Connelly: World of Work | 2 Kim Gordon: The Collective Nala Sinephro: Endlessness |
| 30 | Common & Pete Rock: The Auditorium Vol. 1 | 6 Vince Staples: Dark Times Brittany Howard: What Now ScHoolboy Q: BLUE LIPS The Cure: Songs of a Lost World Adrianne Lenker: Bright Future Jessica Pratt: Here in the Pitch |
| 31 | Confidence Man: 3AM (LA LA LA) | 5 The Last Dinner Party: Prelude to Ecstasy English Teacher: This Could Be Texas Billie Eilish: HIT ME HARD AND SOFT Beyoncé: COWBOY CARTER Fontaines D.C.: Romance |
| 32 | The Cure: Songs of a Lost World | 10 Fontaines D.C.: Romance MJ Lenderman: Manning Fireworks Vampire Weekend: Only God Was Above Us Waxahatchee: Tigers Blood The Last Dinner Party: Prelude to Ecstasy Jessica Pratt: Here in the Pitch Adrianne Lenker: Bright Future Jack White: No Name Nick Cave & The Bad Seeds: Wild God Mannequin Pussy: I Got Heaven |
| 33 | Denzel Curry: King of the Mischievous South Vol. 2 | 2 Beyoncé: COWBOY CARTER Tyler, The Creator: CHROMAKOPIA |
| 34 | DIIV: Frog in Boiling Water | 10 Father John Misty: Mahashmashana Vampire Weekend: Only God Was Above Us Mannequin Pussy: I Got Heaven The Cure: Songs of a Lost World Fontaines D.C.: Romance Mk.gee: Two Star & The Dream Police Adrianne Lenker: Bright Future Clairo: Charm Jessica Pratt: Here in the Pitch Sabrina Carpenter: Short n' Sweet |
| 35 | Doechii: Alligator Bites Never Heal | 10 ScHoolboy Q: BLUE LIPS Kendrick Lamar: GNX Beyoncé: COWBOY CARTER Billie Eilish: HIT ME HARD AND SOFT Sabrina Carpenter: Short n' Sweet Kali Uchis: ORQUÍDEAS Tyler, The Creator: CHROMAKOPIA GloRilla: GLORIOUS MJ Lenderman: Manning Fireworks Mk.gee: Two Star & The Dream Police |
| 36 | Dua Lipa: Radical Optimism | 10 St. Vincent: All Born Screaming Ariana Grande: eternal sunshine Billie Eilish: HIT ME HARD AND SOFT Sabrina Carpenter: Short n' Sweet Beyoncé: COWBOY CARTER Mannequin Pussy: I Got Heaven Vampire Weekend: Only God Was Above Us Clairo: Charm The Last Dinner Party: Prelude to Ecstasy MJ Lenderman: Manning Fireworks |
| 37 | E L U C I D: REVELATOR | 10 Mdou Moctar: Funeral for Justice Nala Sinephro: Endlessness Arooj Aftab: Night Reign Brittany Howard: What Now Tyler, The Creator: CHROMAKOPIA Beth Gibbons: Lives Outgrown Blood Incantation: Absolute Elsewhere ScHoolboy Q: BLUE LIPS Jessica Pratt: Here in the Pitch Doechii: Alligator Bites Never Heal |
| 38 | Ekko Astral: pink balloons | 10 Knocked Loose: You Won't Go Before You're Supposed To Kali Uchis: ORQUÍDEAS Mk.gee: Two Star & The Dream Police ScHoolboy Q: BLUE LIPS Tyler, The Creator: CHROMAKOPIA Fontaines D.C.: Romance Doechii: Alligator Bites Never Heal Mannequin Pussy: I Got Heaven The Cure: Songs of a Lost World Jessica Pratt: Here in the Pitch |
| 39 | Empress Of: For Your Consideration | 10 Arooj Aftab: Night Reign Clairo: Charm Kali Uchis: ORQUÍDEAS Jack White: No Name Beyoncé: COWBOY CARTER Billie Eilish: HIT ME HARD AND SOFT Kim Gordon: The Collective Waxahatchee: Tigers Blood Vampire Weekend: Only God Was Above Us Jessica Pratt: Here in the Pitch |
| 40 | English Teacher: This Could Be Texas | 10 SPRINTS: Letter To Self The Last Dinner Party: Prelude to Ecstasy Amyl and The Sniffers: Cartoon Darkness Fontaines D.C.: Romance The Cure: Songs of a Lost World Wunderhorse: Midas Magdalena Bay: Imaginal Disk Laura Marling: Patterns in Repeat Rachel Chinouriri: What A Devastating Turn of Events Waxahatchee: Tigers Blood |
| 41 | Erika de Casier: Still | 3 Nilüfer Yanya: My Method Actor Mk.gee: Two Star & The Dream Police MJ Lenderman: Manning Fireworks |
| 42 | Ezra Collective: Dance, No One's Watching | 5 Jamie xx: In Waves MJ Lenderman: Manning Fireworks The Cure: Songs of a Lost World Jessica Pratt: Here in the Pitch Fontaines D.C.: Romance |
| 43 | Fabiana Palladino: Fabiana Palladino | 10 Tyla: TYLA Nala Sinephro: Endlessness MJ Lenderman: Manning Fireworks Jessica Pratt: Here in the Pitch Kim Gordon: The Collective Nick Cave & The Bad Seeds: Wild God Jamie xx: In Waves Fontaines D.C.: Romance Mdou Moctar: Funeral for Justice Waxahatchee: Tigers Blood |
| 44 | Fat Dog: WOOF. | 2 The Last Dinner Party: Prelude to Ecstasy St. Vincent: All Born Screaming |
| 45 | Father John Misty: Mahashmashana | 10 MJ Lenderman: Manning Fireworks Vampire Weekend: Only God Was Above Us Wild Pink: Dulling The Horns The Cure: Songs of a Lost World DIIV: Frog in Boiling Water Gouge Away: Deep Sage Fontaines D.C.: Romance Mannequin Pussy: I Got Heaven Cindy Lee: Diamond Jubilee Kendrick Lamar: GNX |
| 46 | Faye Webster: Underdressed at the Symphony | 2 Clairo: Charm Billie Eilish: HIT ME HARD AND SOFT |
