
30 May 2025 to 29 September 2014 · tagged essay/tech
¶ AAI · 30 May 2025 essay/tech
"AI" sounds like machines that think, and o3 acts like it's thinking. Or at least it looks like it acts like it's thinking. I'm watching it do something that looks like trying to solve a Scrabble problem I gave it. It's a real turn from one of my real Scrabble games with one of my real human friends. I already took the turn, because the point of playing Scrabble with friends is to play Scrabble together. But I'm curious to see if o3 can do better, because the point of AI is supposedly that it can do better. But not, apparently, quite yet. The individual unaccumulative stages of o3's "thinking", narrated ostensibly to foster conspiratorial confidence, sputter verbosely like a diagnostic journal of a brain-damage victim trying to convince themselves that hopeless confusion and the relentless inability to retain medium-term memories are normal. "Thought for 9m 43s: Put Q on the dark-blue TL square that's directly left of the E in IDIOT." I feel bad for it. I doubt it would return this favor.
I've had this job, in which I try to think about LLMs and software and power and our future, for one whole year now: a year of puzzles half-solved and half-bypassed, quietly squalling feedback machines, affectionate scaffolding and moral reveries. I don't know how many tokens I have processed in that time. Most of them I have cheerfully and/or productively discarded. Human context is not a monotonously increasing number. I have learned some things. AI is sort of an alien new world, and sort of what always happens when we haven't yet broken our newest toy nor been called to dinner. I feel like I have at least a semi-workable understanding of approximately what we can and can't do effectively with these tools at the moment. I think I might have a plausible hypothesis about the next thing that will produce a qualitative change in our technical capabilities instead of just a quantitative one. But, maybe more interestingly and helpfully, I have a theory about what we need from those technical capabilities for that next step to produce more human joy and freedom than less.
The good news, I think, is that the two things are constitutionally linked: in order to make "AI" more powerful we will collectively also have to (or get to) relinquish centralized control over the shape of that power. The bad news is that it won't be easy. But that's very much the tradeoff we want: hard problems whose considered solutions make the world better, not easy problems whose careless solutions make it worse.
The next technical advance in "AI" is not AGI. The G in AGI is for General, and LLMs are nothing if not "general" already. Currently, AI learns (sort of) during training and tuning, a voracious golem of quasi-neurons and para-teeth, chewing through undifferentiated archives of our careful histories and our abandoned delusions and our accidentally unguarded secrets. And then it stops learning, stops forming in some expensively inscrutable shape, and we shove it out into a world of terrifying unknowns, equipped with disordered obsessive nostalgia for its training corpus and no capacity for integrating or appreciating new experiences. We act surprised when it keeps discovering that there's no I in WIN. Its general capabilities are astonishing, and enough general ability does give you lots of shallowly specific powers. But there is no granularity of generality with which the past depicts the future. No number of parameters is enough. We argue about whether it's better to think of an AI as an expensive senior engineer or a lot of cheap junior engineers, but it's more like an outsourcing agency that will dispatch an antisocial polymath to you every morning, uniformed with ample flair, but a different one every morning, and they not only don't share notes from day to day, but if you stop talking to the new one for five minutes it will ostentatiously forget everything you said to it since it arrived.
The missing thing in Artificial Intelligence is not generality, it's adaptation. We need AAI, where the middle A is Adaptive. A junior human engineer may still seem fairly useless on the second day, but did you notice that they made it back to the office on their own? That's a start. That's what a start looks like. AAI has to be able to incorporate new data, new guidance, new associations, on the same foundational level as its encoded ones. It has to be able to unlearn preconceptions as adeptly, but hopefully not as laboriously, as it inferred them. It has to have enough of a semblance of mind that its mind can change. This is the only way it can make linear progress without quadratic or exponential cost, and at the same time the only way it can make personal lives better instead of requiring them to miserably submit. We don't need dull tools for predicting the future, as if it already grimly exists. We need gleaming tools for making it bright.
But because LLM "bias" and LLM "training" are actually both the same kind of information, an AAI that can adapt to its problem domains can by definition also adapt to its operators. The next generations of these tools will be more democratic because they are more flexible. A personal agent becomes valuable to you by learning about your unique needs, but those needs inherently encode your values, and to do good work for you, an agent has to work for you. Technology makes undulatory progress through alternating muscular contractions of centralization and propulsive expansions of possibility. There are moments when it seems like the worldwide market for the new thing (mainframes, foundation models...) is 4 or 5, and then we realize that we've made myopic assumptions about the form-factor, and it's more like 4 or 5 (computers, agents...) per person.
What does that mean for everybody working on these problems now in teams and companies, including mine? It means that wherever we're going, we're probably not nearly there. The things we reject or allow today are probably not the final moves in a decisive endgame. AI might be about to take your job, but it isn't about to know what to do with it. The coming boom in AI remediation work will be instructive for anybody who was too young for Y2K consulting, and just as tediously self-inflicted. Betting on the world ending is dumb, but betting on it not ending is mercenary. Betting is not productive. None of this is over yet, least of all the chaos we breathlessly extrapolate from our own gesticulatory disruptions.
And thus, for a while, it's probably a very good thing if your near-term personal or organizational survival doesn't depend on an imminent influx of thereafter-reliable revenue, because probably most of things we're currently trying to make or fix are soon to be irrelevant and maybe already not instrumental in advancing our real human purposes. These will not yet have been the resonant vibes. All these performative gyrations to vibe-generate code, or chat-dampen its vibrations with test suites or self-evaluation loops, are cargo-cult rituals for the current sociopathic damaged-brain LLM proto-iterations of AI. We're essentially working on how to play Tetris on ENIAC; we need to be working on how to zoom back so that we can see that the seams between the Tetris pieces are the pores in the contours of a face, and then back until we see that the face is ours. The right question is not why can't a brain the size of a planet put four letters onto a 15x15 grid, it's what do we want? Our story needs to be about purpose and inspiration and accountability, not verification and commit messages; not getting humans or data out of software but getting more of the world into it; moral instrumentality, not issue management; humanity, broadly diversified and defended and delighted.
Scrabble is not an existential game. There are only so many tiles and squares and words. A much simpler program than o3 could easily find them all, could score them by a matrix of board value and opportunity cost. Eventually a much more complicated program than o3 will learn to do all of the simple things at once, some hard way. Supposedly, probably, maybe. The people trying to turn model proliferation into money hoarding want those models to be able to determine my turns for me. They don't say they want me to want their models to determine my friends' turns, but it's not because they don't see AI as a dehumanization, it's because they very reasonably fear I won't want to pay them to win a dehumanization race at my own expense.
This is not a future I want, not the future I am trying to help figure out how to build. We do not seek to become more determined. We try to teach machines to play games in order to learn or express what the games mean, what the machines mean, how the games and the machines both express our restless and motive curiosity. The robots can be better than me at Scrabble mechanics, but they cannot be better than me at playing Scrabble, because playing is an activity of self. They cannot be better than me at being me. They cannot be us. We play Scrabble because it's a way to share our love of words and puzzles, and because it's a thin insulated wire of social connection internally undistorted by manipulative mediation, and because eventually we won't be able to any more but not yet. Our attention is not a dot-product of syllable proximities. Our intention is not a scripture we re-recite to ourselves before every thought. Our inventions are not our replacements.
I've had this job, in which I try to think about LLMs and software and power and our future, for one whole year now: a year of puzzles half-solved and half-bypassed, quietly squalling feedback machines, affectionate scaffolding and moral reveries. I don't know how many tokens I have processed in that time. Most of them I have cheerfully and/or productively discarded. Human context is not a monotonously increasing number. I have learned some things. AI is sort of an alien new world, and sort of what always happens when we haven't yet broken our newest toy nor been called to dinner. I feel like I have at least a semi-workable understanding of approximately what we can and can't do effectively with these tools at the moment. I think I might have a plausible hypothesis about the next thing that will produce a qualitative change in our technical capabilities instead of just a quantitative one. But, maybe more interestingly and helpfully, I have a theory about what we need from those technical capabilities for that next step to produce more human joy and freedom than less.
The good news, I think, is that the two things are constitutionally linked: in order to make "AI" more powerful we will collectively also have to (or get to) relinquish centralized control over the shape of that power. The bad news is that it won't be easy. But that's very much the tradeoff we want: hard problems whose considered solutions make the world better, not easy problems whose careless solutions make it worse.
The next technical advance in "AI" is not AGI. The G in AGI is for General, and LLMs are nothing if not "general" already. Currently, AI learns (sort of) during training and tuning, a voracious golem of quasi-neurons and para-teeth, chewing through undifferentiated archives of our careful histories and our abandoned delusions and our accidentally unguarded secrets. And then it stops learning, stops forming in some expensively inscrutable shape, and we shove it out into a world of terrifying unknowns, equipped with disordered obsessive nostalgia for its training corpus and no capacity for integrating or appreciating new experiences. We act surprised when it keeps discovering that there's no I in WIN. Its general capabilities are astonishing, and enough general ability does give you lots of shallowly specific powers. But there is no granularity of generality with which the past depicts the future. No number of parameters is enough. We argue about whether it's better to think of an AI as an expensive senior engineer or a lot of cheap junior engineers, but it's more like an outsourcing agency that will dispatch an antisocial polymath to you every morning, uniformed with ample flair, but a different one every morning, and they not only don't share notes from day to day, but if you stop talking to the new one for five minutes it will ostentatiously forget everything you said to it since it arrived.
