
20 December 2015 to 17 April 2015
¶ Our economy relies on math. Too bad our culture doesn't value it. · 20 December 2015 listen/tech
A couple days ago The Washington Post published a plaintive T Bone Burnett lament headlined "Our culture loves music. Too bad our economy doesn’t value it."
The specific outrage that the piece builds from is this quote:
"In 2014, sales from vinyl records made more than all of the ad-supported on-demand streams on services such as YouTube."
which comes from this article at The Verge:
Vinyl sales are more valuable than ad-supported streaming in 2015
which is referring to this RIAA report:
News and Notes on 2015 Mid-Year RIAA Shipment and Revenue Statistics
But if you you read the actual report, you discover that this comparison is wildly and almost certainly deliberately misleading.
In the case of ad-supported on-demand streaming (a category which, for technical reasons, really only counts YouTube and a small part of Spotify), the report is calculating actual royalties paid to the music industry, which is sensible.
In the case of vinyl, however, the report is calculating the hypothetical total suggested retail prices of all vinyl albums shipped.
So:
- shipped, not sold
- suggested retail prices, not actual prices paid
- suggested gross prices paid to retailers, not net revenue to the music industry after taking into account wholesale prices and manufacturing and distribution costs
This comparison is insane. It's like saying that your dog is taller than you based on how tall the dog would be if it learned to walk upright on the amazing stilts you dreamed about making.
Tellingly, the RIAA does not provide any of the figures necessary to accurately correct the comparison, but my rough guess is that the vinyl figure is inflated by a factor of somewhere between 4 and 10.
A more plausible conclusion, thus, would be something like "Even amidst a crazed temporary vinyl-fetish bubble-market, 'free' ad-supported YouTube and Spotify streams actually made more money for musicians by a wide margin."
And of course this arbitrary legal streaming category excludes Pandora and other non-on-demand streaming, which added more than twice as much revenue to the music industry, and all paid-subscrition streaming like Spotify Premium, which added three times as much.
Even more glaringly, the equation also excludes paid downloading, and CDs and other physical formats. But put together, all stream/download-based music sources contributed 4 times as much actual music-industry revenue as the hypothetical total retail value of all the physically-distributed music. So by my 4-10x guess at figure inflation, this would mean that these newfangled demons from the callous musician-hating technology cabal produced somewhere between 16x and 40x as much music-industry support as the old, supposedly-musician-loving physical objects.
So while I'm not claiming that there aren't still serious systemic problems in the music economy, we're never going to fix them by letting disingenuous numbers lead us on literally counter-productive crusades against the future.
(Minor PS to Burnett: It also makes particularly bad sense to portray Taylor Swift as a defender of musicians in this specific context. When she dramatically took her music off of Spotify, which has both free and paid tiers, she left it on YouTube, which at the time had only a free tier and later changed to exactly the same free/paid model as Spotify. This might be a defensible business decision for her or her corporate backers, but there's no coherent way in which it's a moral one that has anything to do with other people.)
(PPS for anybody reading this who doesn't already know me: I work at Spotify, but this is my personal blog and these are my personal opinions. I am not directly involved in Spotify business deals or music-industry policy, but I have loved music for far, far longer than I have worked at Spotify, and I wouldn't be doing the latter if I thought it was hostile to the former.)
The specific outrage that the piece builds from is this quote:
"In 2014, sales from vinyl records made more than all of the ad-supported on-demand streams on services such as YouTube."
which comes from this article at The Verge:
Vinyl sales are more valuable than ad-supported streaming in 2015
which is referring to this RIAA report:
News and Notes on 2015 Mid-Year RIAA Shipment and Revenue Statistics
But if you you read the actual report, you discover that this comparison is wildly and almost certainly deliberately misleading.
In the case of ad-supported on-demand streaming (a category which, for technical reasons, really only counts YouTube and a small part of Spotify), the report is calculating actual royalties paid to the music industry, which is sensible.
In the case of vinyl, however, the report is calculating the hypothetical total suggested retail prices of all vinyl albums shipped.
So:
- shipped, not sold
- suggested retail prices, not actual prices paid
- suggested gross prices paid to retailers, not net revenue to the music industry after taking into account wholesale prices and manufacturing and distribution costs
This comparison is insane. It's like saying that your dog is taller than you based on how tall the dog would be if it learned to walk upright on the amazing stilts you dreamed about making.
Tellingly, the RIAA does not provide any of the figures necessary to accurately correct the comparison, but my rough guess is that the vinyl figure is inflated by a factor of somewhere between 4 and 10.
A more plausible conclusion, thus, would be something like "Even amidst a crazed temporary vinyl-fetish bubble-market, 'free' ad-supported YouTube and Spotify streams actually made more money for musicians by a wide margin."
And of course this arbitrary legal streaming category excludes Pandora and other non-on-demand streaming, which added more than twice as much revenue to the music industry, and all paid-subscrition streaming like Spotify Premium, which added three times as much.
Even more glaringly, the equation also excludes paid downloading, and CDs and other physical formats. But put together, all stream/download-based music sources contributed 4 times as much actual music-industry revenue as the hypothetical total retail value of all the physically-distributed music. So by my 4-10x guess at figure inflation, this would mean that these newfangled demons from the callous musician-hating technology cabal produced somewhere between 16x and 40x as much music-industry support as the old, supposedly-musician-loving physical objects.
So while I'm not claiming that there aren't still serious systemic problems in the music economy, we're never going to fix them by letting disingenuous numbers lead us on literally counter-productive crusades against the future.
(Minor PS to Burnett: It also makes particularly bad sense to portray Taylor Swift as a defender of musicians in this specific context. When she dramatically took her music off of Spotify, which has both free and paid tiers, she left it on YouTube, which at the time had only a free tier and later changed to exactly the same free/paid model as Spotify. This might be a defensible business decision for her or her corporate backers, but there's no coherent way in which it's a moral one that has anything to do with other people.)
(PPS for anybody reading this who doesn't already know me: I work at Spotify, but this is my personal blog and these are my personal opinions. I am not directly involved in Spotify business deals or music-industry policy, but I have loved music for far, far longer than I have worked at Spotify, and I wouldn't be doing the latter if I thought it was hostile to the former.)
¶ (periodic reminder) · 6 December 2015
YOUR IMAGINATION
IS MORE POWERFUL
THAN YOUR ENEMIES
IS MORE POWERFUL
THAN YOUR ENEMIES
¶ A Fancier Hat · 4 December 2015 listen/tech
If you like new music but hate text, the Sorting Hat had a lot of both. I've changed it a little, in a way I should probably just explain with a quick before-and-after:

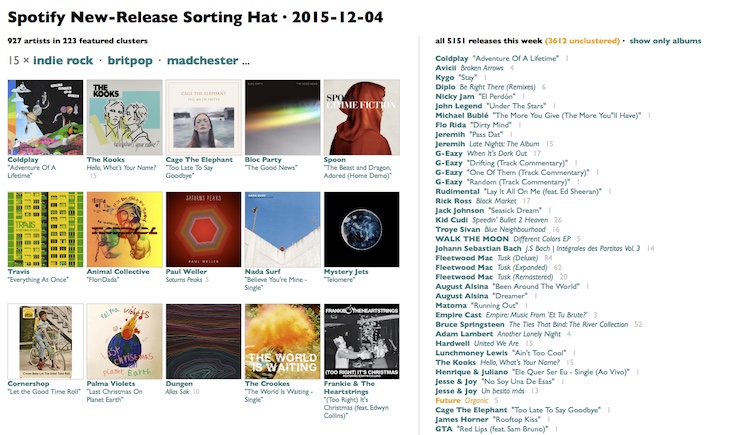
And if pictures aren't exciting enough by themselves, I've hooked up these particular pictures to play preview clips if you click them. Two senses down, three to go.