| 47 | Fievel Is Glauque: Rong Weicknes | Kim Gordon: The Collective |
| 48 | Floating Points: Cascade | 10 Adrianne Lenker: Bright Future Julia Holter: Something in the Room She Moves Mannequin Pussy: I Got Heaven Mount Eerie: Night Palace Jessica Pratt: Here in the Pitch Blood Incantation: Absolute Elsewhere The Last Dinner Party: Prelude to Ecstasy Arooj Aftab: Night Reign Brittany Howard: What Now Johnny Blue Skies: Passage du Desir |
| 49 | Fontaines D.C.: Romance | 10 The Cure: Songs of a Lost World The Last Dinner Party: Prelude to Ecstasy English Teacher: This Could Be Texas Mannequin Pussy: I Got Heaven Vampire Weekend: Only God Was Above Us MJ Lenderman: Manning Fireworks Tyler, The Creator: CHROMAKOPIA Adrianne Lenker: Bright Future Nick Cave & The Bad Seeds: Wild God Amyl and The Sniffers: Cartoon Darkness |
| 50 | Foxing: Foxing | 5 Chat Pile: Cool World Knocked Loose: You Won't Go Before You're Supposed To Kendrick Lamar: GNX MJ Lenderman: Manning Fireworks The Cure: Songs of a Lost World |
| 51 | Friko: Where we've been, Where we go from here | 4 Cindy Lee: Diamond Jubilee Jessica Pratt: Here in the Pitch Waxahatchee: Tigers Blood MJ Lenderman: Manning Fireworks |
| 52 | Future & Metro Boomin: WE DON'T TRUST YOU | 9 Future & Metro Boomin: WE STILL DON'T TRUST YOU Vince Staples: Dark Times ScHoolboy Q: BLUE LIPS Doechii: Alligator Bites Never Heal Mk.gee: Two Star & The Dream Police Sabrina Carpenter: Short n' Sweet Tyler, The Creator: CHROMAKOPIA Kendrick Lamar: GNX Beyoncé: COWBOY CARTER |
| 53 | Future & Metro Boomin: WE STILL DON'T TRUST YOU | 6 Future & Metro Boomin: WE DON'T TRUST YOU Doechii: Alligator Bites Never Heal ScHoolboy Q: BLUE LIPS Tyler, The Creator: CHROMAKOPIA Kendrick Lamar: GNX Mk.gee: Two Star & The Dream Police |
| 54 | Gatecreeper: Dark Superstition | Blood Incantation: Absolute Elsewhere |
| 55 | Geordie Greep: The New Sound | 10 Chelsea Wolfe: She Reaches Out to She Reaches Out to She JPEGMAFIA: I LAY DOWN MY LIFE FOR YOU Julia Holter: Something in the Room She Moves Blood Incantation: Absolute Elsewhere Waxahatchee: Tigers Blood Magdalena Bay: Imaginal Disk Brittany Howard: What Now Mount Eerie: Night Palace Kim Gordon: The Collective Beth Gibbons: Lives Outgrown |
| 56 | Gillian Welch & David Rawlings: Woodland | 10 Waxahatchee: Tigers Blood Hurray for the Riff Raff: The Past Is Still Alive Beth Gibbons: Lives Outgrown The Cure: Songs of a Lost World Brittany Howard: What Now Mannequin Pussy: I Got Heaven MJ Lenderman: Manning Fireworks Nilüfer Yanya: My Method Actor Vampire Weekend: Only God Was Above Us Jessica Pratt: Here in the Pitch |
| 57 | GloRilla: GLORIOUS | 10 BigXthaPlug: TAKE CARE ScHoolboy Q: BLUE LIPS Doechii: Alligator Bites Never Heal Tyla: TYLA Tyler, The Creator: CHROMAKOPIA Kendrick Lamar: GNX Mk.gee: Two Star & The Dream Police Sabrina Carpenter: Short n' Sweet Beyoncé: COWBOY CARTER Billie Eilish: HIT ME HARD AND SOFT |
| 58 | Godspeed You! Black Emperor: “NO TITLE AS OF 13 FEBRUARY 2024 28,340 DEAD” | 10 Cindy Lee: Diamond Jubilee Magdalena Bay: Imaginal Disk Kim Gordon: The Collective Vince Staples: Dark Times English Teacher: This Could Be Texas Mannequin Pussy: I Got Heaven Adrianne Lenker: Bright Future Mount Eerie: Night Palace The Last Dinner Party: Prelude to Ecstasy Jack White: No Name |
| 59 | Gouge Away: Deep Sage | 10 High Vis: Guided Tour Chat Pile: Cool World Father John Misty: Mahashmashana Mannequin Pussy: I Got Heaven Blood Incantation: Absolute Elsewhere The Cure: Songs of a Lost World Nilüfer Yanya: My Method Actor Tyler, The Creator: CHROMAKOPIA MJ Lenderman: Manning Fireworks Jessica Pratt: Here in the Pitch |
| 60 | Gracie Abrams: The Secret of Us | 5 Kacey Musgraves: Deeper Well Sabrina Carpenter: Short n' Sweet St. Vincent: All Born Screaming Billie Eilish: HIT ME HARD AND SOFT Beyoncé: COWBOY CARTER |
| 61 | Green Day: Saviors | The Cure: Songs of a Lost World |
| 62 | Hamish Hawk: A Firmer Hand | 2 Amyl and The Sniffers: Cartoon Darkness Jessica Pratt: Here in the Pitch |
| 63 | The Hard Quartet: The Hard Quartet | 4 MJ Lenderman: Manning Fireworks The Cure: Songs of a Lost World Waxahatchee: Tigers Blood Jessica Pratt: Here in the Pitch |
| 64 | High Vis: Guided Tour | 4 Gouge Away: Deep Sage Mannequin Pussy: I Got Heaven Fontaines D.C.: Romance The Cure: Songs of a Lost World |
| 65 | Hovvdy: Hovvdy | 10 Doechii: Alligator Bites Never Heal Magdalena Bay: Imaginal Disk Father John Misty: Mahashmashana Vampire Weekend: Only God Was Above Us Nilüfer Yanya: My Method Actor MJ Lenderman: Manning Fireworks Mk.gee: Two Star & The Dream Police Mannequin Pussy: I Got Heaven Sabrina Carpenter: Short n' Sweet Beyoncé: COWBOY CARTER |