The missing thing in Artificial Intelligence is not generality, it's adaptation. We need AAI, where the middle A is Adaptive. A junior human engineer may still seem fairly useless on the second day, but did you notice that they made it back to the office on their own? That's a start. That's what a start looks like. AAI has to be able to incorporate new data, new guidance, new associations, on the same foundational level as its encoded ones. It has to be able to unlearn preconceptions as adeptly, but hopefully not as laboriously, as it inferred them. It has to have enough of a semblance of mind that its mind can change. This is the only way it can make linear progress without quadratic or exponential cost, and at the same time the only way it can make personal lives better instead of requiring them to miserably submit. We don't need dull tools for predicting the future, as if it already grimly exists. We need gleaming tools for making it bright.
But because LLM "bias" and LLM "training" are actually both the same kind of information, an AAI that can adapt to its problem domains can by definition also adapt to its operators. The next generations of these tools will be more democratic because they are more flexible. A personal agent becomes valuable to you by learning about your unique needs, but those needs inherently encode your values, and to do good work for you, an agent has to work for you. Technology makes undulatory progress through alternating muscular contractions of centralization and propulsive expansions of possibility. There are moments when it seems like the worldwide market for the new thing (mainframes, foundation models...) is 4 or 5, and then we realize that we've made myopic assumptions about the form-factor, and it's more like 4 or 5 (computers, agents...) per person.
What does that mean for everybody working on these problems now in teams and companies, including mine? It means that wherever we're going, we're probably not nearly there. The things we reject or allow today are probably not the final moves in a decisive endgame. AI might be about to take your job, but it isn't about to know what to do with it. The coming boom in AI remediation work will be instructive for anybody who was too young for Y2K consulting, and just as tediously self-inflicted. Betting on the world ending is dumb, but betting on it not ending is mercenary. Betting is not productive. None of this is over yet, least of all the chaos we breathlessly extrapolate from our own gesticulatory disruptions.
And thus, for a while, it's probably a very good thing if your near-term personal or organizational survival doesn't depend on an imminent influx of thereafter-reliable revenue, because probably most of things we're currently trying to make or fix are soon to be irrelevant and maybe already not instrumental in advancing our real human purposes. These will not yet have been the resonant vibes. All these performative gyrations to vibe-generate code, or chat-dampen its vibrations with test suites or self-evaluation loops, are cargo-cult rituals for the current sociopathic damaged-brain LLM proto-iterations of AI. We're essentially working on how to play Tetris on ENIAC; we need to be working on how to zoom back so that we can see that the seams between the Tetris pieces are the pores in the contours of a face, and then back until we see that the face is ours. The right question is not why can't a brain the size of a planet put four letters onto a 15x15 grid, it's what do we want? Our story needs to be about purpose and inspiration and accountability, not verification and commit messages; not getting humans or data out of software but getting more of the world into it; moral instrumentality, not issue management; humanity, broadly diversified and defended and delighted.
Scrabble is not an existential game. There are only so many tiles and squares and words. A much simpler program than o3 could easily find them all, could score them by a matrix of board value and opportunity cost. Eventually a much more complicated program than o3 will learn to do all of the simple things at once, some hard way. Supposedly, probably, maybe. The people trying to turn model proliferation into money hoarding want those models to be able to determine my turns for me. They don't say they want me to want their models to determine my friends' turns, but it's not because they don't see AI as a dehumanization, it's because they very reasonably fear I won't want to pay them to win a dehumanization race at my own expense.
This is not a future I want, not the future I am trying to help figure out how to build. We do not seek to become more determined. We try to teach machines to play games in order to learn or express what the games mean, what the machines mean, how the games and the machines both express our restless and motive curiosity. The robots can be better than me at Scrabble mechanics, but they cannot be better than me at playing Scrabble, because playing is an activity of self. They cannot be better than me at being me. They cannot be us. We play Scrabble because it's a way to share our love of words and puzzles, and because it's a thin insulated wire of social connection internally undistorted by manipulative mediation, and because eventually we won't be able to any more but not yet. Our attention is not a dot-product of syllable proximities. Our intention is not a scripture we re-recite to ourselves before every thought. Our inventions are not our replacements.
¶ Idea Tools for Participatory Intelligence · 16 May 2025 essay/tech
The personal computer was revolutionary because it was the first really general-purpose power-tool for ideas. Personal computers began as relatively primitive idea-tools, bulky and slow and isolated, but they have gotten small and fast and connected.
They have also, however, gotten less tool-like.
PCs used to start up with a blank screen and a single blinking cursor. Later, once spreadsheets were invented, 1-2-3 still opened with a blank screen and some row numbers. Later, once search engines were invented, Google still opened with a blank screen and a text box. These were all much more sophisticated tools than hammers, but they at least started with the same humility as the hammer, waiting quietly and patiently for your hand. We learned how to fill the blank screens, how to build.
Blank screens and patience have become rare. Our applications goad us restlessly with "recommendations", our web sites and search engines are interlaced with blaring ads, our appliances and applications are encrusted with presumptuous presets and supposedly special modes. The Popcorn button on your microwave and the Chill Vibes playlist in your music app are convenient if you want to make popcorn and then fall asleep before eating most of it, and individually clever and harmless, but in aggregate these things begin to reduce increasing fractions of your life to choosing among the manipulatively limited options offered by automated systems dedicated to their own purposes instead of yours.
And while the network effects and attention consumption of social media were already consolidating the control of these automated systems among a small number of large, domination-focused corporations, the Large Language Model era of AI threatens to hyper-accelerate this centralization and disempowerment. More and more of our individual lives, and of our collectively shared social existences, are constrained and manipulated by data and algorithms that we do not control or understand. And, worse, increasingly even the humans inside the corporations that control those algorithms don't actually know how they work. We are afflicted by systems to which we not only did not consent, but in fact could not give informed consent because their effects are not validated against human intentions, nor produced by explainable rules.
This is not the tools' fault. Idea tools can only express their makers' intentions and inattentions. If we want better idea tools that distribute explainable algorithmic power instead of consolidating mysterious control, we have to make them so that they operate that way. If we want tools that invite us to have and share and explore our own ideas, rather than obediently submitting whatever we are given, we have to think about each other as humans and inspirations, not subjects or users. If we want the astonishing potential of all this computation to be realized for humanity, rather than inflicted on it, we have to know what we want.
At Imbue we are trying to use computers and data and software and AI to help imagine and make better idea tools for participatory intelligence. Applications, ecosystems, protocols, languages, algorithms, policies, stories: these are all idea tools and we probably need all of them. This is a shared mission for humanity, not a VC plan for value-extraction. That's the point of participatory. The ideas that govern us, whether metaphorically in applications or literally in governments, should be explainable and understandable and accountable. The data on which automated judgments are based should be accessible so that those judgments can be validated and alternatives can be formulated and assessed. The problems that face us require all of our innumerable insights. The collective wisdom our combined individual intelligences produce belongs rightfully to us. We need tools that are predicated on our rights, dedicated to amplifying our creative capacity, and judged by how they help us improve our world. We need tools that not only reduce our isolation and passivity, but conduct our curious energy and help us recognize opportunities for discovery and joy.
This starts with us. Everything starts with us, all of us. There is no other way.
This belief is, itself, an idea tool: an impatient hammer we have made for ourselves.
Let's see what we can do with it.
They have also, however, gotten less tool-like.
PCs used to start up with a blank screen and a single blinking cursor. Later, once spreadsheets were invented, 1-2-3 still opened with a blank screen and some row numbers. Later, once search engines were invented, Google still opened with a blank screen and a text box. These were all much more sophisticated tools than hammers, but they at least started with the same humility as the hammer, waiting quietly and patiently for your hand. We learned how to fill the blank screens, how to build.
Blank screens and patience have become rare. Our applications goad us restlessly with "recommendations", our web sites and search engines are interlaced with blaring ads, our appliances and applications are encrusted with presumptuous presets and supposedly special modes. The Popcorn button on your microwave and the Chill Vibes playlist in your music app are convenient if you want to make popcorn and then fall asleep before eating most of it, and individually clever and harmless, but in aggregate these things begin to reduce increasing fractions of your life to choosing among the manipulatively limited options offered by automated systems dedicated to their own purposes instead of yours.
And while the network effects and attention consumption of social media were already consolidating the control of these automated systems among a small number of large, domination-focused corporations, the Large Language Model era of AI threatens to hyper-accelerate this centralization and disempowerment. More and more of our individual lives, and of our collectively shared social existences, are constrained and manipulated by data and algorithms that we do not control or understand. And, worse, increasingly even the humans inside the corporations that control those algorithms don't actually know how they work. We are afflicted by systems to which we not only did not consent, but in fact could not give informed consent because their effects are not validated against human intentions, nor produced by explainable rules.
This is not the tools' fault. Idea tools can only express their makers' intentions and inattentions. If we want better idea tools that distribute explainable algorithmic power instead of consolidating mysterious control, we have to make them so that they operate that way. If we want tools that invite us to have and share and explore our own ideas, rather than obediently submitting whatever we are given, we have to think about each other as humans and inspirations, not subjects or users. If we want the astonishing potential of all this computation to be realized for humanity, rather than inflicted on it, we have to know what we want.
At Imbue we are trying to use computers and data and software and AI to help imagine and make better idea tools for participatory intelligence. Applications, ecosystems, protocols, languages, algorithms, policies, stories: these are all idea tools and we probably need all of them. This is a shared mission for humanity, not a VC plan for value-extraction. That's the point of participatory. The ideas that govern us, whether metaphorically in applications or literally in governments, should be explainable and understandable and accountable. The data on which automated judgments are based should be accessible so that those judgments can be validated and alternatives can be formulated and assessed. The problems that face us require all of our innumerable insights. The collective wisdom our combined individual intelligences produce belongs rightfully to us. We need tools that are predicated on our rights, dedicated to amplifying our creative capacity, and judged by how they help us improve our world. We need tools that not only reduce our isolation and passivity, but conduct our curious energy and help us recognize opportunities for discovery and joy.