I didn't put images on the big list of thousands of releases on the right, because I did and my browser got very sad about it and I had to spend a lot of time apologizing. But you can click the little gray track-count numbers to hear previews on that side of the page, too.
And if you really, really don't like images, there's a tiny inscrutable gray widget in the top right corner of the page that you can click to put things mostly back how they were before, except a little nicer, and with the previews.
PS: In working on this I had another good reminder of the value of already knowing some right answers to the questions you ask. I made a new song of my own last weekend, and it comes "out" today, but when I generated this week's Sorting Hat initially, my song wasn't on the list.
The reason turned out to be a small, subtle bug that only affected releases by extremely obscure artists (I currently have six (6) monthly listeners), which made it unlikely that I would ever have noticed it if I hadn't been looking for my own song.
It's fixed now. See if you can figure out which one is mine. I'll give you a hint. It's this one:
Maybe you don't care, but I do, and so does everybody else with 6 listeners who dreams of one day having 12 or even 20.
PPS: And if you are interested in discovering interesting music that is not quite as obscure as mine, you might enjoy some of these:
And if pictures aren't exciting enough by themselves, I've hooked up these particular pictures to play preview clips if you click them. Two senses down, three to go.
I didn't put images on the big list of thousands of releases on the right, because I did and my browser got very sad about it and I had to spend a lot of time apologizing. But you can click the little gray track-count numbers to hear previews on that side of the page, too.
And if you really, really don't like images, there's a tiny inscrutable gray widget in the top right corner of the page that you can click to put things mostly back how they were before, except a little nicer, and with the previews.
PS: In working on this I had another good reminder of the value of already knowing some right answers to the questions you ask. I made a new song of my own last weekend, and it comes "out" today, but when I generated this week's Sorting Hat initially, my song wasn't on the list.
The reason turned out to be a small, subtle bug that only affected releases by extremely obscure artists (I currently have six (6) monthly listeners), which made it unlikely that I would ever have noticed it if I hadn't been looking for my own song.
It's fixed now. See if you can figure out which one is mine. I'll give you a hint. It's this one:
Maybe you don't care, but I do, and so does everybody else with 6 listeners who dreams of one day having 12 or even 20.
PPS: And if you are interested in discovering interesting music that is not quite as obscure as mine, you might enjoy some of these:
¶ Warm Worms Against Winter · 1 December 2015 listen/tech
It's dark and cold and grim, and then the Christmas music starts.
Whether that makes things better or worse for you is your own decision, but at Spotify we're trying to help you either way.
So we try to keep Christmas music mostly out of The Needle, which is harder than you might think, because weary Christmas standards being dragged out of the bins show an activity curve disconcertingly similar to that of emergent new hipnesses.
But this year, instead of just trying to suppress this surge, I decided to suppress it but also chart it. And thus we get this, The Approaching Worms of Christmas:
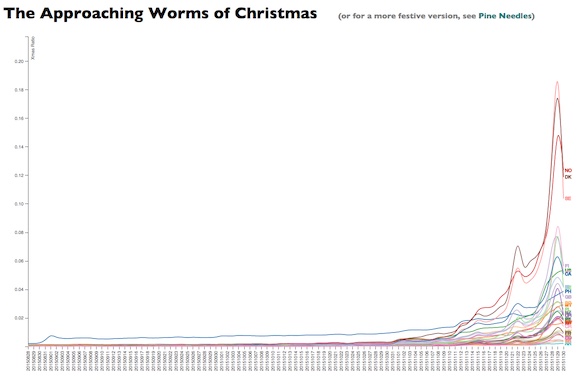
This chart will be updated every day or two until Christmas, and then maybe a few days afterwards just so we can all feel calmer again.
Watching the worms rise, actually, I also became morbidly curious what all that music was, and so I also also reversed the polarity of my anti-Christmas-music filters for The Needle, to try to only get rising (or re-surfacing) Christmas music. And of course the results of this could only be called Pine Needles:
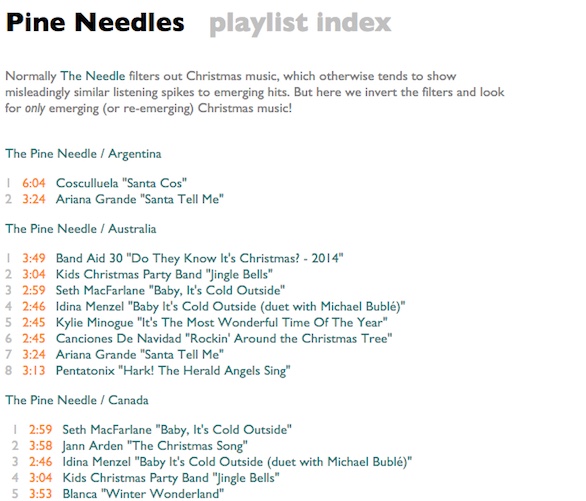
These will also be updated dailyish until Christmas. I don't actually know whether they will end up reverting to chestnuts, or splaying into unimaginable craziness. We'll see. What's the fun of building a machine if you already know what it's going to do?
At any rate, welcome to the winter. Stay warm. There's music. It'll be OK.
Whether that makes things better or worse for you is your own decision, but at Spotify we're trying to help you either way.
So we try to keep Christmas music mostly out of The Needle, which is harder than you might think, because weary Christmas standards being dragged out of the bins show an activity curve disconcertingly similar to that of emergent new hipnesses.
But this year, instead of just trying to suppress this surge, I decided to suppress it but also chart it. And thus we get this, The Approaching Worms of Christmas:
This chart will be updated every day or two until Christmas, and then maybe a few days afterwards just so we can all feel calmer again.
Watching the worms rise, actually, I also became morbidly curious what all that music was, and so I also also reversed the polarity of my anti-Christmas-music filters for The Needle, to try to only get rising (or re-surfacing) Christmas music. And of course the results of this could only be called Pine Needles:
These will also be updated dailyish until Christmas. I don't actually know whether they will end up reverting to chestnuts, or splaying into unimaginable craziness. We'll see. What's the fun of building a machine if you already know what it's going to do?
At any rate, welcome to the winter. Stay warm. There's music. It'll be OK.
¶ Bombs Bursting in Stereo · 9 July 2015 listen/tech
During an interview with Wired, one of my Spotify co-workers explained the depth of our listening data by saying that we knew, for example, what the hottest song was in Cleveland on the 4th of July.
This was intended rhetorically, but the interviewer, reasonably if maybe over-literally, asked him what song it actually was. And thus I got an email.
We do, in fact, know what the hottest song was in Cleveland on the 4th of July. It was (for at least one definition of "hottest") Lee Greenwood's "God Bless The U.S.A.".
But I never like one-song answers when an army of semi-autonomous robots would suffice. Obviously we know a lot more than this one song. Patriotic July 4th listening spikes aren't as sharp or wide as the ones around Christmas, but that kind of just makes them easier to detect. And because July 4th is a native holiday here in the US, where Christmas is imported, the spikes are also interestingly regionalized.
So I did a little analysis of the songs whose Spotify streaming spiked most dramatically in individual American cities on July 4 compared to the rest of the world in the preceding week. 103 cities had distinct enough patterns to make statistically relevant top-40 lists of these songs, so I made playlists for all of those (and a sampler with 1 song from each), and then combined them into this insane grid-thing I use for making abstruse sense of a lot of lists at once:

Each number in the grid is the rank of that row's song in that column's city's 4th of July list. From this we can see that Tom Petty and The Heartbreakers' "American Girl" is the 4th of July song shared by the most cities. (But it ranks quite differently in different places, and some of the places where it doesn't even make the top 40 form a potentially telling set: the Bronx, Compton, Detroit, Houston, Newark...)