| 66 | Hurray for the Riff Raff: The Past Is Still Alive | 10 Mount Eerie: Night Palace MJ Lenderman: Manning Fireworks Beyoncé: COWBOY CARTER Gillian Welch & David Rawlings: Woodland KA: The Thief Next to Jesus Waxahatchee: Tigers Blood Mannequin Pussy: I Got Heaven Kali Uchis: ORQUÍDEAS Mdou Moctar: Funeral for Justice Jessica Pratt: Here in the Pitch |
| 67 | IDLES: TANGK | 10 Amyl and The Sniffers: Cartoon Darkness The Cure: Songs of a Lost World SPRINTS: Letter To Self The Last Dinner Party: Prelude to Ecstasy Fontaines D.C.: Romance Tyler, The Creator: CHROMAKOPIA KNEECAP: Fine Art Vampire Weekend: Only God Was Above Us Beth Gibbons: Lives Outgrown English Teacher: This Could Be Texas |
| 68 | Jack White: No Name | 10 The Cure: Songs of a Lost World Vampire Weekend: Only God Was Above Us Beyoncé: COWBOY CARTER Kendrick Lamar: GNX Tyler, The Creator: CHROMAKOPIA Waxahatchee: Tigers Blood Billie Eilish: HIT ME HARD AND SOFT Adrianne Lenker: Bright Future Jamie xx: In Waves Fontaines D.C.: Romance |
| 69 | Jamie xx: In Waves | 10 Fontaines D.C.: Romance Justice: Hyperdrama Jack White: No Name The Cure: Songs of a Lost World Tyler, The Creator: CHROMAKOPIA Nick Cave & The Bad Seeds: Wild God Jessica Pratt: Here in the Pitch Beyoncé: COWBOY CARTER Yard Act: Where's My Utopia? MJ Lenderman: Manning Fireworks |
| 70 | Jessica Pratt: Here in the Pitch | 10 MJ Lenderman: Manning Fireworks The Cure: Songs of a Lost World Cindy Lee: Diamond Jubilee Waxahatchee: Tigers Blood Arooj Aftab: Night Reign Mdou Moctar: Funeral for Justice Beth Gibbons: Lives Outgrown Mannequin Pussy: I Got Heaven Kim Gordon: The Collective Doechii: Alligator Bites Never Heal |
| 71 | Jlin: Akoma | 6 Mabe Fratti: Sentir Que No Sabes Nala Sinephro: Endlessness Arooj Aftab: Night Reign Kim Gordon: The Collective Nilüfer Yanya: My Method Actor MJ Lenderman: Manning Fireworks |
| 72 | Johnny Blue Skies: Passage du Desir | 10 The Cure: Songs of a Lost World MJ Lenderman: Manning Fireworks Waxahatchee: Tigers Blood Jessica Pratt: Here in the Pitch Blood Incantation: Absolute Elsewhere Brittany Howard: What Now Adrianne Lenker: Bright Future Jack White: No Name Nilüfer Yanya: My Method Actor Mannequin Pussy: I Got Heaven |
| 73 | JPEGMAFIA: I LAY DOWN MY LIFE FOR YOU | 10 Geordie Greep: The New Sound Beth Gibbons: Lives Outgrown Kim Gordon: The Collective Blood Incantation: Absolute Elsewhere Kendrick Lamar: GNX Nala Sinephro: Endlessness Waxahatchee: Tigers Blood The Last Dinner Party: Prelude to Ecstasy Vampire Weekend: Only God Was Above Us Jessica Pratt: Here in the Pitch |
| 74 | Judas Priest: Invincible Shield | Blood Incantation: Absolute Elsewhere |
| 75 | Julia Holter: Something in the Room She Moves | 10 Adrianne Lenker: Bright Future Beth Gibbons: Lives Outgrown Arooj Aftab: Night Reign Chelsea Wolfe: She Reaches Out to She Reaches Out to She Floating Points: Cascade Geordie Greep: The New Sound Mount Eerie: Night Palace Blood Incantation: Absolute Elsewhere Kim Gordon: The Collective The Cure: Songs of a Lost World |
| 76 | Justice: Hyperdrama | 3 Jamie xx: In Waves Fontaines D.C.: Romance The Cure: Songs of a Lost World |
| 77 | KA: The Thief Next to Jesus | 10 Mach-Hommy: #RICHAXXHAITIAN Mannequin Pussy: I Got Heaven Mount Eerie: Night Palace LL COOL J: THE FORCE Cindy Lee: Diamond Jubilee Hurray for the Riff Raff: The Past Is Still Alive Kim Gordon: The Collective MJ Lenderman: Manning Fireworks Tyler, The Creator: CHROMAKOPIA Blood Incantation: Absolute Elsewhere |
| 78 | Kacey Musgraves: Deeper Well | 10 Sabrina Carpenter: Short n' Sweet Gracie Abrams: The Secret of Us Billie Eilish: HIT ME HARD AND SOFT Ariana Grande: eternal sunshine Beyoncé: COWBOY CARTER Taylor Swift: THE TORTURED POETS DEPARTMENT Kendrick Lamar: GNX Jack White: No Name Doechii: Alligator Bites Never Heal The Cure: Songs of a Lost World |
| 79 | Kali Uchis: ORQUÍDEAS | 10 Doechii: Alligator Bites Never Heal ScHoolboy Q: BLUE LIPS Billie Eilish: HIT ME HARD AND SOFT Beyoncé: COWBOY CARTER Tyla: TYLA Vampire Weekend: Only God Was Above Us Clairo: Charm Ekko Astral: pink balloons Empress Of: For Your Consideration Sabrina Carpenter: Short n' Sweet |
| 80 | Kamasi Washington: Fearless Movement | 4 Vampire Weekend: Only God Was Above Us The Cure: Songs of a Lost World Adrianne Lenker: Bright Future Billie Eilish: HIT ME HARD AND SOFT |
| 81 | KAYTRANADA: Timeless | 3 Sabrina Carpenter: Short n' Sweet Beyoncé: COWBOY CARTER The Cure: Songs of a Lost World |