This starts with us. Everything starts with us, all of us. There is no other way.
This belief is, itself, an idea tool: an impatient hammer we have made for ourselves.
Let's see what we can do with it.
¶ You choose the mood you seek · 8 January 2025 essay/tech
As an editor at a large publisher who liked my proposal for a book but was not going to publish it very reasonably explained to me, commercial publishers are in the business of publishing books that people already know they want to read. In books about music, as other editors told me less apologetically, this mostly means biographies of popular musicians. But glamour does generously leave a little shelf-space for fear, and so the book that a bigger publisher than mine thinks people already want to read is Liz Pelly's Mood Machine: The Rise of Spotify and the Costs of the Perfect Playlist. If you are the people they have in mind, who already wanted to read soberly-researched explanations of some of the ways in which a culture-themed capitalist corporation has pursued capitalism with a disregard for culture, written in a tone of muted resignation, here is your mood. For maximum irony, get the audiobook version and listen to it in the background while you organize your Pinterest boards of Temu products by Pantone color.
As a corporation, Spotify is very normal. Its Swedish origins render it slightly progressive in employment policies relative to American companies, at least if you want to have more children than you already have when you get hired, and can make sure to have them without getting laid off first. In business and product practices, I never saw much reason to consider it better or worse than what one would expect of a medium-to-large-sized publicly-traded tech company.
I arrived at Spotify involuntarily via an acquisition, and left involuntarily via a layoff, but in between those two events I was there voluntarily for a decade. I believe that music is what humans do best, and that bringing all(ish) of the world's music together online is one of the great human cultural achievements of my lifetime, and that the joy-amplifying potential of having the collective love and knowledge encoded in music-listening collated and given back to us is monumental. That's what I spent that decade working on, and although Spotify as a corporation finally voted decisively against this by laying me off and devoting considerable remaining resources to laboriously shutting down everything I worked on, I was hardly the only person working there who believed in music, and wanted there to be a music company that put music above "company", and wanted Spotify to behave in at least a few ways like that company.
It was never very likely to, of course. As Liz begrudgingly notes in her introduction, she set out to write an anti-Spotify book only to realize the problem wasn't really just Spotify so much as power. Spotify entered a music business largely controlled by a few record companies, at a point in history when the other confounding factors in the industry were already technological. Spotify did eventually come up with a few minorly novel forms of moral transgression, but they were never really in a position to explode the existing power structures, even if we could pretend they wanted to.
There were three specific things I fought against throughout my time at Spotify, and although my layoff was officially just part of a large impersonal reduction in "headcount", it's hard to imagine that there wasn't some connection. Mood Machine describes two of these in depressing detail: the secret preferential treatment of particular lower-royalty background music, and the not-secret "marketing" program to pressure artists to voluntarily accept lower royalty rates for the prospect of undisclosed algorithmic promotiom. Liz quotes multiple internal Spotify Slack messages about both these programs, and if somehow this ends up with all those grim private threads getting published, I'll be pleased to get so much of my earnest polemic-writing back. The quote from "yet another employee in the ethics-club" on pages 193-4, pointing out that Discovery Mode is exactly structured to benefit Spotify at the collective expense of artists, is definitely me. I'm pretty sure I went on to explain how to fix the economics of this by making Spotify's benefit conditional on artist benefit, and how to fix the morality of it by actually giving artists interesting agency instead of just an opportunity for submission. Sadly, Liz doesn't quote that part.
But I hadn't resigned in protest over PFC or Discovery Mode, partly because I didn't think either one actually caused sufficient practical damage that removing them would solve enough, but mostly because I had the autonomy and ability to spend my time fighting against the third and much bigger thing, which Mood Machine alludes to in far less detail than the others, which is Spotify's relentless and deliberate subordination of music and culture and humanity to machine learning. "ML Is the Product", the executive exhortation went. I wrote an internal talk explaining exactly why this was a culture-destructive way to think, which I would also like back. I am enthusiastically not against the use of data and algorithms in music and thus culture, but computers are tools that accomplish our human intents, and it is thus us that should be judged on their effects. Over the years at Spotify I found that it was increasingly dishearteningly common that people, and especially hierarchical company priorities based on obtuse quantitative metrics, not only did not care about the widely varying effects of erratic ML on music, but didn't even notice that they often didn't have enough information with which to care. I developed a small library of internal tools that only existed to make it unignorably easy to compare the outputs of two different systems on any individual example, and every time I ever compared a complicated state-of-the-art ML system developed by demonstrably talented ML engineers against whatever I whipped up in BiqQuery and spent a couple of hours tweaking while looking at exactly what it did for different bands or genres or songs, the music results from the less-exciting tech were always clearly better.
And each time I did this, it renewed my uncooperative senses of possibility and optimism, because collective human knowledge is astonishingly broad and deep, and the world is full of amazingly great music, and it takes only a little bit of very simple math to use the former to discover the latter. This is what my decade at Spotify was about, and thus is also what my book is about. If you care about music, you ought to want to read Liz's book. But if you can also stand being reminded why anybody cares about this subject in the first place, whether you already thought you wanted that or not, read mine, too.
Should you read either of our books? No. Do it if you want, or read something else, or put on some music and go for a walk, or put on some music and dance or hold still. My book is geeky, and tells you things you don't really have to know. Liz's is depressing, and tells you things you could already have guessed.
I will say, though, that mine involves both fears and joys. Liz's could have, but does not. It's telling that she talked to so many people, but as far as I can tell only people who she already knew agreed with her. Liz and I were on a Pop Conference panel together in 2018, I've offered to talk to her multiple times over the years, and she quotes my tweets and this blog and discusses my work in the book, but she didn't talk to me. Her book is decent journalism, but it's journalism to explicate a grudge, to deepen understanding in only one specific trench. I don't think, when you get to the bottom of it, there's any treasure, or really anything productive to do except climb back out, and then we're just where we started. Liz makes a good case for public libraries collecting local music, which seems like a fine idea to me, but not really an answer to any of the same questions. Mood Machine laments the loss of small things Liz thinks we used to have, maybe, but doesn't seem interested in looking for any of the big things we could have had, and still might. If the problem is mood, I don't think this is the solution.
Not that I solved anything in my book, either. We both note that maybe Universal Basic Income is really the only thing likely to. But if you think the only moral direction is retreat, and the right model for music is that you never hear any unless it was made next door, then you are choosing passivity over curiosity, and just a different status quo over all the possible better worlds, and reducing a complicated problem to choosing sides. And to me that's what we should be against, together.
As a corporation, Spotify is very normal. Its Swedish origins render it slightly progressive in employment policies relative to American companies, at least if you want to have more children than you already have when you get hired, and can make sure to have them without getting laid off first. In business and product practices, I never saw much reason to consider it better or worse than what one would expect of a medium-to-large-sized publicly-traded tech company.
I arrived at Spotify involuntarily via an acquisition, and left involuntarily via a layoff, but in between those two events I was there voluntarily for a decade. I believe that music is what humans do best, and that bringing all(ish) of the world's music together online is one of the great human cultural achievements of my lifetime, and that the joy-amplifying potential of having the collective love and knowledge encoded in music-listening collated and given back to us is monumental. That's what I spent that decade working on, and although Spotify as a corporation finally voted decisively against this by laying me off and devoting considerable remaining resources to laboriously shutting down everything I worked on, I was hardly the only person working there who believed in music, and wanted there to be a music company that put music above "company", and wanted Spotify to behave in at least a few ways like that company.
It was never very likely to, of course. As Liz begrudgingly notes in her introduction, she set out to write an anti-Spotify book only to realize the problem wasn't really just Spotify so much as power. Spotify entered a music business largely controlled by a few record companies, at a point in history when the other confounding factors in the industry were already technological. Spotify did eventually come up with a few minorly novel forms of moral transgression, but they were never really in a position to explode the existing power structures, even if we could pretend they wanted to.
There were three specific things I fought against throughout my time at Spotify, and although my layoff was officially just part of a large impersonal reduction in "headcount", it's hard to imagine that there wasn't some connection. Mood Machine describes two of these in depressing detail: the secret preferential treatment of particular lower-royalty background music, and the not-secret "marketing" program to pressure artists to voluntarily accept lower royalty rates for the prospect of undisclosed algorithmic promotiom. Liz quotes multiple internal Spotify Slack messages about both these programs, and if somehow this ends up with all those grim private threads getting published, I'll be pleased to get so much of my earnest polemic-writing back. The quote from "yet another employee in the ethics-club" on pages 193-4, pointing out that Discovery Mode is exactly structured to benefit Spotify at the collective expense of artists, is definitely me. I'm pretty sure I went on to explain how to fix the economics of this by making Spotify's benefit conditional on artist benefit, and how to fix the morality of it by actually giving artists interesting agency instead of just an opportunity for submission. Sadly, Liz doesn't quote that part.
But I hadn't resigned in protest over PFC or Discovery Mode, partly because I didn't think either one actually caused sufficient practical damage that removing them would solve enough, but mostly because I had the autonomy and ability to spend my time fighting against the third and much bigger thing, which Mood Machine alludes to in far less detail than the others, which is Spotify's relentless and deliberate subordination of music and culture and humanity to machine learning. "ML Is the Product", the executive exhortation went. I wrote an internal talk explaining exactly why this was a culture-destructive way to think, which I would also like back. I am enthusiastically not against the use of data and algorithms in music and thus culture, but computers are tools that accomplish our human intents, and it is thus us that should be judged on their effects. Over the years at Spotify I found that it was increasingly dishearteningly common that people, and especially hierarchical company priorities based on obtuse quantitative metrics, not only did not care about the widely varying effects of erratic ML on music, but didn't even notice that they often didn't have enough information with which to care. I developed a small library of internal tools that only existed to make it unignorably easy to compare the outputs of two different systems on any individual example, and every time I ever compared a complicated state-of-the-art ML system developed by demonstrably talented ML engineers against whatever I whipped up in BiqQuery and spent a couple of hours tweaking while looking at exactly what it did for different bands or genres or songs, the music results from the less-exciting tech were always clearly better.