Pick your own city (the names along the top are links to the individual playlists in Spotify) and see if it sounds familiar.
I started to try to take the non-4th songs out of this, but quickly decided that that made things less interesting, so I didn't. This is what we were listening to on the 4th of July, 2015. There weren't fireworks all day, and next year will be partly different just like it will be partly the same.
If you like moving parts, you can re-center the grid by clicking the little gray arrow under any city. The cities whose listening was most similar to Cleveland's are mostly cities similarly insulated from glamor: Plano, Louisville, Cincinnati, St. Louis, Indianapolis, Pittsburgh, Orlando. But then there's Boston, not far away after all, with 3 of the same songs as Cleveland in the top 10, and more than half their top 40s in common. This makes sense to me. Bright lights and loud noises appeal to fairly basic instincts, and we are certainly drawn to them here.
But then, if you spin it again and look at the country from Boston's point of view, there's Portland Oregon, and San Francisco, and Seattle and New York and DC. I don't think you'd mistake Boston for John Mellencamp's "Small Town" for longer than a day. We wave the flags with enthusiasm, but then the cannons fire, and the last rockets leave the barges in the Charles, and before very long it's dark and quiet and north-eastern again, and we turn and walk back through the streets to our homes.
This was intended rhetorically, but the interviewer, reasonably if maybe over-literally, asked him what song it actually was. And thus I got an email.
We do, in fact, know what the hottest song was in Cleveland on the 4th of July. It was (for at least one definition of "hottest") Lee Greenwood's "God Bless The U.S.A.".
But I never like one-song answers when an army of semi-autonomous robots would suffice. Obviously we know a lot more than this one song. Patriotic July 4th listening spikes aren't as sharp or wide as the ones around Christmas, but that kind of just makes them easier to detect. And because July 4th is a native holiday here in the US, where Christmas is imported, the spikes are also interestingly regionalized.
So I did a little analysis of the songs whose Spotify streaming spiked most dramatically in individual American cities on July 4 compared to the rest of the world in the preceding week. 103 cities had distinct enough patterns to make statistically relevant top-40 lists of these songs, so I made playlists for all of those (and a sampler with 1 song from each), and then combined them into this insane grid-thing I use for making abstruse sense of a lot of lists at once:
Each number in the grid is the rank of that row's song in that column's city's 4th of July list. From this we can see that Tom Petty and The Heartbreakers' "American Girl" is the 4th of July song shared by the most cities. (But it ranks quite differently in different places, and some of the places where it doesn't even make the top 40 form a potentially telling set: the Bronx, Compton, Detroit, Houston, Newark...)
Pick your own city (the names along the top are links to the individual playlists in Spotify) and see if it sounds familiar.
I started to try to take the non-4th songs out of this, but quickly decided that that made things less interesting, so I didn't. This is what we were listening to on the 4th of July, 2015. There weren't fireworks all day, and next year will be partly different just like it will be partly the same.
If you like moving parts, you can re-center the grid by clicking the little gray arrow under any city. The cities whose listening was most similar to Cleveland's are mostly cities similarly insulated from glamor: Plano, Louisville, Cincinnati, St. Louis, Indianapolis, Pittsburgh, Orlando. But then there's Boston, not far away after all, with 3 of the same songs as Cleveland in the top 10, and more than half their top 40s in common. This makes sense to me. Bright lights and loud noises appeal to fairly basic instincts, and we are certainly drawn to them here.
But then, if you spin it again and look at the country from Boston's point of view, there's Portland Oregon, and San Francisco, and Seattle and New York and DC. I don't think you'd mistake Boston for John Mellencamp's "Small Town" for longer than a day. We wave the flags with enthusiasm, but then the cannons fire, and the last rockets leave the barges in the Charles, and before very long it's dark and quiet and north-eastern again, and we turn and walk back through the streets to our homes.
For amusement and curiosity, I calculated the 11th most popular song for every artist on Spotify, and then made a playlist of the most popular 1000 of these. This gives you a little sense of which artists get consistent attention beyond just their current hits.
And then, to go even deeper, I did it again with every artist's 100th most popular song.
And then, to go even deeper, I did it again with every artist's 100th most popular song.
| These Ones Go to 11
|
These Ones Go to 100
|
¶ Unfancy Machines · 10 June 2015 listen/tech
I spend a lot of time fiddling obsessively with the knobs on complicated music-discovery machines. I wouldn't do it if I didn't think it helped, and I spend a fair amount of that time pondering whether I'm confident that it's helping.
Your streaming music world is also about to be extra-complicated by more machinery for personalization, and I work on some of this, too. One clattering armada of machinery for trying to find music worth being discovered by somebody, and another one for trying to figure out which of that music is the music for which you are that somebody. It's kind of a wonder we can still hear over all that grinding.
Although, actually, it's less of a rhetorical wonder than an actual question. Can we hear over it? It's not inherently bad if your complicated thing is complicated, but it's bad if it's complicated and not better than something simpler. So in this spirit, I've added one more playlist to the end of The Needle, my array of emerging-song supposedly-discovering lists.
It is called The Straw. It is assembled by programmatically taking one track each from a random sample of 1000 or so of the both obscure and uncategorized releases from the current week's Spotify New-Release Sorting Hat.
There is no complicated scoring or optimizing or clustering, there is no personalization, there is no iteration or feedback or machine learning. Some of it probably isn't even new, or shouldn't have been uncategorized, or maybe shouldn't have been made. If my fancy machines are working, and if the underlying collectivist moral premise they implicitly represent -- that the world's listening patterns distinguish memorable music from forgettable -- has significant validity, then listening to this playlist should be a poor use of your time.
But those are non-trivial "if"s. If anybody claims that they do something mysterious and yet valuable, based on appealing but abstract assumptions, you ought to be able to demand that they, at least, have actually contemplated how the world would be if they didn't.
And this "they" is me, so here is my professional memento mori, an unfancy discovery engine that believes wholeheartedly, even when I have the courage to think I'm only pretending to, that to find amazing music you've never heard, all you need is a way to find music you've never heard.
Your streaming music world is also about to be extra-complicated by more machinery for personalization, and I work on some of this, too. One clattering armada of machinery for trying to find music worth being discovered by somebody, and another one for trying to figure out which of that music is the music for which you are that somebody. It's kind of a wonder we can still hear over all that grinding.
Although, actually, it's less of a rhetorical wonder than an actual question. Can we hear over it? It's not inherently bad if your complicated thing is complicated, but it's bad if it's complicated and not better than something simpler. So in this spirit, I've added one more playlist to the end of The Needle, my array of emerging-song supposedly-discovering lists.
It is called The Straw. It is assembled by programmatically taking one track each from a random sample of 1000 or so of the both obscure and uncategorized releases from the current week's Spotify New-Release Sorting Hat.
There is no complicated scoring or optimizing or clustering, there is no personalization, there is no iteration or feedback or machine learning. Some of it probably isn't even new, or shouldn't have been uncategorized, or maybe shouldn't have been made. If my fancy machines are working, and if the underlying collectivist moral premise they implicitly represent -- that the world's listening patterns distinguish memorable music from forgettable -- has significant validity, then listening to this playlist should be a poor use of your time.
But those are non-trivial "if"s. If anybody claims that they do something mysterious and yet valuable, based on appealing but abstract assumptions, you ought to be able to demand that they, at least, have actually contemplated how the world would be if they didn't.
And this "they" is me, so here is my professional memento mori, an unfancy discovery engine that believes wholeheartedly, even when I have the courage to think I'm only pretending to, that to find amazing music you've never heard, all you need is a way to find music you've never heard.