| 82 | Kelly Lee Owens: Dreamstate | 10 Nia Archives: Silence Is Loud SPRINTS: Letter To Self Tyla: TYLA English Teacher: This Could Be Texas Clairo: Charm Waxahatchee: Tigers Blood Magdalena Bay: Imaginal Disk Vampire Weekend: Only God Was Above Us Sabrina Carpenter: Short n' Sweet Fontaines D.C.: Romance |
| 83 | Kendrick Lamar: GNX | 10 Doechii: Alligator Bites Never Heal Beyoncé: COWBOY CARTER Billie Eilish: HIT ME HARD AND SOFT ScHoolboy Q: BLUE LIPS Jack White: No Name MJ Lenderman: Manning Fireworks Tyler, The Creator: CHROMAKOPIA The Cure: Songs of a Lost World Vince Staples: Dark Times Sabrina Carpenter: Short n' Sweet |
| 84 | Kim Deal: Nobody Loves You More | 10 The Cure: Songs of a Lost World Nick Cave & The Bad Seeds: Wild God English Teacher: This Could Be Texas Mannequin Pussy: I Got Heaven Billie Eilish: HIT ME HARD AND SOFT The Last Dinner Party: Prelude to Ecstasy Beyoncé: COWBOY CARTER Fontaines D.C.: Romance MJ Lenderman: Manning Fireworks Adrianne Lenker: Bright Future |
| 85 | Kim Gordon: The Collective | 10 Waxahatchee: Tigers Blood Mount Eerie: Night Palace Adrianne Lenker: Bright Future MJ Lenderman: Manning Fireworks Jessica Pratt: Here in the Pitch Nala Sinephro: Endlessness Magdalena Bay: Imaginal Disk Cindy Lee: Diamond Jubilee Mannequin Pussy: I Got Heaven Nilüfer Yanya: My Method Actor |
| 86 | KNEECAP: Fine Art | 10 Fontaines D.C.: Romance The Last Dinner Party: Prelude to Ecstasy Adrianne Lenker: Bright Future Amyl and The Sniffers: Cartoon Darkness IDLES: TANGK English Teacher: This Could Be Texas St. Vincent: All Born Screaming Knocked Loose: You Won't Go Before You're Supposed To Tyler, The Creator: CHROMAKOPIA Clairo: Charm |
| 87 | Knocked Loose: You Won't Go Before You're Supposed To | 10 Chat Pile: Cool World Bring Me The Horizon: POST HUMAN: NeX GEn Chelsea Wolfe: She Reaches Out to She Reaches Out to She Blood Incantation: Absolute Elsewhere Lip Critic: Hex Dealer Touché Amoré: Spiral in a Straight Line Foxing: Foxing Zach Bryan: The Great American Bar Scene Magdalena Bay: Imaginal Disk The Cure: Songs of a Lost World |
| 88 | The Last Dinner Party: Prelude to Ecstasy | 10 English Teacher: This Could Be Texas St. Vincent: All Born Screaming Fontaines D.C.: Romance Adrianne Lenker: Bright Future The Cure: Songs of a Lost World Rachel Chinouriri: What A Devastating Turn of Events Vampire Weekend: Only God Was Above Us Amyl and The Sniffers: Cartoon Darkness Wunderhorse: Midas Laura Marling: Patterns in Repeat |
| 89 | Laura Marling: Patterns in Repeat | 10 The Last Dinner Party: Prelude to Ecstasy Vampire Weekend: Only God Was Above Us English Teacher: This Could Be Texas Kim Gordon: The Collective Los Campesinos!: All Hell Nadine Shah: Filthy Underneath Adrianne Lenker: Bright Future Magdalena Bay: Imaginal Disk SPRINTS: Letter To Self The Cure: Songs of a Lost World |
| 90 | The Lemon Twigs: A Dream Is All We Know | 2 Beth Gibbons: Lives Outgrown Kim Gordon: The Collective |
| 91 | Lime Garden: One More Thing | 2 English Teacher: This Could Be Texas The Last Dinner Party: Prelude to Ecstasy |
| 92 | Lip Critic: Hex Dealer | 3 Knocked Loose: You Won't Go Before You're Supposed To Mannequin Pussy: I Got Heaven Fontaines D.C.: Romance |
| 93 | Liquid Mike: Paul Bunyan's Slingshot | 2 Waxahatchee: Tigers Blood MJ Lenderman: Manning Fireworks |
| 94 | LL COOL J: THE FORCE | 6 Mach-Hommy: #RICHAXXHAITIAN KA: The Thief Next to Jesus Kendrick Lamar: GNX Doechii: Alligator Bites Never Heal Mk.gee: Two Star & The Dream Police Tyler, The Creator: CHROMAKOPIA |
| 95 | Los Campesinos!: All Hell | 10 Laura Marling: Patterns in Repeat Arooj Aftab: Night Reign English Teacher: This Could Be Texas The Cure: Songs of a Lost World Nala Sinephro: Endlessness Nilüfer Yanya: My Method Actor Fontaines D.C.: Romance Magdalena Bay: Imaginal Disk Vampire Weekend: Only God Was Above Us Cindy Lee: Diamond Jubilee |
| 96 | Mabe Fratti: Sentir Que No Sabes | 10 Nala Sinephro: Endlessness Jlin: Akoma Cassandra Jenkins: My Light, My Destroyer Arooj Aftab: Night Reign MJ Lenderman: Manning Fireworks Jessica Pratt: Here in the Pitch Kim Gordon: The Collective Nilüfer Yanya: My Method Actor Chat Pile: Cool World Cindy Lee: Diamond Jubilee |
| 97 | Mach-Hommy: #RICHAXXHAITIAN | 10 KA: The Thief Next to Jesus LL COOL J: THE FORCE Cindy Lee: Diamond Jubilee ScHoolboy Q: BLUE LIPS Doechii: Alligator Bites Never Heal Chat Pile: Cool World Tyler, The Creator: CHROMAKOPIA Kendrick Lamar: GNX Blood Incantation: Absolute Elsewhere Mk.gee: Two Star & The Dream Police |