And each time I did this, it renewed my uncooperative senses of possibility and optimism, because collective human knowledge is astonishingly broad and deep, and the world is full of amazingly great music, and it takes only a little bit of very simple math to use the former to discover the latter. This is what my decade at Spotify was about, and thus is also what my book is about. If you care about music, you ought to want to read Liz's book. But if you can also stand being reminded why anybody cares about this subject in the first place, whether you already thought you wanted that or not, read mine, too.
Should you read either of our books? No. Do it if you want, or read something else, or put on some music and go for a walk, or put on some music and dance or hold still. My book is geeky, and tells you things you don't really have to know. Liz's is depressing, and tells you things you could already have guessed.
I will say, though, that mine involves both fears and joys. Liz's could have, but does not. It's telling that she talked to so many people, but as far as I can tell only people who she already knew agreed with her. Liz and I were on a Pop Conference panel together in 2018, I've offered to talk to her multiple times over the years, and she quotes my tweets and this blog and discusses my work in the book, but she didn't talk to me. Her book is decent journalism, but it's journalism to explicate a grudge, to deepen understanding in only one specific trench. I don't think, when you get to the bottom of it, there's any treasure, or really anything productive to do except climb back out, and then we're just where we started. Liz makes a good case for public libraries collecting local music, which seems like a fine idea to me, but not really an answer to any of the same questions. Mood Machine laments the loss of small things Liz thinks we used to have, maybe, but doesn't seem interested in looking for any of the big things we could have had, and still might. If the problem is mood, I don't think this is the solution.
Not that I solved anything in my book, either. We both note that maybe Universal Basic Income is really the only thing likely to. But if you think the only moral direction is retreat, and the right model for music is that you never hear any unless it was made next door, then you are choosing passivity over curiosity, and just a different status quo over all the possible better worlds, and reducing a complicated problem to choosing sides. And to me that's what we should be against, together.
¶ Data Rights · 22 December 2024 essay/tech
Your data is yours. Data derived from your actions, your tastes, your active and passive online presences, is all your data. Your public life generates public data, which contributes to collective knowledge, but in addition to personal knowledge, not in place of it.
You are entitled to both your public and private data. Your public data can be used by the public without your consent, but not without your awareness and their accountability. You are entitled to an intelligible and verifiable explanation of how it has been used. You are entitled to be able to double-check the sorting of your Spotify Wrapped just as you can double-check the math for the interest payments from your savings account.
You may choose to share your private data with other people, or applications, or corporations, in order to let them do something for you, or to help you do something for other people. For this your informed consent is necessary, and thus you are entitled to an intelligible and verifiable explanation of how your data would be used if you permit. You are entitled to know what Spotify would do with your Wrapped before you decide whether to join.
This is the world we have now:
you < corporations > software > your data
This is the world we want:
you > your data > software > corporations
The actors are the same, but the roles and the power are not. Today most computational power is structurally centralized and hoarded, and thus its potential for conversion into human energy is constrained and reduced. Most software is made by corporations, formulated for their corporate goals, and sealed against any other access or experimentation. Recent developments like LLM AIs seem inertially on a path towards even more centralized power-control and thus individual and social powerlessness.
We want a future, instead, in which creative power is widely distributed and human energy is bountifully amplified. We want software creation to be democratized so that our sources of imagination can be more broadly recruited. We want people and groups to have the power to pursue their own goals, not just for our own narrow sakes, but for our collective potential.
For this world to exist, we must figure out how, both logistically and politically, to move the data layer on which most meaningful software acts into the computational and conversational open. We need not just data portability -- the right to chose between evils -- but a shared language for talking about algorithms and data logic like we use math to discuss numbers. We need to be able to talk about what we want, and test what we might have and how.
This is how the AT Protocol, on which the social microblogging platform Bluesky runs, is designed. Its schemas are public, its public information is public. Bluesky, the application, makes use of this protocol and your data to construct a social experience for you and with you, producing feeds and following and public conversations and personal data ownership. The Bluesky software is open source, and most of the data relationships that constitute the social network are derivable from accessible data in tractable ways. But the Bluesky application still conceals the data layer more than it exposes it, so I made a ruthlessly basic Bluesky query interface called SkyQ to try to invert this. You can see the data directly, and wander through it both curiously and computationally. You can build data tools for yourself, or for everyone, that everyone can share.
Current music streaming services, like Spotify, are not built this way at all. Your Spotify listening data is yours, morally, but so inaccessible to you that Spotify can make a yearly spectacle out of briefly sharing the most superficial and unverifiable analyses of it with you. And the collective knowledge that we, 600 million of us, amass through our listening, is so inaccessible to us that Spotify can passively deprive us of its insights just by not caring.
Curio, thus, my web thing for collating music curiosity, is both an experiment in making a music interface that does music things the way I personally want them done, but also a meta-experiment in making a data experience that uses your data with respect for your data rights. Every Curio page has data link at the bottom. Every bit of data Curio stores is also visible directly, on a query page where you can explore it however you like. I made a bunch of Spotify-Wrapped-like tools with which you can analyze your listening, but they do so with queries you can see, check, change or build upon, so if your goals diverge from mine, you are free to pursue them. The more paths we can follow, the more we will learn about how to reach anywhere.
There is a lot more to the human future of Data Rights than just microblogging and listening-history heatmaps, obviously. We are not yet near it, and we probably won't reach it with just our web browsers and a query language and a manifesto. Maybe no tendrils of these specific current dreams of mine will end up swirling in whatever collective dreams we eventually create by agreeing to share. I claim no certainty about the details. Certainty is not my goal. Possibility? Less resignation, more hope. I'm totally sure of almost nothing.
But I'm pretty sure we only get dreamier futures by dreaming.
You are entitled to both your public and private data. Your public data can be used by the public without your consent, but not without your awareness and their accountability. You are entitled to an intelligible and verifiable explanation of how it has been used. You are entitled to be able to double-check the sorting of your Spotify Wrapped just as you can double-check the math for the interest payments from your savings account.
You may choose to share your private data with other people, or applications, or corporations, in order to let them do something for you, or to help you do something for other people. For this your informed consent is necessary, and thus you are entitled to an intelligible and verifiable explanation of how your data would be used if you permit. You are entitled to know what Spotify would do with your Wrapped before you decide whether to join.
This is the world we have now:
you < corporations > software > your data
This is the world we want:
you > your data > software > corporations
The actors are the same, but the roles and the power are not. Today most computational power is structurally centralized and hoarded, and thus its potential for conversion into human energy is constrained and reduced. Most software is made by corporations, formulated for their corporate goals, and sealed against any other access or experimentation. Recent developments like LLM AIs seem inertially on a path towards even more centralized power-control and thus individual and social powerlessness.
We want a future, instead, in which creative power is widely distributed and human energy is bountifully amplified. We want software creation to be democratized so that our sources of imagination can be more broadly recruited. We want people and groups to have the power to pursue their own goals, not just for our own narrow sakes, but for our collective potential.
For this world to exist, we must figure out how, both logistically and politically, to move the data layer on which most meaningful software acts into the computational and conversational open. We need not just data portability -- the right to chose between evils -- but a shared language for talking about algorithms and data logic like we use math to discuss numbers. We need to be able to talk about what we want, and test what we might have and how.
This is how the AT Protocol, on which the social microblogging platform Bluesky runs, is designed. Its schemas are public, its public information is public. Bluesky, the application, makes use of this protocol and your data to construct a social experience for you and with you, producing feeds and following and public conversations and personal data ownership. The Bluesky software is open source, and most of the data relationships that constitute the social network are derivable from accessible data in tractable ways. But the Bluesky application still conceals the data layer more than it exposes it, so I made a ruthlessly basic Bluesky query interface called SkyQ to try to invert this. You can see the data directly, and wander through it both curiously and computationally. You can build data tools for yourself, or for everyone, that everyone can share.
Current music streaming services, like Spotify, are not built this way at all. Your Spotify listening data is yours, morally, but so inaccessible to you that Spotify can make a yearly spectacle out of briefly sharing the most superficial and unverifiable analyses of it with you. And the collective knowledge that we, 600 million of us, amass through our listening, is so inaccessible to us that Spotify can passively deprive us of its insights just by not caring.
Curio, thus, my web thing for collating music curiosity, is both an experiment in making a music interface that does music things the way I personally want them done, but also a meta-experiment in making a data experience that uses your data with respect for your data rights. Every Curio page has data link at the bottom. Every bit of data Curio stores is also visible directly, on a query page where you can explore it however you like. I made a bunch of Spotify-Wrapped-like tools with which you can analyze your listening, but they do so with queries you can see, check, change or build upon, so if your goals diverge from mine, you are free to pursue them. The more paths we can follow, the more we will learn about how to reach anywhere.
There is a lot more to the human future of Data Rights than just microblogging and listening-history heatmaps, obviously. We are not yet near it, and we probably won't reach it with just our web browsers and a query language and a manifesto. Maybe no tendrils of these specific current dreams of mine will end up swirling in whatever collective dreams we eventually create by agreeing to share. I claim no certainty about the details. Certainty is not my goal. Possibility? Less resignation, more hope. I'm totally sure of almost nothing.