¶ Introducing: The Needle · 1 May 2015 listen/tech
The most constant motivating feeling in my life, I sometimes think, is the fear that there is genuinely amazing music somewhere that I am missing. This fear has been confirmed many, many times. So many times that I have spent even more of my time building machines to, depending on your perspective, either fight the fear or just confirm it more efficiently.
For the past couple years, one of these machines has been maintaining a playlist called The Echo Nest Discovery as an attempt to find some songs, independent of origin or style, that are either rocketing out of obscurity or rocketing just as cheerfully to the edge of obscurity before plummeting ignominiously back into the depths of it. This has been a pretty good machine. It has found me a lot of music I've enjoyed and would never otherwise have heard. (And also found a fair amount of music that I was already enjoying, which is good, or at least confidence-building.) I think of this list as the world on shuffle. It finds strange and wonderful things, although not every individual song is necessarily both.
But the Echo Nest's acquisition by Spotify has given me access to even more data than we already had, and among many other things, I have built a new fear-confirming machine. I call this one The Needle, because there are needles on turntables and needles on detection instruments and needles in haystacks and I think there was once some other thing.
This machine is, I think maybe, a little better than the last one. Hopefully. It's definitely a little fancier. Where the Echo Nest Discovery found one batch of things every week, there are actually Needles of three different gauges:
Current is the shallowest search, and basically looks for potential major world hits near the beginning of their rise. Some of these will come from places far from your ears, some of them you may already be trying to get out of your head. But if three lists sounds like too many to you, then this is probably the one you want.
Emerging attempts a balance between velocity and obscurity, closer to the spirit of the Echo Nest Discovery. Most people will not have heard of most of the things that show up on this list, but a few of these songs will probably go on to be hits. Many of the others will be great. If you follow this list, you will expand your world.
Underground digs deep. Maybe sometimes too deep. You may not be prepared for what you find at this depth. Coelacanths with poor hygiene. Terrible ripoff covers of new songs that aren't on Spotify yet, dubious remixes of songs that may have been dubious to begin with, novelty hits from places you weren't actually planning to visit. Somebody, somewhere, is listening to this stuff, but people are weird. Yes, even here, some of these songs are gathering their powers to escape into the light, but if you follow this list, it is probably because your problem with the darkness isn't that it's dark, but just that there's so deliriously much of it.
And if all of these things sound great, there's also a consolidated version that combines these three lists into one. This is even more of the world on even randomer shuffle.
But one of the ways we now have a lot more data is that we know where every Spotify listener is listening. I have already been using this to tell what people are listening to in countries and cities, and now it allows me to look for things that are maybe-rocketing out of local obscurities. So there are, in fact, sets of Needles for every country where Spotify has enough listeners. For example:
Some of the smaller regions don't have (or don't fill) all three lists yet, but we're constantly growing, and all these lists are updated every week (usually some time on Saturday), so the current list of lists is here, and it will only keep growing.
And maybe you won't care. Maybe you already think you have enough music in your life, or that you need more but you already have sources. Maybe you think that what a thousand people in Estonia suddenly discovered yesterday isn't relevant to you. There are, after all, many ways to live, and you have to choose carefully among all the many potential torments. Maybe you don't see a haystack and wonder if there is a needle in it.
But what I have come to believe, and why I encourage you to not conclude so quickly that you know what you need, is that the needle/haystack metaphor misses the point. The haystack doesn't conceal needles, the haystack is made of needles. I've been thinking of this as a "discovery" tool, and it can be that, but it can also just be a way of listening.
So put the needle on the record. The things people are listening to far away only seem weird because "far away" used to matter. You used to have to go to Estonia to hear what people were listening to there. Estonia used to be a "there". It's still partly a "there" for licensing reasons, as not all of the songs in all of these lists will be available in all the other regions. Art and joy always move faster than law. But eventually we always catch up. Everywhere can be a here now. Or tomorrow, or next week.
Do you want to hear what that will be like? It will be amazing.
For the past couple years, one of these machines has been maintaining a playlist called The Echo Nest Discovery as an attempt to find some songs, independent of origin or style, that are either rocketing out of obscurity or rocketing just as cheerfully to the edge of obscurity before plummeting ignominiously back into the depths of it. This has been a pretty good machine. It has found me a lot of music I've enjoyed and would never otherwise have heard. (And also found a fair amount of music that I was already enjoying, which is good, or at least confidence-building.) I think of this list as the world on shuffle. It finds strange and wonderful things, although not every individual song is necessarily both.
But the Echo Nest's acquisition by Spotify has given me access to even more data than we already had, and among many other things, I have built a new fear-confirming machine. I call this one The Needle, because there are needles on turntables and needles on detection instruments and needles in haystacks and I think there was once some other thing.
This machine is, I think maybe, a little better than the last one. Hopefully. It's definitely a little fancier. Where the Echo Nest Discovery found one batch of things every week, there are actually Needles of three different gauges:
Current is the shallowest search, and basically looks for potential major world hits near the beginning of their rise. Some of these will come from places far from your ears, some of them you may already be trying to get out of your head. But if three lists sounds like too many to you, then this is probably the one you want.
Emerging attempts a balance between velocity and obscurity, closer to the spirit of the Echo Nest Discovery. Most people will not have heard of most of the things that show up on this list, but a few of these songs will probably go on to be hits. Many of the others will be great. If you follow this list, you will expand your world.
Underground digs deep. Maybe sometimes too deep. You may not be prepared for what you find at this depth. Coelacanths with poor hygiene. Terrible ripoff covers of new songs that aren't on Spotify yet, dubious remixes of songs that may have been dubious to begin with, novelty hits from places you weren't actually planning to visit. Somebody, somewhere, is listening to this stuff, but people are weird. Yes, even here, some of these songs are gathering their powers to escape into the light, but if you follow this list, it is probably because your problem with the darkness isn't that it's dark, but just that there's so deliriously much of it.
And if all of these things sound great, there's also a consolidated version that combines these three lists into one. This is even more of the world on even randomer shuffle.
But one of the ways we now have a lot more data is that we know where every Spotify listener is listening. I have already been using this to tell what people are listening to in countries and cities, and now it allows me to look for things that are maybe-rocketing out of local obscurities. So there are, in fact, sets of Needles for every country where Spotify has enough listeners. For example:
Some of the smaller regions don't have (or don't fill) all three lists yet, but we're constantly growing, and all these lists are updated every week (usually some time on Saturday), so the current list of lists is here, and it will only keep growing.
And maybe you won't care. Maybe you already think you have enough music in your life, or that you need more but you already have sources. Maybe you think that what a thousand people in Estonia suddenly discovered yesterday isn't relevant to you. There are, after all, many ways to live, and you have to choose carefully among all the many potential torments. Maybe you don't see a haystack and wonder if there is a needle in it.
But what I have come to believe, and why I encourage you to not conclude so quickly that you know what you need, is that the needle/haystack metaphor misses the point. The haystack doesn't conceal needles, the haystack is made of needles. I've been thinking of this as a "discovery" tool, and it can be that, but it can also just be a way of listening.
So put the needle on the record. The things people are listening to far away only seem weird because "far away" used to matter. You used to have to go to Estonia to hear what people were listening to there. Estonia used to be a "there". It's still partly a "there" for licensing reasons, as not all of the songs in all of these lists will be available in all the other regions. Art and joy always move faster than law. But eventually we always catch up. Everywhere can be a here now. Or tomorrow, or next week.
Do you want to hear what that will be like? It will be amazing.
¶ The Satan:Noise Ratio · 19 April 2015 essay/listen/tech
Through a roundabout series of connections, I got invited to be part of a roundtable panel at EMP Pop 2015, which ended up (in keeping with this year's themes of Music, Weirdness and Transgression) being a group deliberation on the subject of The Worst Song in the World.