| 98 | Magdalena Bay: Imaginal Disk | 10 Cindy Lee: Diamond Jubilee Mannequin Pussy: I Got Heaven Vampire Weekend: Only God Was Above Us Adrianne Lenker: Bright Future Waxahatchee: Tigers Blood MJ Lenderman: Manning Fireworks Vince Staples: Dark Times Kim Gordon: The Collective English Teacher: This Could Be Texas Chat Pile: Cool World |
| 99 | Maggie Rogers: Don't Forget Me | 10 Vince Staples: Dark Times A. G. Cook: Britpop Billie Eilish: HIT ME HARD AND SOFT Jack White: No Name ScHoolboy Q: BLUE LIPS Taylor Swift: THE TORTURED POETS DEPARTMENT Kendrick Lamar: GNX Clairo: Charm Ariana Grande: eternal sunshine Kali Uchis: ORQUÍDEAS |
| 100 | Mannequin Pussy: I Got Heaven | 10 MJ Lenderman: Manning Fireworks Waxahatchee: Tigers Blood The Cure: Songs of a Lost World Fontaines D.C.: Romance Blood Incantation: Absolute Elsewhere Magdalena Bay: Imaginal Disk Mount Eerie: Night Palace Jessica Pratt: Here in the Pitch Vampire Weekend: Only God Was Above Us Cindy Lee: Diamond Jubilee |
| 101 | The Marías: Submarine | 4 Clairo: Charm The Last Dinner Party: Prelude to Ecstasy Billie Eilish: HIT ME HARD AND SOFT Tyler, The Creator: CHROMAKOPIA |
| 102 | Mdou Moctar: Funeral for Justice | 10 MJ Lenderman: Manning Fireworks Jessica Pratt: Here in the Pitch MIKE & Tony Seltzer: Pinball Cindy Lee: Diamond Jubilee Arooj Aftab: Night Reign E L U C I D: REVELATOR Waxahatchee: Tigers Blood Jack White: No Name The Cure: Songs of a Lost World Kim Gordon: The Collective |
| 103 | Michael Kiwanuka: Small Changes | 3 Amyl and The Sniffers: Cartoon Darkness The Cure: Songs of a Lost World The Last Dinner Party: Prelude to Ecstasy |
| 104 | MIKE & Tony Seltzer: Pinball | 4 Mdou Moctar: Funeral for Justice Magdalena Bay: Imaginal Disk Cindy Lee: Diamond Jubilee The Cure: Songs of a Lost World |
| 105 | MJ Lenderman: Manning Fireworks | 10 Waxahatchee: Tigers Blood Jessica Pratt: Here in the Pitch Mannequin Pussy: I Got Heaven The Cure: Songs of a Lost World Father John Misty: Mahashmashana Cindy Lee: Diamond Jubilee Fontaines D.C.: Romance Mdou Moctar: Funeral for Justice Mk.gee: Two Star & The Dream Police Nilüfer Yanya: My Method Actor |
| 106 | Mk.gee: Two Star & The Dream Police | 10 MJ Lenderman: Manning Fireworks Clairo: Charm Tyler, The Creator: CHROMAKOPIA Doechii: Alligator Bites Never Heal Fontaines D.C.: Romance Cindy Lee: Diamond Jubilee Billie Eilish: HIT ME HARD AND SOFT Nilüfer Yanya: My Method Actor Waxahatchee: Tigers Blood Tems: Born in the Wild |
| 107 | Mount Eerie: Night Palace | 10 Kim Gordon: The Collective Hurray for the Riff Raff: The Past Is Still Alive Mannequin Pussy: I Got Heaven Bladee: Cold Visions Cindy Lee: Diamond Jubilee Chat Pile: Cool World KA: The Thief Next to Jesus Magdalena Bay: Imaginal Disk Arooj Aftab: Night Reign Floating Points: Cascade |
| 108 | Mustafa: Dunya | 10 Tyler, The Creator: CHROMAKOPIA Mk.gee: Two Star & The Dream Police ScHoolboy Q: BLUE LIPS Nilüfer Yanya: My Method Actor Kendrick Lamar: GNX Doechii: Alligator Bites Never Heal MJ Lenderman: Manning Fireworks Waxahatchee: Tigers Blood Fontaines D.C.: Romance The Cure: Songs of a Lost World |
| 109 | Nadine Shah: Filthy Underneath | 10 The Last Dinner Party: Prelude to Ecstasy Laura Marling: Patterns in Repeat Amyl and The Sniffers: Cartoon Darkness Kim Gordon: The Collective English Teacher: This Could Be Texas St. Vincent: All Born Screaming Adrianne Lenker: Bright Future Jessica Pratt: Here in the Pitch Waxahatchee: Tigers Blood Vampire Weekend: Only God Was Above Us |
| 110 | Nala Sinephro: Endlessness | 10 Mabe Fratti: Sentir Que No Sabes Kim Gordon: The Collective Arooj Aftab: Night Reign Cassandra Jenkins: My Light, My Destroyer Still House Plants: If I don't make it, I love u E L U C I D: REVELATOR Jlin: Akoma MJ Lenderman: Manning Fireworks Waxahatchee: Tigers Blood Chanel Beads: Your Day Will Come |
| 111 | Nia Archives: Silence Is Loud | 10 Kelly Lee Owens: Dreamstate Rachel Chinouriri: What A Devastating Turn of Events Tyla: TYLA The Last Dinner Party: Prelude to Ecstasy Amyl and The Sniffers: Cartoon Darkness SPRINTS: Letter To Self English Teacher: This Could Be Texas Doechii: Alligator Bites Never Heal Kali Uchis: ORQUÍDEAS Nala Sinephro: Endlessness |
| 112 | Nick Cave & The Bad Seeds: Wild God | 10 The Cure: Songs of a Lost World Fontaines D.C.: Romance St. Vincent: All Born Screaming Vampire Weekend: Only God Was Above Us Billie Eilish: HIT ME HARD AND SOFT The Last Dinner Party: Prelude to Ecstasy Adrianne Lenker: Bright Future Jamie xx: In Waves Kim Deal: Nobody Loves You More Jack White: No Name |