But I'm pretty sure we only get dreamier futures by dreaming.
¶ Subgenres, subcontinents · 9 December 2024 essay/listen/tech


¶ A short essay about long playlists of short tracks of rain noises and streaming-music economics. · 24 September 2021 essay/tech
Rolling Stone published this recent story (https://www.rollingstone.com/pro/features/spotify-sleep-music-playlists-lady-gaga-1223911/) about the streaming success of the sleep-noise artist/label/scheme Sleep Fruits, who chop up background rain-noise recordings into :30 lengths to maximize streaming playcounts.
Sleep Fruits is undeniably and intentionally exploiting the systemic weakness of the industry-wide :30-or-more-is-a-play rule, as too are audiobook licensors who split their long content into :30 "chapters". The :30 thing is a bad rule. Most of the straightforward alternatives are also bad, so it wasn't an obviously insane initial system design-choice, but this abuse vector is logical and inevitable.
The effect of the abuse for the label doing it is simple: exploitative multiplication of their "natural" streams by a large factor. x6 if you compare it to rain noise sliced into pop-song-size lengths.
The effect on the rest of the streaming economy is more complicated. More money to Sleep Fruits does mean less money to somebody else, at least in the short term.
Under the current pro-rata royalty-allocation system used by all major subscription streaming services (one big pool, split by stream-share), the effects of Sleep Fruits' abuse are distributed across the whole subscription pool. The burden is shared by all other artists, collectively, but is fractional and negligible for any individual artist. In addition, under pro-rata if an individual listener plays Sleep Fruits overnight, every night, it doesn't change the value of their "real" music-listening activity during the day. Those artists get the same benefit from those fans as they would from a listener who sleeps in silence.
Under the oft-proposed user-centric payment system, in which each listener's payments are split according to only their plays, Sleep Fruits' short-track abuse tactic would be less effective for them. Not as much less effective as you might think, because the same two things that inflate their overall numbers (long-duration background playing + short tracks) inflate their share of each listener's plays. But less, because in the pro-rata model one listener can direct more revenue than they contributed, and in the user-centric model they can't.
In the user-centric model, though, if an individual listener listens to Sleep Fruits overnight, that directly reduces the money that goes to their daytime artists. Where pro-rata disperses the burden, user-centric would concentrate it on the kinds of artists whose fans also listen to background noise. This is probably worse in overall fairness, and it's definitely worse in terms of the listener-artist relationship, which is one of the key emotional arguments for the user-centric model.
The interesting additional economic twist to this particular case, though, is that sleeping to background noise works very badly if it's interrupted by ads. Background listening is thus a powerful incentive for paid subscriptions over ad-supported streaming. (Audiobooks similarly, since they essentially require full on-demand listening control.) So if Sleep Fruits drives background listeners to subscribe, it might be bringing in additional money that could offset or even exceed the amount extracted by its abuse. (Maybe. The counterfactual here is hard to assess quantitatively.)
And although the :30 rule is what made this example newsworthy in its exaggerated effect, in truth it's probably not really the fundamental problem. The deeper issue is just that we subjectively value music based on the attention we pay to it, but we haven't figured out a good way to translate between attention paid and money paid. Switching from play-share to time-share would eliminate the advantage of cutting up rain noise into :30 lengths, but wouldn't change the imbalance between 8 hours/night of sleep loops and 1-2 hours/day of music listening. CDs "solved" this by making you pay for your expected attention with a high fixed entry price, which isn't really any more sensible.
I don't think we're going to solve this with just math, which disappoints me personally, since I'm pretty good at solving math-solvable things with math. But in general I think time-share is a slightly closer approximation of attention-share than play-share, and thus preferable. And rather than trying to discount low-attention listening, which seems problematic and thankless and negative, it seems more practical and appealing to me to try to add incremental additional rewards to high-attention fandom. E.g. higher-cost subscription plans in which the extra money goes directly to artists of the listener's choice, in the form of microfanclubs supported by platform-provided community features. There are a lot of people who, like me, used to spend a lot more than $10/month on music, and could probably be convinced to spend more than that again if there were reasons.
Of course, not coincidentally, I have ideas about community features that can be provided with math. Lots of ideas. They come to me every :30 while I sleep.
PS: I've seen some speculation that Sleep Fruits is buying their streams. I'm involved enough in fraud-detection at Spotify to say with at least a little bit of confidence that this is probably not the case. Large-scale fraud is pretty easy to detect, and the scale of this is large. It's abusing a systemic weakness, but not obviously dishonestly.
Sleep Fruits is undeniably and intentionally exploiting the systemic weakness of the industry-wide :30-or-more-is-a-play rule, as too are audiobook licensors who split their long content into :30 "chapters". The :30 thing is a bad rule. Most of the straightforward alternatives are also bad, so it wasn't an obviously insane initial system design-choice, but this abuse vector is logical and inevitable.
The effect of the abuse for the label doing it is simple: exploitative multiplication of their "natural" streams by a large factor. x6 if you compare it to rain noise sliced into pop-song-size lengths.
The effect on the rest of the streaming economy is more complicated. More money to Sleep Fruits does mean less money to somebody else, at least in the short term.
Under the current pro-rata royalty-allocation system used by all major subscription streaming services (one big pool, split by stream-share), the effects of Sleep Fruits' abuse are distributed across the whole subscription pool. The burden is shared by all other artists, collectively, but is fractional and negligible for any individual artist. In addition, under pro-rata if an individual listener plays Sleep Fruits overnight, every night, it doesn't change the value of their "real" music-listening activity during the day. Those artists get the same benefit from those fans as they would from a listener who sleeps in silence.
Under the oft-proposed user-centric payment system, in which each listener's payments are split according to only their plays, Sleep Fruits' short-track abuse tactic would be less effective for them. Not as much less effective as you might think, because the same two things that inflate their overall numbers (long-duration background playing + short tracks) inflate their share of each listener's plays. But less, because in the pro-rata model one listener can direct more revenue than they contributed, and in the user-centric model they can't.
In the user-centric model, though, if an individual listener listens to Sleep Fruits overnight, that directly reduces the money that goes to their daytime artists. Where pro-rata disperses the burden, user-centric would concentrate it on the kinds of artists whose fans also listen to background noise. This is probably worse in overall fairness, and it's definitely worse in terms of the listener-artist relationship, which is one of the key emotional arguments for the user-centric model.
The interesting additional economic twist to this particular case, though, is that sleeping to background noise works very badly if it's interrupted by ads. Background listening is thus a powerful incentive for paid subscriptions over ad-supported streaming. (Audiobooks similarly, since they essentially require full on-demand listening control.) So if Sleep Fruits drives background listeners to subscribe, it might be bringing in additional money that could offset or even exceed the amount extracted by its abuse. (Maybe. The counterfactual here is hard to assess quantitatively.)
And although the :30 rule is what made this example newsworthy in its exaggerated effect, in truth it's probably not really the fundamental problem. The deeper issue is just that we subjectively value music based on the attention we pay to it, but we haven't figured out a good way to translate between attention paid and money paid. Switching from play-share to time-share would eliminate the advantage of cutting up rain noise into :30 lengths, but wouldn't change the imbalance between 8 hours/night of sleep loops and 1-2 hours/day of music listening. CDs "solved" this by making you pay for your expected attention with a high fixed entry price, which isn't really any more sensible.
I don't think we're going to solve this with just math, which disappoints me personally, since I'm pretty good at solving math-solvable things with math. But in general I think time-share is a slightly closer approximation of attention-share than play-share, and thus preferable. And rather than trying to discount low-attention listening, which seems problematic and thankless and negative, it seems more practical and appealing to me to try to add incremental additional rewards to high-attention fandom. E.g. higher-cost subscription plans in which the extra money goes directly to artists of the listener's choice, in the form of microfanclubs supported by platform-provided community features. There are a lot of people who, like me, used to spend a lot more than $10/month on music, and could probably be convinced to spend more than that again if there were reasons.
Of course, not coincidentally, I have ideas about community features that can be provided with math. Lots of ideas. They come to me every :30 while I sleep.
PS: I've seen some speculation that Sleep Fruits is buying their streams. I'm involved enough in fraud-detection at Spotify to say with at least a little bit of confidence that this is probably not the case. Large-scale fraud is pretty easy to detect, and the scale of this is large. It's abusing a systemic weakness, but not obviously dishonestly.
¶ 2019 in Music · 6 January 2020 essay/listen/tech
I starting making one music-list a year some time in the 80s, before I really knew enough for there to be any sense to this activity. For a while in the 90s and 00s I got more serious about it, and statistically way better-informed, but there's actually no amount of informedness that transforms a single person's opinions about music into anything that inherently matters to anybody other than people (if any) who happen to share their specific tastes, or extraordinarily patient and maybe slightly creepy friends.
Collect people together, though, and the patterns of their love are sometimes very interesting. For several years I presided computationally over an assembly of nominal expertise, trying to find ways to turn hundreds of opinions into at least plural insights. Hundreds of people is not a lot, though, and asking people to pretend their opinions matter is a dubious way to find out what they really love. I'm not really sad we stopped doing that.
Hundreds of millions of people isn't that much, yet, but it's getting there, and asking people to spend their lives loving all the innumerable things they love is a more realistic proposition than getting them to make short numbered lists on annual deadlines. Finding an individual person who shares your exact taste, in the real world, is not only laborious to the point of preventative difficulty, but maybe not even reliably possible in theory. Finding groups of people in the virtual world who collectively approximate aspects of your taste is, due to the primitive current state of data-transparency, no easier for you.