And since I was going to be there, and conference rules allowed for solo proposals in addition to the group thing, I figured I might as well also try something fun and weird and outside of my usual current data-alchemical domain.
In the end the thing ended up being not quite free of data-alchemy in the same way that my songs without drums always somehow develop drum tracks. But it's not about data alchemy. At least mostly not.
All the talks are supposed to eventually be available in audio form, but in the meantime, here is the script I was more or less working from. To reproduce the auditorium experience you should blast at least the first 20 seconds or so of each song as you encounter it in the text, and imagine me intoning the names of the songs in monster-truck-rally announcer-voice, and then saying everything else really fast and excitedly because a) you only get 20 minutes, and b) it was 9:20am on the Sunday morning after the Saturday night conference party and some people might need a little help relocating their attentiveness.
(Also, be forewarned that neither the talk nor the music discussed is intended for underage audiences or people who are insecure about religion or genuinely frightened by grown men growling like monsters.)
The Satan:Noise Ratio
or
Triangulations of the Abyss
I grew up in what I wouldn't call a religious community, exactly, but certainly one that was dominated by the assumption of Christianity. My social status was kind of established when I told two members of the football team that the universe was formed out of dust, not Godliness, and it really didn't make any difference whether you liked that idea or not. This was second grade. We had a football team in second grade.
By the time I discovered heavy metal, I was pretty ready for some kind of comprehensive alternative. Science fiction, existentialism, atheism, algebra, Black Sabbath. These all seemed to frighten people, which suggested they were good and powerful ingredients. But if you're going to fight against football in Texas, you have to have your shit organized. You need a program.
Obviously as an atheist I wasn't going to believe in Satan any more than I was going to believe in elves, but the idea of Satanism seemed potentially compelling anyway. Like Scientology, but with roots, and better iconography, and fewer videotapes to buy. And I had learned a lot from reading the liner notes to Rush albums, so I dug into Black Sabbath albums with the same enthusiasm.
Black Sabbath "After Forever"
[You have to remember that at the time, that was really heavy. But the words go like this:]
Black Sabbath "Heaven & Hell"
But OK, what about Judas Priest. Didn't two guys kill themselves after listening to Judas Priest? Now we're getting serious.
Judas Priest "Saints in Hell"
But whatever. Before I found the Satanism I was looking for, New Wave happened, and it turned out that androgyny and drum machines scared the football boys way more than Satan.
And then I left Texas and went to Harvard and took on a very different set of social challenges. So the next time I cycled back into metal, as I always do no matter how many other things I'm into, I wasn't looking for more elaborate pentagrams to shock football boys, I was looking for more hermeneutic nuances to situate and contextualize metal for comparative-lit majors who listened to the Minutemen and the Talking Heads.
Slayer. The Antichrist. Fucking yes. Slayer makes Sabbath with Ozzy sound like Wings, and Sabbath with Dio sound like Van Halen with Sammy Hagar.
Slayer "The Antichrist"
But what about Bathory? In Nomine Satanas. Fucking Latin! Or something...
Bathory "In Nomine Satanas"
Emperor. These are Norwegian actual church-burning dudes. Although, it's Scandinavia, so the church-burning was actually part of a progressive urban planning scheme with multi-use pentagrams in pleasant, radiant-heated public spaces.
Emperor "Inno a Satana"
Gorgoroth "Possessed by Satan"
And maybe what we fear guides our evasions so inexorably that we always end up confirming our suspicions by our nature, but my love of metal motivated and informed my work designing data-analysis software as much as it haunted my attempts to understand emotional resonance, and gradually over the years my writing about music for people bled into writing about music for computers, and that's how I eventually ended up at Spotify, where we have a lot of computers and the largest mass of data about music that humanity has ever collected. And this makes it possible to find out about a lot of metal that you might not otherwise know about. A lot. And a lot of everything else. So I ended up making this genre map, to try to make some sense of it all.

And having organized the world into 1375 genres (which is approximately 666 times 2), I can now answer some other questions about them. Just a few days ago, in fact, purely coincidentally and in no way because I was writing this talk at the last minute without a really clear idea where I was going with it, I decided to reverse-index all the words in the titles of all the songs in the world, and then, using BLACK MATH, find and rank the words that appear most disproportionately in each genre.
It wasn't totally obvious whether this would produce a magic quantification of scattered souls, or a polite visit from some Mumford-and-Sons fans in the IT department, but here are some examples of what it produced in a few genres you might know:
a cappella: medley love somebody your girl home time over will with when need around life what tonight song that don't just
acoustic blues: blues woman boogie baby mama moan down mississippi gonna ain't going worried chicago shake long don't rider jail poor woogie
modern country rock: country beer that's that whiskey love good like cowboy truck don't she's carolina back ain't just wanna this with dirt
east coast hip hop: featuring edited kool explicit rhyme triple hood shit album game check ghetto what streets money flow version that style
west coast rap: gangsta dogg featuring niggaz nate snoop hood ghetto playa money pimp thang shit smoke game bitch life funk ain't west
I'd say that shit is doing something. [The whole thing is here.]
Using this, I can finally figure out the most Satanic of all metal subgenres. It is Black Thrash, whose top words go like this:
satanic blasphemy unholy death infernal antichrist satan hell blood holocaust evil metal nuclear doom vengeance black flames darkness funeral iron
If Satanism is fucking anywhere, it is here.
Nifelheim "Envoy of Lucifer"
OK, no idea what they're saying there.
Destroyer 666 "Satanic Speed Metal"
Um.
Warhammer "The Claw of Religion"
Sathanas "Reign of the Antichrist"
However, I have a lot of other metal subgenres to work with, and I can actually reorganize the world as if Black Thrash were its point of origin, and then as we move slowly away from that point, genre by genre, we can start to see the patterns change.
"Satan" begins to disappear.
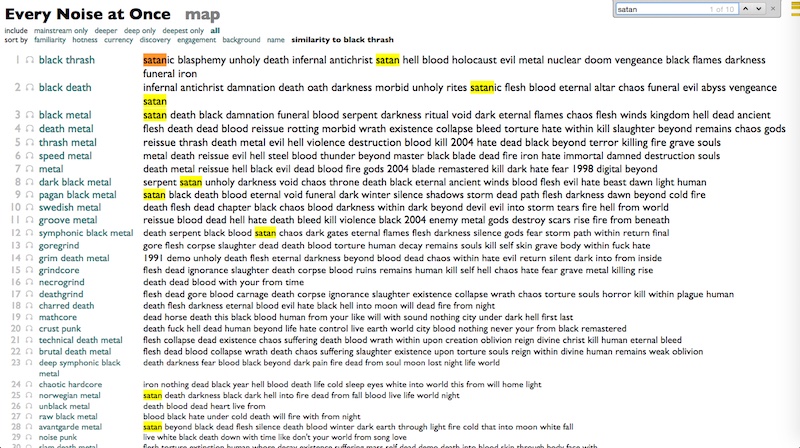
"Christ" goes away.
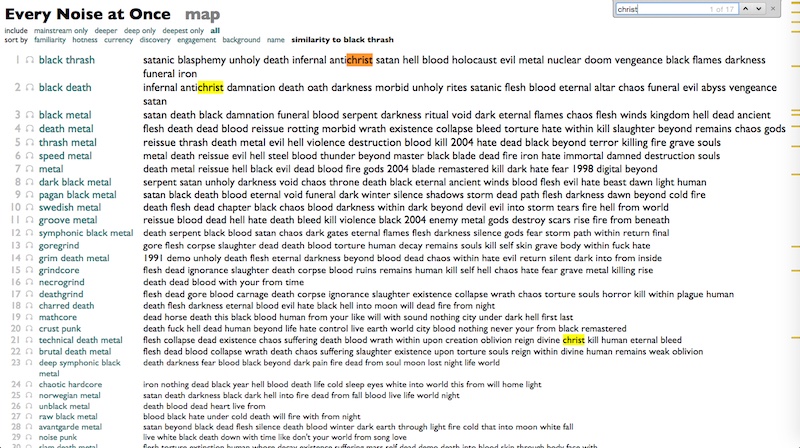
"Damnation" no longer so much of a concern.