| 113 | Nilüfer Yanya: My Method Actor | 10 MJ Lenderman: Manning Fireworks The Cure: Songs of a Lost World Waxahatchee: Tigers Blood Arooj Aftab: Night Reign Magdalena Bay: Imaginal Disk Cassandra Jenkins: My Light, My Destroyer Kim Gordon: The Collective Blood Incantation: Absolute Elsewhere Tyler, The Creator: CHROMAKOPIA Mannequin Pussy: I Got Heaven |
| 114 | Nubya Garcia: ODYSSEY | The Cure: Songs of a Lost World |
| 115 | NxWorries: WHY LAWD? | 8 Vince Staples: Dark Times ScHoolboy Q: BLUE LIPS Doechii: Alligator Bites Never Heal Tyler, The Creator: CHROMAKOPIA Vampire Weekend: Only God Was Above Us Beyoncé: COWBOY CARTER Kendrick Lamar: GNX Billie Eilish: HIT ME HARD AND SOFT |
| 116 | Opeth: The Last Will and Testament | Blood Incantation: Absolute Elsewhere |
| 117 | Pet Shop Boys: Nonetheless | 2 Waxahatchee: Tigers Blood The Cure: Songs of a Lost World |
| 118 | Rachel Chinouriri: What A Devastating Turn of Events | 10 The Last Dinner Party: Prelude to Ecstasy Nia Archives: Silence Is Loud Wunderhorse: Midas English Teacher: This Could Be Texas Billie Eilish: HIT ME HARD AND SOFT Amyl and The Sniffers: Cartoon Darkness SPRINTS: Letter To Self Fontaines D.C.: Romance The Cure: Songs of a Lost World Clairo: Charm |
| 119 | Ravyn Lenae: Bird's Eye | 2 Doechii: Alligator Bites Never Heal Mannequin Pussy: I Got Heaven |
| 120 | Rema: HEIS | 10 Tems: Born in the Wild Tyla: TYLA Mk.gee: Two Star & The Dream Police ScHoolboy Q: BLUE LIPS Sabrina Carpenter: Short n' Sweet Waxahatchee: Tigers Blood Beyoncé: COWBOY CARTER Tyler, The Creator: CHROMAKOPIA Kendrick Lamar: GNX MJ Lenderman: Manning Fireworks |
| 121 | Remi Wolf: Big Ideas | 10 St. Vincent: All Born Screaming A. G. Cook: Britpop Nilüfer Yanya: My Method Actor Sabrina Carpenter: Short n' Sweet Doechii: Alligator Bites Never Heal Magdalena Bay: Imaginal Disk Clairo: Charm Billie Eilish: HIT ME HARD AND SOFT Kali Uchis: ORQUÍDEAS Waxahatchee: Tigers Blood |
| 122 | Rosali: Bite Down | 4 Vampire Weekend: Only God Was Above Us Doechii: Alligator Bites Never Heal Billie Eilish: HIT ME HARD AND SOFT The Cure: Songs of a Lost World |
| 123 | Sabrina Carpenter: Short n' Sweet | 10 Billie Eilish: HIT ME HARD AND SOFT Beyoncé: COWBOY CARTER Doechii: Alligator Bites Never Heal Taylor Swift: THE TORTURED POETS DEPARTMENT Ariana Grande: eternal sunshine Kacey Musgraves: Deeper Well MJ Lenderman: Manning Fireworks Tyla: TYLA Kendrick Lamar: GNX Magdalena Bay: Imaginal Disk |
| 124 | ScHoolboy Q: BLUE LIPS | 10 Doechii: Alligator Bites Never Heal Tyler, The Creator: CHROMAKOPIA Vince Staples: Dark Times GloRilla: GLORIOUS Kendrick Lamar: GNX Kali Uchis: ORQUÍDEAS Future & Metro Boomin: WE DON'T TRUST YOU NxWorries: WHY LAWD? The Cure: Songs of a Lost World Beyoncé: COWBOY CARTER |
| 125 | Shabaka: Perceive Its Beauty, Acknowledge Its Grace | Kim Gordon: The Collective |
| 126 | The Smile: Wall of Eyes | 10 The Cure: Songs of a Lost World Fontaines D.C.: Romance The Last Dinner Party: Prelude to Ecstasy Amyl and The Sniffers: Cartoon Darkness English Teacher: This Could Be Texas Tyler, The Creator: CHROMAKOPIA Beth Gibbons: Lives Outgrown Nilüfer Yanya: My Method Actor St. Vincent: All Born Screaming Mannequin Pussy: I Got Heaven |
| 127 | SPRINTS: Letter To Self | 10 English Teacher: This Could Be Texas Amyl and The Sniffers: Cartoon Darkness IDLES: TANGK Wunderhorse: Midas The Last Dinner Party: Prelude to Ecstasy Kelly Lee Owens: Dreamstate Rachel Chinouriri: What A Devastating Turn of Events Nia Archives: Silence Is Loud Laura Marling: Patterns in Repeat Magdalena Bay: Imaginal Disk |
| 128 | St. Vincent: All Born Screaming | 10 The Last Dinner Party: Prelude to Ecstasy Billie Eilish: HIT ME HARD AND SOFT Dua Lipa: Radical Optimism The Cure: Songs of a Lost World Nick Cave & The Bad Seeds: Wild God Clairo: Charm Fontaines D.C.: Romance Vampire Weekend: Only God Was Above Us Adrianne Lenker: Bright Future Waxahatchee: Tigers Blood |
| 129 | Still House Plants: If I don't make it, I love u | 10 Nala Sinephro: Endlessness Kim Gordon: The Collective Kali Uchis: ORQUÍDEAS Arooj Aftab: Night Reign Vampire Weekend: Only God Was Above Us Laura Marling: Patterns in Repeat Nilüfer Yanya: My Method Actor Mannequin Pussy: I Got Heaven Adrianne Lenker: Bright Future Cindy Lee: Diamond Jubilee |
| 130 | Taylor Swift: THE TORTURED POETS DEPARTMENT | 10 Sabrina Carpenter: Short n' Sweet Billie Eilish: HIT ME HARD AND SOFT Beyoncé: COWBOY CARTER The Cure: Songs of a Lost World Maggie Rogers: Don't Forget Me The Last Dinner Party: Prelude to Ecstasy Kacey Musgraves: Deeper Well Vampire Weekend: Only God Was Above Us Ariana Grande: eternal sunshine Rachel Chinouriri: What A Devastating Turn of Events |