But it has been my job, for the last few years, to try to figure out algorithmic ways to turn collective love and listening patterns into music insights and experiences. I work at Spotify, so I have extremely good information about what people like in Sweden and Norway, fairly decent information about most of the rest of Europe, the Americas and parts of Asia, and at least glimmers of insight about literally almost everywhere else on Earth. I don't know that much about you, but I know a little bit about a lot of people.
So now I make a lot of lists. Here, in fact, are algorithmically-generated playlists of the songs that defined, united and distinguished the fans and love and new music in 2000+ genres and countries around the world in 2019:
2019 Around the World
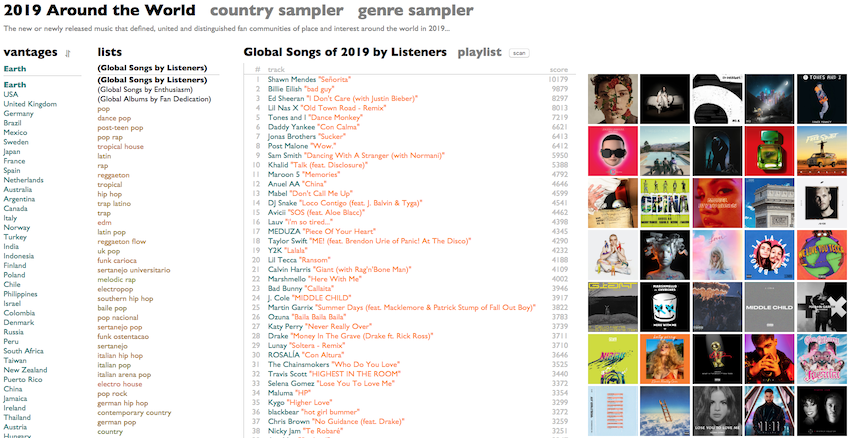
You probably don't share my tastes, and this is a pretty weak unifying force for everybody who isn't me, but there are so many stronger ones. Maybe some of the ones that pull on you are represented here. Maybe some of the communities implied and channeled here have been unknowingly incomplete without you. Maybe you have not yet discovered half of the things you will eventually adore. Maybe this is how you find them.
I found a lot of things this year, myself, some of them in this process of trying to find music for other people, and some of them just by listening. You needn't care about what I like. And if for some reason you do, you can already find out what it is in unmanageable weekly detail. But I like to look back at my own years. Spotify's official forms of nostalgia so far define years purely by listening dates, but as a music geek of a particular sort, what I mean by a year is music that was both made and heard then. New music.
I no longer want to make this list by applying manual reductive retroactive impressions to what I remember of the year, but I also don't have to. Adapting my collective engines to the individual, then, here is the purely data-generated playlist of the new music to which I demonstrated the most actual listening attachment in 2019:
2019 Greatest Hits (for glenn mcdonald)
And for segmented nostalgia, because that's what kind of nostalgist I am, I also used genre metadata and a very small amount of manual tweaking to almost automatically produce three more specialized lists:
Bright Swords in the Void (Metal and metal-adjacent noises, from the floridly melodic to the stochastically apocalyptic.)
Gradient Dissent (Ambient, noise, epicore and other abstract geometries.)
Dancing With Tears (Pop, rock, hip hop and other sentimental forms.)
And finally, although surely this, if anything, will be of interest to absolutely nobody but me, I also used a combination of my own listening, broken down by genre, and the global 2019 genre lists, to produce a list of the songs I missed or intentionally avoided despite their being popular with the fans of my favorite genres.
2019 Greatest Misses (for glenn mcdonald)
I made versions of this Misses list in November and December, to see what I was in danger of missing before the year actually ended, so these songs are the reverse-evolutionary survivors of two generations of augmented remedial listening. But I played it again just now, and it still sounds basically great to me. I'm pretty sure I could spend the next year listening to nothing but songs I missed in 2019 despite trying to hear them all, and it would be just as great in sonic terms. There's something hypothetically comforting in that, at least until I starting trying to figure out what kind of global catastrophe I'm effectively imagining here. I'm alive, but all the musicians in the world are dead? Or there's no surviving technology for recording music, but somehow Spotify servers and the worldwide cell and wifi networks still work?
Easier to live. I now declare 2019 complete and archived. Onwards.
Collect people together, though, and the patterns of their love are sometimes very interesting. For several years I presided computationally over an assembly of nominal expertise, trying to find ways to turn hundreds of opinions into at least plural insights. Hundreds of people is not a lot, though, and asking people to pretend their opinions matter is a dubious way to find out what they really love. I'm not really sad we stopped doing that.
Hundreds of millions of people isn't that much, yet, but it's getting there, and asking people to spend their lives loving all the innumerable things they love is a more realistic proposition than getting them to make short numbered lists on annual deadlines. Finding an individual person who shares your exact taste, in the real world, is not only laborious to the point of preventative difficulty, but maybe not even reliably possible in theory. Finding groups of people in the virtual world who collectively approximate aspects of your taste is, due to the primitive current state of data-transparency, no easier for you.
But it has been my job, for the last few years, to try to figure out algorithmic ways to turn collective love and listening patterns into music insights and experiences. I work at Spotify, so I have extremely good information about what people like in Sweden and Norway, fairly decent information about most of the rest of Europe, the Americas and parts of Asia, and at least glimmers of insight about literally almost everywhere else on Earth. I don't know that much about you, but I know a little bit about a lot of people.
So now I make a lot of lists. Here, in fact, are algorithmically-generated playlists of the songs that defined, united and distinguished the fans and love and new music in 2000+ genres and countries around the world in 2019:
2019 Around the World
You probably don't share my tastes, and this is a pretty weak unifying force for everybody who isn't me, but there are so many stronger ones. Maybe some of the ones that pull on you are represented here. Maybe some of the communities implied and channeled here have been unknowingly incomplete without you. Maybe you have not yet discovered half of the things you will eventually adore. Maybe this is how you find them.
I found a lot of things this year, myself, some of them in this process of trying to find music for other people, and some of them just by listening. You needn't care about what I like. And if for some reason you do, you can already find out what it is in unmanageable weekly detail. But I like to look back at my own years. Spotify's official forms of nostalgia so far define years purely by listening dates, but as a music geek of a particular sort, what I mean by a year is music that was both made and heard then. New music.
I no longer want to make this list by applying manual reductive retroactive impressions to what I remember of the year, but I also don't have to. Adapting my collective engines to the individual, then, here is the purely data-generated playlist of the new music to which I demonstrated the most actual listening attachment in 2019:
2019 Greatest Hits (for glenn mcdonald)
And for segmented nostalgia, because that's what kind of nostalgist I am, I also used genre metadata and a very small amount of manual tweaking to almost automatically produce three more specialized lists:
Bright Swords in the Void (Metal and metal-adjacent noises, from the floridly melodic to the stochastically apocalyptic.)
Gradient Dissent (Ambient, noise, epicore and other abstract geometries.)
Dancing With Tears (Pop, rock, hip hop and other sentimental forms.)
And finally, although surely this, if anything, will be of interest to absolutely nobody but me, I also used a combination of my own listening, broken down by genre, and the global 2019 genre lists, to produce a list of the songs I missed or intentionally avoided despite their being popular with the fans of my favorite genres.
2019 Greatest Misses (for glenn mcdonald)
I made versions of this Misses list in November and December, to see what I was in danger of missing before the year actually ended, so these songs are the reverse-evolutionary survivors of two generations of augmented remedial listening. But I played it again just now, and it still sounds basically great to me. I'm pretty sure I could spend the next year listening to nothing but songs I missed in 2019 despite trying to hear them all, and it would be just as great in sonic terms. There's something hypothetically comforting in that, at least until I starting trying to figure out what kind of global catastrophe I'm effectively imagining here. I'm alive, but all the musicians in the world are dead? Or there's no surviving technology for recording music, but somehow Spotify servers and the worldwide cell and wifi networks still work?
Easier to live. I now declare 2019 complete and archived. Onwards.
¶ If You Do That, the Robots Win · 16 April 2016 essay/listen/tech
[This is the script from a talk I delivered at the EMP Pop Conference today. It was written to be read aloud at an intentionally headlong pace, with somewhat-carefully timed blasts of interstitial music. I've included playable clip-links for the songs here, but the clips are usually from the middles of the songs, and I was playing the beginnings of them in the talk, so it's different. The whole playlist is here, although playing it as a standalone thing would make no sense at all.]

I used to take software jobs to be able to buy records, but buying records is now a way to hear all the world's music like collecting cars is a way to see more of the solar system.
So now I work at Spotify as a zookeeper for playlist-making robots. Recommendation robots have existed for a while now, but people have mostly used them for shopping. Go find me things I might want to buy. "You bought a snorkel, maybe you'd like to buy these other snorkels?"
But what streaming music makes possible, which online music stores did not, is actual programmed music experiences. Instead of trying to sell you more snorkels, these robots can take you out to swim around with the funny-looking fish.
And as robots begin to craft your actual listening experience, it is reasonable, and maybe even morally imperative, to ask if a playlist robot can have an authorial voice, and, if so, what it is?
The answer is: No. Robots have no taste, no agenda, no soul, no self. Moreover, there is no robot. I talk about robots because it's funny and gives you something you can picture, but that's not how anything really happens.
How everything really happens is this: people listen to songs. Different people listen to different songs, and we count which ones, and then try to use computers to do math to find patterns in these numbers. That's what my job actually involves. I go to work, I sit down at my desk (except I actually stand at my fancy Spotify standing desk, because I heard that sitting will kill you and if you die you miss a lot of new releases), and I type computer programs that count the actions of human listeners and do math and produce lists of songs.