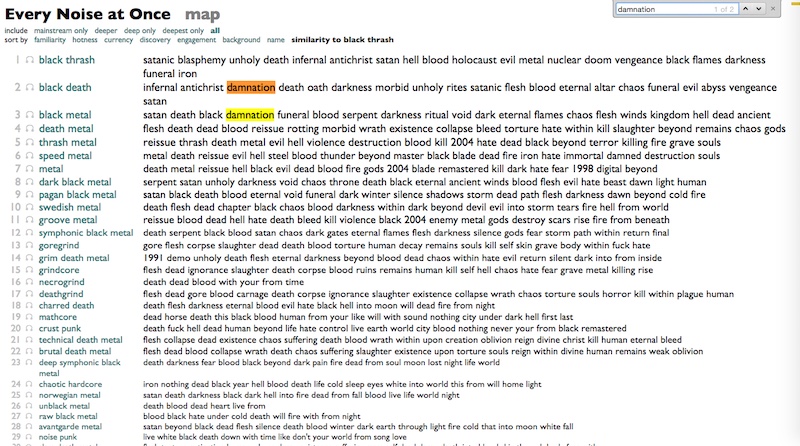
"Chaos" starts to appear.
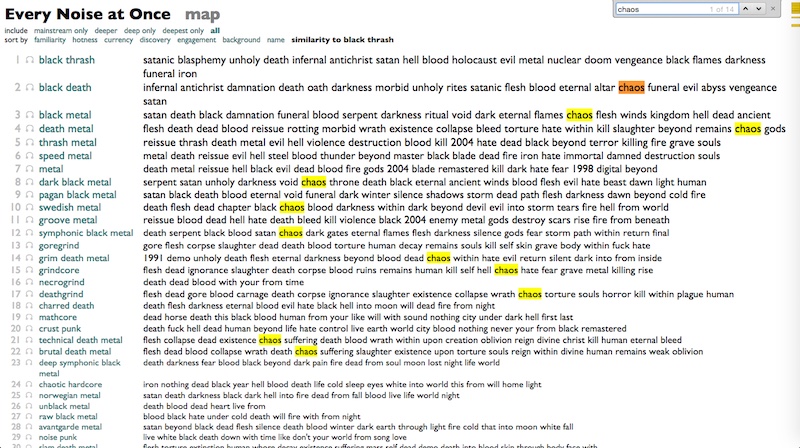
"Darkness" is everywhere.
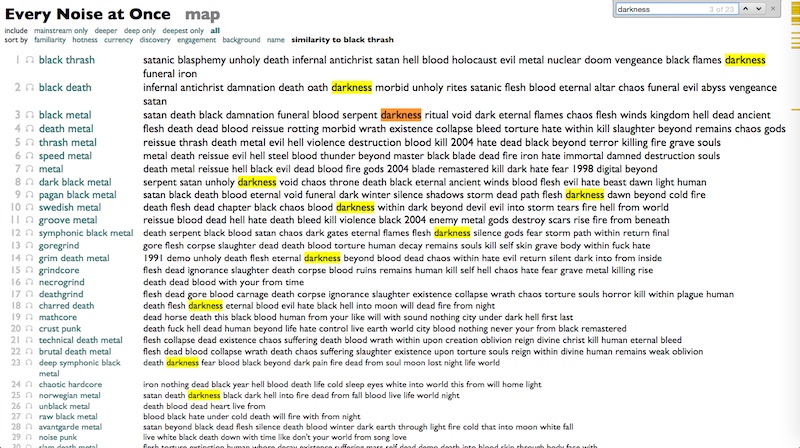
"Eternal" fascinates us.
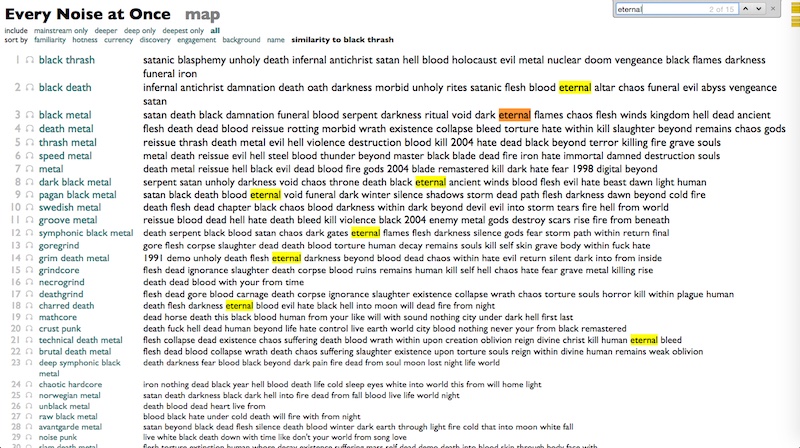
As does "Beyond".
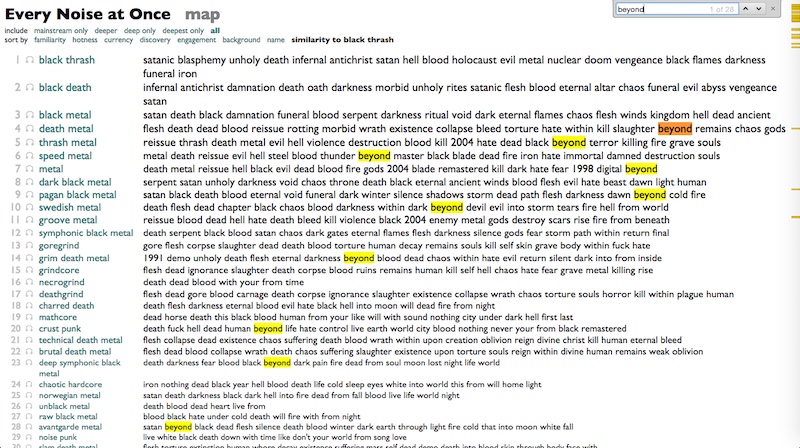
"Death", always death.
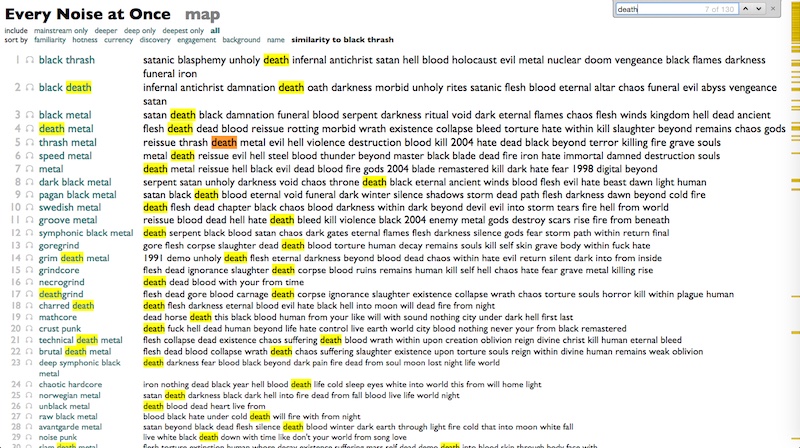
And over and over, at the top of almost every list that doesn't start with "Death": "Flesh".