| 131 | Tems: Born in the Wild | 10 Rema: HEIS Tyla: TYLA Mk.gee: Two Star & The Dream Police Beyoncé: COWBOY CARTER Sabrina Carpenter: Short n' Sweet Clairo: Charm Billie Eilish: HIT ME HARD AND SOFT Doechii: Alligator Bites Never Heal Tyler, The Creator: CHROMAKOPIA Kendrick Lamar: GNX |
| 132 | This Is Lorelei: Box For Buddy, Box For Star | 10 Wild Pink: Dulling The Horns Being Dead: EELS Mannequin Pussy: I Got Heaven Waxahatchee: Tigers Blood Vampire Weekend: Only God Was Above Us Cindy Lee: Diamond Jubilee MJ Lenderman: Manning Fireworks Nilüfer Yanya: My Method Actor Blood Incantation: Absolute Elsewhere Magdalena Bay: Imaginal Disk |
| 133 | Thou: Umbilical | 4 Chelsea Wolfe: She Reaches Out to She Reaches Out to She Blood Incantation: Absolute Elsewhere ScHoolboy Q: BLUE LIPS The Cure: Songs of a Lost World |
| 134 | Tierra Whack: WORLD WIDE WHACK | 4 Doechii: Alligator Bites Never Heal Sabrina Carpenter: Short n' Sweet Beyoncé: COWBOY CARTER Billie Eilish: HIT ME HARD AND SOFT |
| 135 | Touché Amoré: Spiral in a Straight Line | 10 Chat Pile: Cool World Knocked Loose: You Won't Go Before You're Supposed To Chelsea Wolfe: She Reaches Out to She Reaches Out to She The Cure: Songs of a Lost World Blood Incantation: Absolute Elsewhere Mannequin Pussy: I Got Heaven Beth Gibbons: Lives Outgrown Tyler, The Creator: CHROMAKOPIA Fontaines D.C.: Romance Waxahatchee: Tigers Blood |
| 136 | Tyla: TYLA | 10 Rema: HEIS Tems: Born in the Wild Sabrina Carpenter: Short n' Sweet Kali Uchis: ORQUÍDEAS Fabiana Palladino: Fabiana Palladino Nia Archives: Silence Is Loud Doechii: Alligator Bites Never Heal GloRilla: GLORIOUS ScHoolboy Q: BLUE LIPS Kelly Lee Owens: Dreamstate |
| 137 | Tyler, The Creator: CHROMAKOPIA | 10 ScHoolboy Q: BLUE LIPS Fontaines D.C.: Romance The Cure: Songs of a Lost World Mk.gee: Two Star & The Dream Police Doechii: Alligator Bites Never Heal Waxahatchee: Tigers Blood Adrianne Lenker: Bright Future Cindy Lee: Diamond Jubilee Kendrick Lamar: GNX Jack White: No Name |
| 138 | Vampire Weekend: Only God Was Above Us | 10 Adrianne Lenker: Bright Future The Cure: Songs of a Lost World Fontaines D.C.: Romance The Last Dinner Party: Prelude to Ecstasy Jack White: No Name Magdalena Bay: Imaginal Disk Father John Misty: Mahashmashana Billie Eilish: HIT ME HARD AND SOFT MJ Lenderman: Manning Fireworks Laura Marling: Patterns in Repeat |
| 139 | Vince Staples: Dark Times | 10 ScHoolboy Q: BLUE LIPS Magdalena Bay: Imaginal Disk Common & Pete Rock: The Auditorium Vol. 1 Future & Metro Boomin: WE DON'T TRUST YOU NxWorries: WHY LAWD? Maggie Rogers: Don't Forget Me Kendrick Lamar: GNX Doechii: Alligator Bites Never Heal Jack White: No Name Beyoncé: COWBOY CARTER |
| 140 | Waxahatchee: Tigers Blood | 10 MJ Lenderman: Manning Fireworks The Cure: Songs of a Lost World Mannequin Pussy: I Got Heaven Kim Gordon: The Collective Jessica Pratt: Here in the Pitch Magdalena Bay: Imaginal Disk Adrianne Lenker: Bright Future Cindy Lee: Diamond Jubilee Fontaines D.C.: Romance Vampire Weekend: Only God Was Above Us |
| 141 | Wild Pink: Dulling The Horns | 8 This Is Lorelei: Box For Buddy, Box For Star Father John Misty: Mahashmashana Magdalena Bay: Imaginal Disk Vampire Weekend: Only God Was Above Us MJ Lenderman: Manning Fireworks Mannequin Pussy: I Got Heaven Waxahatchee: Tigers Blood Fontaines D.C.: Romance |
| 142 | Wishy: Triple Seven | 3 Mannequin Pussy: I Got Heaven Fontaines D.C.: Romance MJ Lenderman: Manning Fireworks |
| 143 | Wunderhorse: Midas | 8 The Last Dinner Party: Prelude to Ecstasy English Teacher: This Could Be Texas Rachel Chinouriri: What A Devastating Turn of Events Amyl and The Sniffers: Cartoon Darkness SPRINTS: Letter To Self Fontaines D.C.: Romance The Cure: Songs of a Lost World Billie Eilish: HIT ME HARD AND SOFT |
| 144 | Yard Act: Where's My Utopia? | 8 The Last Dinner Party: Prelude to Ecstasy Jamie xx: In Waves Beth Gibbons: Lives Outgrown Fontaines D.C.: Romance Vampire Weekend: Only God Was Above Us The Cure: Songs of a Lost World Adrianne Lenker: Bright Future MJ Lenderman: Manning Fireworks |
| 145 | Yasmin Williams: Acadia | 2 ScHoolboy Q: BLUE LIPS Vampire Weekend: Only God Was Above Us |
| 146 | Zach Bryan: The Great American Bar Scene | 6 Knocked Loose: You Won't Go Before You're Supposed To Kendrick Lamar: GNX Billie Eilish: HIT ME HARD AND SOFT The Cure: Songs of a Lost World Sabrina Carpenter: Short n' Sweet Beyoncé: COWBOY CARTER |
That's interesting to me. What's interesting to you?