So when anybody talks about a fight between machines and humans in music recommendation, you should know that those people do not know what the fuck they are talking about. Music recommendations are machines "versus" humans in the same way that omelets are spatulas "versus" eggs.
So the good news is that you can stop worrying that robots are trying to poison your listening. But the bad news is that you can start worrying about food safety and whether the people operating your spatulas have the faintest idea what food is supposed to taste like.
Because data makes some amazing things possible, but it also makes terrible, incoherent, counter-productive things possible. And I'm going to tell you about some of them.
Counting is the most basic kind of math, and yet even just counting things usefully, in music streaming, is harder than you probably think. For example, this is the most streamed track by the most streamed artist on Spotify:
Various Artists "Kelly Clarkson on Annie Lennox"
Do you recognize the band? They are called "Various Artists", and that is their song "Kelly Clarkson on Annie Lennox", from their album Women in Music - 2015 Stories.
But OK, that's obviously not what we meant. We just need to exclude short commentary tracks, and then this is the most streamed music track by the most streamed artist on Spotify:
Various Artists "El Preso"
Except that's "Various Artists" again. The most streamed music track by an actual artist on Spotify is:
Rihanna "Work"
OK, so that's starting to make some sense. Pretty much all exercises in programmatic music discovery begin with this: can you "discover" Rihanna?
Spotify just launched in Indonesia, and I happen to know that Indonesian music is awesome, because there are people there and they make music, so let's find out what the most popular Indonesian song is.
Justin Bieber "Love Yourself"
I kind of wanted to know what the most popular Indonesian song is, not just the song that is most popular in Indonesia. But if I restrict my query to artists whose country of origin is Indonesia, I get this:
Isyana Sarasvati "Kau Adalah"
Which seems like it might be the Indonesian Lisa Loeb. It's by Isyana Sarasvati, and I looked her up, and she is Indonesian! She's 23, and her Wikipedia page discusses the scholarship she got from the government of Singapore to study music at an academy there, and lists her solo recitals.
It turns out that our data about where artists are from is decent where we have it, but a lot of times we just don't. 34 of the top 100 songs in Indonesia are by artists for whom we don't have locations.
But remember math? Math is cool. In addition to counting listeners in Indonesia, we can compare the listening in Indonesia to the listening in the rest of the world, and find the songs are that most distinctively popular in Indonesia. That gets us to this:
TheOvertunes "Cinta Adalah"
That is The Overtunes, who turn out to be a band of three Indonesian brothers who became famous when one of them won X Factor Indonesia in 2013.
But that's still not really what I wanted. It's like being curious about Indonesian food and buying a bag of Indonesian supermarket-brand potato chips.
I kind of wanted to hear some, I dunno, Indonesian Indie music. I assume they have some, because they have people, and they have X Factor, and that's bound piss some people off enough to start their own bands.
So if we switch from just counting to doing a bit more data analysis -- actually, quite a lot of data analysis -- we can discover that yes, there is an indie scene in Indonesia, and we can computationally model which bands are more or less a part of it, and without ever stepping foot in Indonesia, we can produce an algorithmic introduction to The Sound of Indonesian Indie, and it begins with this:
Sheila on 7 "Dan..."
That is Shelia on 7 doing "Dan...", and I looked them up, too. Rolling Stone Indonesia said that their debut album was one of the 150 Greatest Indonesian Albums of All Time, and they are the first band to sell more than 1m copies of each of their first 3 albums in Indonesia alone.
Of course, they're also on Sony Music Indonesia, and I assume that at least some of those millions of people who bought their first 3 albums, before Spotify launched in Indonesia and destroyed the album-sales market, are still alive and still remember them. One of the hard parts about running a global music service from your headquarters in Stockholm and your music-intelligence outpost in Boston, is that you need to be able to find Indonesian music that people who already know about Indonesian music don't already know about.
But once you've modeled the locally-unsurprising canonical core of Indonesian Indie music, you can use that to find people who spend unusually large blocks of their listening time listening to canonical Indonesian Indie music (most of whom are in Indonesia, but they don't have to be; some of them might be off at a music academy in Singapore, where Spotify has been available since 2013), and then you can calculate what music is most distinctively popular among serious Indonesian Indie fans, even if you have no data to tell you where it comes from. And that gets us things like this:
Sisitipsi "Alkohol"
That is "Alkohol" by Sistipsi. A Google search for that song finds only 8400 results, which appear to all be in Indonesian. Their band home page is a wordpress.com site, and they had 263 global Spotify listeners last month.
PILOTZ "Memang Aku"
PILOTZ, with a Z. Also from Indonesia! 117 listeners.
Hellcrust "Janji Api"
Hellcrust. 44 listeners last month. I looked them up, and yes, they're from Jakarta.
199x "Goodest Riddance"
199x. 14 monthly listeners! Also, maybe actually from Malaysia, not Indonesia, but in music recommending it's almost as impressive if you can be a little bit wrong as it is if you can be right, because usually when you're wrong you'll get Polish folk-techno or metalcore with Harry Potter fanfic lyrics.
So that's what a lot of my days are like. Pose a question, write some code, find some songs, and then try to figure out whether those songs are even vaguely answering the question or not.
And if the question is about Indonesia, that method kind of works.
But we also have 100 million listeners on Spotify, and we would like to be able to produce personalized listening experiences for each of them. Actually, we'd like to be able to produce multiple listening experiences for each of them. And we can't hire all of our listeners to work for us full-time curating their own individual personal music experiences, because apparently the business model doesn't work? So it's computers or nothing.
People, it turns out, are somewhat harder than countries.
For starters, here is the track I have played the most on Spotify:
Jewel "Twinkle, Twinkle Little Star"
As humans, we might guess that it is not quite accurate to say that that is my favorite song, and we might have a very specific theory about why that is. As humans, we might guess that the number of times I have played the song after that has a different meaning:
CHVRCHES "Leave a Trace"
In the latter case, I love CHVRCHES so much. But in the former case, I love my daughter even more than I love CHVRCHES, and some nights she really needs to hear Jewel sing "Twinkle Twinkle Little Star" at bedtime.
And if we are still in the early days of algorithmically programmed listening experiences, at all, then we're in what I hope we will look back on as the early- to mid- prehistory of algorithmic personalized listening experiences. I can't tell you exactly how they work, because we're still trying to make them work. But I can tell you 7 things I've learned that I think are principles to guide us towards a future in which dumbfoundingly amazing music you could never find on your own just flows out of the invisible sea of information directly into your ears. When you want it to, I don't mean you can't shut it off.
1. No music listener is ever only one thing.
I mean, you can't assume they are. I have a coworker named Matt who basically only listens to skate-punk music, ever, and we test all personalization things on him first, because you can tell immediately if it's wrong. Right: Warzone "Rebels Til We Die". Wrong: The Damned "Wounded Wolf - Original Mix". But other than him, almost everybody turns out to have some non-obvious combination of tastes. I listen to beepy electronica (Red Cell "Vial of Dreams") and gentle soothing Dark Funeral "Where Shadows Forever Reign" and Kangding Ray "Ardent", and sentimental Southern European arena pop (Gianluca Corrao "Amanti d'estate"), and if you just average that all together it turns out you mostly end up with mopey indie music that I don't like at all: Wyvern Lingo "Beast at the Door"
2. All information is partial.
We know what you play on Spotify, but we don't know what you listen to on the radio in the car, or what your spouse plays in your house while you're making dinner, or what you loved as a kid or even what you played incessantly on Rdio before it went bankrupt. For example, this is one of my favorite new albums this year: Magnum "Sacred Blood 'Divine' Lies". I adore Magnum, but I hadn't played them on Spotify at all. But my robot knew they were similar to other things it knew I liked. Sometimes music "discovery" is not about discovering things that you don't know, it's about the computer inferring aspects of your taste that you had previously hidden from it.
3. Variety is good.
It is in the interest of listeners and Spotify and music makers if people listen to more and more varied music. If all anybody wanted to hear was this once a day -- Adele "Hello" -- there would be no music business and no streaming and no joy or sunlight. Part of my job is to crack open the shell of the sky. Terabrite "Hello". If you are excited to hear what happens next, you will be more likely to pay us $10, and we will pay the artists more for the music you play, and they will make more of it instead of getting terrible day-jobs working for inbound marketing companies, and the world will be a better place.
4. People like discovering new music.
They may hate the song you want them to love. They may have a limited tolerance for doing work to discover music, or for trial-and-erroring through lots of music they don't like in order to find it, but neither of those things mean that they wouldn't be thrilled by the right new song if somebody could find it for them. One of you will come up after this to ask me what this song is: Sweden "Stocholm". One of you, probably a different person, will wonder about this: Draper/Prides "Break Over You". I have like a million of those. I mean actually like an actual million of those.
5. Bernie Sanders is right.
It is in the interest of the world of music creators if the streaming music business exerts a bit of democratic-socialist pressure against income inequality. The incremental human value of another person listening to "Shake It Off" again is arguably positive, but it's probably also considerably smaller than the value of that person listening to a new song by a new songwriter who doesn't already have enough money to live out the rest of their life inside a Manhattan loft whose walls are covered with thumbdrives full of bitcoins and #1-fan selfies. Anthem Lights "Shake It Off". Taylor, if you're listening, I'm going to keep playing shitty covers of your songs until you put the real ones back on Spotify. That's how it works.