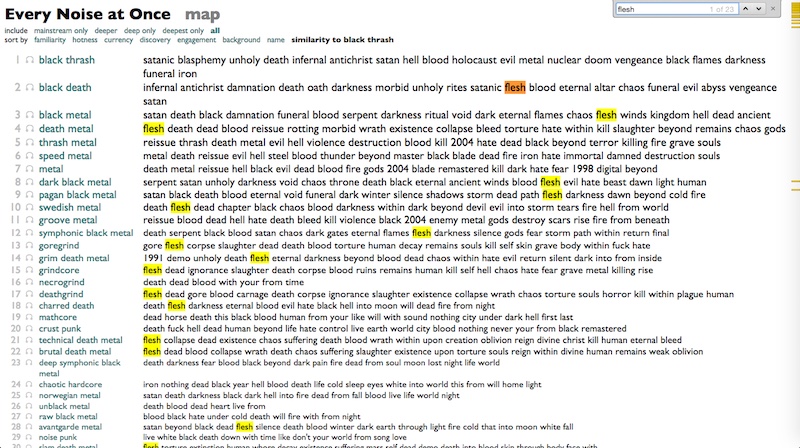
Except groove metal, where the number 1 term is "Reissue".
So my mistake, maybe, was in assuming I was looking for a philosophy that called itself Satanic. Give up that constraint, and ideas start to coalesce after all.
Entombed "Left Hand Path"
Celtic Frost "Os Abysmi Vel Daath"
OK, first of all, the band is called Totalselfhatred, and they sound like this. Dreamy.
Deathspell Omega "Chaining the Katechon"
That's a 22-minute song, and it does not fade in.
1. Babel. Acceptance of chaos, instead of a futile struggle for order or serenity
2. The Codex. To exist in chaos is to seek complexity over simplicity
3. The Void. There is beauty in darkness
4. The Scythe. There are either no illusions, or all illusions, but either way, only death is real
Which all adds up, I think, to something that I basically understood in second grade, after all: grimly acknowledged free will. That is the philosophical core of metal, as an art form. That is the exact rebellion I was seeking. To choose Satan, and particularly to choose Satan without giving him any positive qualities, is to assert that the act of choosing is more important than the actual choice. To choose death is to assert that choosing is more important than living. To choose death symbolically is somewhat more powerful than choosing it literally, because you can choose it symbolically more than once, while gives you a chance to refine your symbolism.
Blut Aus Nord "The Choir of the Dead"
That is Blut Aus Nord's "The Choir of the Dead", from an album actually called The Work Which Transforms God. What does it say? I dunno. But what does it mean? "Hail Satan" is "Think for yourself" plus noise.
Thank you, and see you in Hell.
[The whole playlist that I was playing from is on Spotify here: Triangulations of the Abyss.]
Thanks to the Program Committee and the audience for indulging this whim, and particularly to Eric Weisbard for backing up his early-morning scheduling of this racket by showing up to moderate the session himself.
And since I was going to be there, and conference rules allowed for solo proposals in addition to the group thing, I figured I might as well also try something fun and weird and outside of my usual current data-alchemical domain.
In the end the thing ended up being not quite free of data-alchemy in the same way that my songs without drums always somehow develop drum tracks. But it's not about data alchemy. At least mostly not.
All the talks are supposed to eventually be available in audio form, but in the meantime, here is the script I was more or less working from. To reproduce the auditorium experience you should blast at least the first 20 seconds or so of each song as you encounter it in the text, and imagine me intoning the names of the songs in monster-truck-rally announcer-voice, and then saying everything else really fast and excitedly because a) you only get 20 minutes, and b) it was 9:20am on the Sunday morning after the Saturday night conference party and some people might need a little help relocating their attentiveness.
(Also, be forewarned that neither the talk nor the music discussed is intended for underage audiences or people who are insecure about religion or genuinely frightened by grown men growling like monsters.)
The Satan:Noise Ratio
or
Triangulations of the Abyss
I grew up in what I wouldn't call a religious community, exactly, but certainly one that was dominated by the assumption of Christianity. My social status was kind of established when I told two members of the football team that the universe was formed out of dust, not Godliness, and it really didn't make any difference whether you liked that idea or not. This was second grade. We had a football team in second grade.
By the time I discovered heavy metal, I was pretty ready for some kind of comprehensive alternative. Science fiction, existentialism, atheism, algebra, Black Sabbath. These all seemed to frighten people, which suggested they were good and powerful ingredients. But if you're going to fight against football in Texas, you have to have your shit organized. You need a program.
Obviously as an atheist I wasn't going to believe in Satan any more than I was going to believe in elves, but the idea of Satanism seemed potentially compelling anyway. Like Scientology, but with roots, and better iconography, and fewer videotapes to buy. And I had learned a lot from reading the liner notes to Rush albums, so I dug into Black Sabbath albums with the same enthusiasm.
Black Sabbath "After Forever"
[You have to remember that at the time, that was really heavy. But the words go like this:]
I think it was true it was people like you that crucified ChristPuzzling. But then, as if realizing they were missing something, they got a new singer whose name was Dio, and made an album called Heaven & Hell.
I think it is sad the opinion you had was the only one voiced
Will you be so sure when your day is near, say you don't believe?
You had the chance but you turned it down, now you can't retrieve
Black Sabbath "Heaven & Hell"
Sing me a song, you're a singerThe music: solid. The lyrics? Not exactly "Red Barchetta".
Do me a wrong, you're a bringer of evil
The Devil is never a maker
The less that you give, you're a taker
So it's on and on and on, it's Heaven and Hell, oh well
…
Fool, fool! You've got to bleed for the dancer!
But OK, what about Judas Priest. Didn't two guys kill themselves after listening to Judas Priest? Now we're getting serious.
Judas Priest "Saints in Hell"
Cover your fistsOK, if I wanted a fucking rhyming "evil" version of Noah's Ark...
Razor your spears
It's been our possession
For 8,000 years
Fetch the scream eagles
Unleash the wild cats
Set loose the king cobras
And blood sucking bats
But whatever. Before I found the Satanism I was looking for, New Wave happened, and it turned out that androgyny and drum machines scared the football boys way more than Satan.
And then I left Texas and went to Harvard and took on a very different set of social challenges. So the next time I cycled back into metal, as I always do no matter how many other things I'm into, I wasn't looking for more elaborate pentagrams to shock football boys, I was looking for more hermeneutic nuances to situate and contextualize metal for comparative-lit majors who listened to the Minutemen and the Talking Heads.
Slayer. The Antichrist. Fucking yes. Slayer makes Sabbath with Ozzy sound like Wings, and Sabbath with Dio sound like Van Halen with Sammy Hagar.
Slayer "The Antichrist"
I am the AntichristSo, that's not Satanic, that's Christian. I mean, it's sort of ironic, Slayer of course were the original modern hipsters.
All love is lost
Insanity is what I am
Eternally my soul will rot (rot... rot)
But what about Bathory? In Nomine Satanas. Fucking Latin! Or something...
Bathory "In Nomine Satanas"
Ink the pen with bloodJesus fucking christ: more fealty.
Now sign your destiny to me
Emperor. These are Norwegian actual church-burning dudes. Although, it's Scandinavia, so the church-burning was actually part of a progressive urban planning scheme with multi-use pentagrams in pleasant, radiant-heated public spaces.
Emperor "Inno a Satana"
O' mighty Lord of the Night. Master of beasts. Bringer of awe and derision.Satan's uvula! "Harkee"?
Thou whose spirit lieth upon every act of oppression, hatred and strife.
Thou whose presence dwelleth in every shadow.
Thou who strengthen the power of every quietus.
Thou who sway every plague and storm.
Harkee.