[PS: Oh, here, I put this dataset up in raw interactive form, so you can play with it yourself if you want.]
For anybody interested in the particular subgeekery of language design, I thought of five potential ways to address the Dactal usability issue of
1. Try to embrace the weirdness. This is always my first discipline. Don't be too quick to treat every weirdness as a problem that has to be solved. Some things are weird compared to outside references, but normal in a new system's internal logic. If a weirdness is really a conceptual inconsistency, embracing it will keep feeling awkward no matter how many times you do it. In this case, I think the most persuasive critique is that Dactal tries to keep the human language of queries in the vocabulary of the data, not the system, and the mechanics in punctuation, but "of" is uneasily poised somewhere between the two. You can work out what
2. Use the tools you already have. Dactal already has a way to create additional properties. So if we want to group tracks by artist and then be able to get back to the grouped tracks with "tracks" instead of saying "of", we can just do this:
3. If we're going to explore adding a new feature to grouping to handling this idea directly, we could just move "tracks=of" from a separate annotation (|) operation into the grouping operation:
4. Doing the relabeling with the same syntax in the other order, however, like:
5. I implemented #4, but I do keep coming back to #2 in my mind. It might be generally useful to have a way of renaming existing properties instead of just duplicating them. Or a way of deleting them, for that matter. So I also implemented
.of.of:=where are we?.of
being hard to follow.
1. Try to embrace the weirdness. This is always my first discipline. Don't be too quick to treat every weirdness as a problem that has to be solved. Some things are weird compared to outside references, but normal in a new system's internal logic. If a weirdness is really a conceptual inconsistency, embracing it will keep feeling awkward no matter how many times you do it. In this case, I think the most persuasive critique is that Dactal tries to keep the human language of queries in the vocabulary of the data, not the system, and the mechanics in punctuation, but "of" is uneasily poised somewhere between the two. You can work out what
topsong=(.of:@1.of#(.of.track info.album:album_type=album),(.of.ts):@1.of.track info)
is saying, but it's work. A query language should help humans talk to each other about our goals, not just help humans talk to computers about accomplishing them. Is that second "@1" in the right place? If we want each artist's second song, do we change one of these @1s to @2, or both, or something else? It's hard to tell. Actually, it's impossible to tell from looking at just this part of the query. You have to trace the logic back through the context of the rest of the query (or the data) to figure out where each "of" leaves you. Which also means that changes to the earlier parts of the query are likely to require changing this part, and in ways that also aren't obvious. Past-me knew what each "of" was doing when he wrote this; future-me is already getting prepared to resent past-me for making him rededuce that stuff again later.
2. Use the tools you already have. Dactal already has a way to create additional properties. So if we want to group tracks by artist and then be able to get back to the grouped tracks with "tracks" instead of saying "of", we can just do this:
tracks/artist|tracks=of
and now each group has both "tracks" and "of". This doubles the amount of data, though, and in multi-level logic that can quickly start to become a non-trivial cost.
3. If we're going to explore adding a new feature to grouping to handling this idea directly, we could just move "tracks=of" from a separate annotation (|) operation into the grouping operation:
tracks/artist,tracks=of
but that syntax already has a meaning, which is to group tracks by both artist and "tracks", where "tracks" is calculated by traversing the "of" property of the tracks. Tracks, in this dummy example, don't have an "of" property, but in the actual playlist query we started with, two of the three grouping layers are grouping previous groups, which do have "of"s, which is exactly the thing I'm trying to improve. So that's clearly not the way.
4. Doing the relabeling with the same syntax in the other order, however, like:
tracks/artist,of=tracks
sacrifices strict parallelism but actually fits into the existing model kind of nicely. Because groups have automatic "of" properties, it would already be problematic to use "of" as a grouping key. So this way fits a useful function into a previously unused space in the language. We haven't completely eliminated the system-vocabulary presence of "of", but now each "of" appears only once, in the bookkeeping of creating groups, and all subsequent logic about those groups can stick to the vocabulary of the data. So my original example becomes:topsong=(
.song:@1.songdates
#(.streams.track info.album:album_type=album),
(.streams.ts)
:@1.streams:@1.track info
)
and now not only is it clear exactly what each @1 means (the first is the first song, the second is the first of the re-sorted songdates), but it's easy to notice that we probably want that third @1 to pick the first song's first songdate's first stream, and given that we're sorting songdates entirely by properties from streams, maybe what we should really be doing is actually.song:@1.songdates
#(.streams.track info.album:album_type=album),
(.streams.ts)
:@1.streams:@1.track info
)
topsong=(.songs:@1.songdates.streams#(.track info.album:album_type=album),ts:@1.track info)
and now the query language is doing its real job of helping us think about what we intend to ask.
5. I implemented #4, but I do keep coming back to #2 in my mind. It might be generally useful to have a way of renaming existing properties instead of just duplicating them. Or a way of deleting them, for that matter. So I also implemented
tracks/artist|tracks=-of
for renaming, andtracks/artist|-of
for deleting. This pushes on issues of mutability and persistence that I probably haven't entirely thought through, so it might not be the right design, but trying is a way of finding out.