Gorgoroth "Possessed by Satan"
worldwide revolution has occurredWe rape the nuns with desire? This is a program of sorts, I guess. But not one that offered solutions to any problems I actually had. But after a while, I kind of stopped asking music to solve any problems in my life that weren't about music. As an adult, the main thing I asked from my Satanic Norwegian metal was leads for where I could find more of it. The most constant internal theme in my life has been the desperate gnawing suspicion that all the music I know is only the tiniest sliver of what actually exists.
holy war, execution of sodomy
We are possessed by the moon
We are possessed by evil
We are possessed by Satan
possessed
possessed by satan
and then we rape the nuns with desire
And maybe what we fear guides our evasions so inexorably that we always end up confirming our suspicions by our nature, but my love of metal motivated and informed my work designing data-analysis software as much as it haunted my attempts to understand emotional resonance, and gradually over the years my writing about music for people bled into writing about music for computers, and that's how I eventually ended up at Spotify, where we have a lot of computers and the largest mass of data about music that humanity has ever collected. And this makes it possible to find out about a lot of metal that you might not otherwise know about. A lot. And a lot of everything else. So I ended up making this genre map, to try to make some sense of it all.
And having organized the world into 1375 genres (which is approximately 666 times 2), I can now answer some other questions about them. Just a few days ago, in fact, purely coincidentally and in no way because I was writing this talk at the last minute without a really clear idea where I was going with it, I decided to reverse-index all the words in the titles of all the songs in the world, and then, using BLACK MATH, find and rank the words that appear most disproportionately in each genre.
It wasn't totally obvious whether this would produce a magic quantification of scattered souls, or a polite visit from some Mumford-and-Sons fans in the IT department, but here are some examples of what it produced in a few genres you might know:
a cappella: medley love somebody your girl home time over will with when need around life what tonight song that don't just
acoustic blues: blues woman boogie baby mama moan down mississippi gonna ain't going worried chicago shake long don't rider jail poor woogie
modern country rock: country beer that's that whiskey love good like cowboy truck don't she's carolina back ain't just wanna this with dirt
east coast hip hop: featuring edited kool explicit rhyme triple hood shit album game check ghetto what streets money flow version that style
west coast rap: gangsta dogg featuring niggaz nate snoop hood ghetto playa money pimp thang shit smoke game bitch life funk ain't west
I'd say that shit is doing something. [The whole thing is here.]
Using this, I can finally figure out the most Satanic of all metal subgenres. It is Black Thrash, whose top words go like this:
satanic blasphemy unholy death infernal antichrist satan hell blood holocaust evil metal nuclear doom vengeance black flames darkness funeral iron
If Satanism is fucking anywhere, it is here.
Nifelheim "Envoy of Lucifer"
OK, no idea what they're saying there.
Destroyer 666 "Satanic Speed Metal"
Um.
Warhammer "The Claw of Religion"
Since the beginning of timeIsn't that actually the narration from the beginning of The Fifth Element?
A weapon was built and protected
To keep the balance in line
To guard the "forces of the light"
Do you hear the cries of all the ones that fell?
Sathanas "Reign of the Antichrist"
From the fall of grace-I shall rise againWell, it's certainly Satanic. But it's Satanism as mirror-image Christianity. Like, imagine if Jackson Pollock's avant-garde transgression was taking Vermeer paintings and repainting them with left and right reversed!!!! To be fair, that's the usual way in which revolutions collapse into politics, hating the status quo's conclusions but being unable to escape its assumptions.
Avenging chosen one-Known as Satan’s son
However, I have a lot of other metal subgenres to work with, and I can actually reorganize the world as if Black Thrash were its point of origin, and then as we move slowly away from that point, genre by genre, we can start to see the patterns change.
"Satan" begins to disappear.
"Christ" goes away.
"Damnation" no longer so much of a concern.
"Chaos" starts to appear.
"Darkness" is everywhere.
"Eternal" fascinates us.
As does "Beyond".
"Death", always death.
And over and over, at the top of almost every list that doesn't start with "Death": "Flesh".
Except groove metal, where the number 1 term is "Reissue".
So my mistake, maybe, was in assuming I was looking for a philosophy that called itself Satanic. Give up that constraint, and ideas start to coalesce after all.
Entombed "Left Hand Path"
No one will take my soul awayEnslaved "Ethica Odini"
I carry my own will and make my day
You have the key to mysteryDantalion "Onward to Darkness"
Pick up the runes; unveil and see
Existence is your own adversary,Mitochondrion "Eternal Contempt of Man"
a path full of pain and madness.
Now the earth, sea, and sky all have tornDodecahedron "I, Chronocrator"
Now a gate from the void hath been born
Both the watchers and the unholy do agree
Eradicate that vermin filth humanity
Reigning formulas undoneWe are approaching a version of Nihilism that is not an absence, but an embrace of nothingness, an embrace of the finite, of finity.
Oaths sworn into silence
Our world will be without form
Our earth will be void
Celtic Frost "Os Abysmi Vel Daath"
Where I am there is no thing.Totalselfhatred "Enlightenment"
No God, no me, no inbetween.
OK, first of all, the band is called Totalselfhatred, and they sound like this. Dreamy.
I cannot change your destiny, can only help you thinkAnd then, maybe, the grand masters of this, Deathspell Omega.
As far as my horizons lead - your thoughts will be more deep
Hope inside is torturing me - keeps painfully alive
A light inside, a knowledge deep, that shines so bright!
Deathspell Omega "Chaining the Katechon"
That's a 22-minute song, and it does not fade in.
The task to be achieved, human vocationHere, then, are some potential tenets of a chaotic black metal philosophical program:
Is to become intensely mortal
Not to shrink back
Before the voices
coming from the gallows tree
A work making increasing sense
By its lack of sense
In the history of times there is
But the truth of bones and dust.
1. Babel. Acceptance of chaos, instead of a futile struggle for order or serenity
2. The Codex. To exist in chaos is to seek complexity over simplicity
3. The Void. There is beauty in darkness
4. The Scythe. There are either no illusions, or all illusions, but either way, only death is real
Which all adds up, I think, to something that I basically understood in second grade, after all: grimly acknowledged free will. That is the philosophical core of metal, as an art form. That is the exact rebellion I was seeking. To choose Satan, and particularly to choose Satan without giving him any positive qualities, is to assert that the act of choosing is more important than the actual choice. To choose death is to assert that choosing is more important than living. To choose death symbolically is somewhat more powerful than choosing it literally, because you can choose it symbolically more than once, while gives you a chance to refine your symbolism.
Blut Aus Nord "The Choir of the Dead"
That is Blut Aus Nord's "The Choir of the Dead", from an album actually called The Work Which Transforms God. What does it say? I dunno. But what does it mean? "Hail Satan" is "Think for yourself" plus noise.
Thank you, and see you in Hell.
[The whole playlist that I was playing from is on Spotify here: Triangulations of the Abyss.]
Thanks to the Program Committee and the audience for indulging this whim, and particularly to Eric Weisbard for backing up his early-morning scheduling of this racket by showing up to moderate the session himself.
¶ Every Noise on a Wall · 17 April 2015 listen/tech
One of my Spotify co-workers walked into a cafe and music venue called Grenswerk in Venlo, Netherlands, and discovered that they have expanded Every Noise at Once, physically, to cover an entire wall. I am basically dumbfounded.





Photos by Asa Lidén, wall by Daan de Haan.
Note that they didn't just print the thing, they actually rotated it 90 degrees, since the wall is wider than it is tall, unlike the web page.
My daughter asked if you can touch the words on the wall to make the music play. That would be amazing. But this is already amazing as it is.
Photos by Asa Lidén, wall by Daan de Haan.
Note that they didn't just print the thing, they actually rotated it 90 degrees, since the wall is wider than it is tall, unlike the web page.
My daughter asked if you can touch the words on the wall to make the music play. That would be amazing. But this is already amazing as it is.