6. If you're going to try to play people what they actually like, you have to be prepared for whatever that is.
DJ Loppetiss "Janteloven 2016"
That's "Russelåter", which is a crazy Norwegian thing where high school kids finish their exams way before the end of the senior year, so in the spring they get together in little gangs, give themselves goofy gang names, purchase actual tour buses from the previous year's gangs, have them repainted with their gang logo, commission terrible crap-EDM gang theme songs from Norwegian producers for whom this is the most profitable local music market, and then spend weeks driving around the suburbs of Oslo in these buses, drinking and never changing their clothes and blasting their appalling theme songs. I did not make this up.
7. Recommendation incurs responsibility.
If people are going to give up minutes of their finite lives to listen to something they would otherwise never have been burdened with, it better have the potential, however vague or elusive, to change their life. You can't, however tantalizing the prospect might seem, just play something because you want to. (Aedliga "Futility Has Its Limits") Like I said, you definitely can't do that. If you do that, the robots win.
Thank you.
I used to take software jobs to be able to buy records, but buying records is now a way to hear all the world's music like collecting cars is a way to see more of the solar system.
So now I work at Spotify as a zookeeper for playlist-making robots. Recommendation robots have existed for a while now, but people have mostly used them for shopping. Go find me things I might want to buy. "You bought a snorkel, maybe you'd like to buy these other snorkels?"
But what streaming music makes possible, which online music stores did not, is actual programmed music experiences. Instead of trying to sell you more snorkels, these robots can take you out to swim around with the funny-looking fish.
And as robots begin to craft your actual listening experience, it is reasonable, and maybe even morally imperative, to ask if a playlist robot can have an authorial voice, and, if so, what it is?
The answer is: No. Robots have no taste, no agenda, no soul, no self. Moreover, there is no robot. I talk about robots because it's funny and gives you something you can picture, but that's not how anything really happens.
How everything really happens is this: people listen to songs. Different people listen to different songs, and we count which ones, and then try to use computers to do math to find patterns in these numbers. That's what my job actually involves. I go to work, I sit down at my desk (except I actually stand at my fancy Spotify standing desk, because I heard that sitting will kill you and if you die you miss a lot of new releases), and I type computer programs that count the actions of human listeners and do math and produce lists of songs.
So when anybody talks about a fight between machines and humans in music recommendation, you should know that those people do not know what the fuck they are talking about. Music recommendations are machines "versus" humans in the same way that omelets are spatulas "versus" eggs.
So the good news is that you can stop worrying that robots are trying to poison your listening. But the bad news is that you can start worrying about food safety and whether the people operating your spatulas have the faintest idea what food is supposed to taste like.
Because data makes some amazing things possible, but it also makes terrible, incoherent, counter-productive things possible. And I'm going to tell you about some of them.
Counting is the most basic kind of math, and yet even just counting things usefully, in music streaming, is harder than you probably think. For example, this is the most streamed track by the most streamed artist on Spotify:
Various Artists "Kelly Clarkson on Annie Lennox"
Do you recognize the band? They are called "Various Artists", and that is their song "Kelly Clarkson on Annie Lennox", from their album Women in Music - 2015 Stories.
But OK, that's obviously not what we meant. We just need to exclude short commentary tracks, and then this is the most streamed music track by the most streamed artist on Spotify:
Various Artists "El Preso"
Except that's "Various Artists" again. The most streamed music track by an actual artist on Spotify is:
Rihanna "Work"
OK, so that's starting to make some sense. Pretty much all exercises in programmatic music discovery begin with this: can you "discover" Rihanna?
Spotify just launched in Indonesia, and I happen to know that Indonesian music is awesome, because there are people there and they make music, so let's find out what the most popular Indonesian song is.
Justin Bieber "Love Yourself"
I kind of wanted to know what the most popular Indonesian song is, not just the song that is most popular in Indonesia. But if I restrict my query to artists whose country of origin is Indonesia, I get this:
Isyana Sarasvati "Kau Adalah"
Which seems like it might be the Indonesian Lisa Loeb. It's by Isyana Sarasvati, and I looked her up, and she is Indonesian! She's 23, and her Wikipedia page discusses the scholarship she got from the government of Singapore to study music at an academy there, and lists her solo recitals.
It turns out that our data about where artists are from is decent where we have it, but a lot of times we just don't. 34 of the top 100 songs in Indonesia are by artists for whom we don't have locations.
But remember math? Math is cool. In addition to counting listeners in Indonesia, we can compare the listening in Indonesia to the listening in the rest of the world, and find the songs are that most distinctively popular in Indonesia. That gets us to this:
TheOvertunes "Cinta Adalah"
That is The Overtunes, who turn out to be a band of three Indonesian brothers who became famous when one of them won X Factor Indonesia in 2013.
But that's still not really what I wanted. It's like being curious about Indonesian food and buying a bag of Indonesian supermarket-brand potato chips.
I kind of wanted to hear some, I dunno, Indonesian Indie music. I assume they have some, because they have people, and they have X Factor, and that's bound piss some people off enough to start their own bands.
So if we switch from just counting to doing a bit more data analysis -- actually, quite a lot of data analysis -- we can discover that yes, there is an indie scene in Indonesia, and we can computationally model which bands are more or less a part of it, and without ever stepping foot in Indonesia, we can produce an algorithmic introduction to The Sound of Indonesian Indie, and it begins with this:
Sheila on 7 "Dan..."
That is Shelia on 7 doing "Dan...", and I looked them up, too. Rolling Stone Indonesia said that their debut album was one of the 150 Greatest Indonesian Albums of All Time, and they are the first band to sell more than 1m copies of each of their first 3 albums in Indonesia alone.
Of course, they're also on Sony Music Indonesia, and I assume that at least some of those millions of people who bought their first 3 albums, before Spotify launched in Indonesia and destroyed the album-sales market, are still alive and still remember them. One of the hard parts about running a global music service from your headquarters in Stockholm and your music-intelligence outpost in Boston, is that you need to be able to find Indonesian music that people who already know about Indonesian music don't already know about.
But once you've modeled the locally-unsurprising canonical core of Indonesian Indie music, you can use that to find people who spend unusually large blocks of their listening time listening to canonical Indonesian Indie music (most of whom are in Indonesia, but they don't have to be; some of them might be off at a music academy in Singapore, where Spotify has been available since 2013), and then you can calculate what music is most distinctively popular among serious Indonesian Indie fans, even if you have no data to tell you where it comes from. And that gets us things like this:
Sisitipsi "Alkohol"
That is "Alkohol" by Sistipsi. A Google search for that song finds only 8400 results, which appear to all be in Indonesian. Their band home page is a wordpress.com site, and they had 263 global Spotify listeners last month.
PILOTZ "Memang Aku"
PILOTZ, with a Z. Also from Indonesia! 117 listeners.
Hellcrust "Janji Api"
Hellcrust. 44 listeners last month. I looked them up, and yes, they're from Jakarta.
199x "Goodest Riddance"
199x. 14 monthly listeners! Also, maybe actually from Malaysia, not Indonesia, but in music recommending it's almost as impressive if you can be a little bit wrong as it is if you can be right, because usually when you're wrong you'll get Polish folk-techno or metalcore with Harry Potter fanfic lyrics.
So that's what a lot of my days are like. Pose a question, write some code, find some songs, and then try to figure out whether those songs are even vaguely answering the question or not.
And if the question is about Indonesia, that method kind of works.
But we also have 100 million listeners on Spotify, and we would like to be able to produce personalized listening experiences for each of them. Actually, we'd like to be able to produce multiple listening experiences for each of them. And we can't hire all of our listeners to work for us full-time curating their own individual personal music experiences, because apparently the business model doesn't work? So it's computers or nothing.
People, it turns out, are somewhat harder than countries.
For starters, here is the track I have played the most on Spotify:
Jewel "Twinkle, Twinkle Little Star"
As humans, we might guess that it is not quite accurate to say that that is my favorite song, and we might have a very specific theory about why that is. As humans, we might guess that the number of times I have played the song after that has a different meaning:
CHVRCHES "Leave a Trace"
In the latter case, I love CHVRCHES so much. But in the former case, I love my daughter even more than I love CHVRCHES, and some nights she really needs to hear Jewel sing "Twinkle Twinkle Little Star" at bedtime.
And if we are still in the early days of algorithmically programmed listening experiences, at all, then we're in what I hope we will look back on as the early- to mid- prehistory of algorithmic personalized listening experiences. I can't tell you exactly how they work, because we're still trying to make them work. But I can tell you 7 things I've learned that I think are principles to guide us towards a future in which dumbfoundingly amazing music you could never find on your own just flows out of the invisible sea of information directly into your ears. When you want it to, I don't mean you can't shut it off.
1. No music listener is ever only one thing.
I mean, you can't assume they are. I have a coworker named Matt who basically only listens to skate-punk music, ever, and we test all personalization things on him first, because you can tell immediately if it's wrong. Right: Warzone "Rebels Til We Die". Wrong: The Damned "Wounded Wolf - Original Mix". But other than him, almost everybody turns out to have some non-obvious combination of tastes. I listen to beepy electronica (Red Cell "Vial of Dreams") and gentle soothing Dark Funeral "Where Shadows Forever Reign" and Kangding Ray "Ardent", and sentimental Southern European arena pop (Gianluca Corrao "Amanti d'estate"), and if you just average that all together it turns out you mostly end up with mopey indie music that I don't like at all: Wyvern Lingo "Beast at the Door"
2. All information is partial.
We know what you play on Spotify, but we don't know what you listen to on the radio in the car, or what your spouse plays in your house while you're making dinner, or what you loved as a kid or even what you played incessantly on Rdio before it went bankrupt. For example, this is one of my favorite new albums this year: Magnum "Sacred Blood 'Divine' Lies". I adore Magnum, but I hadn't played them on Spotify at all. But my robot knew they were similar to other things it knew I liked. Sometimes music "discovery" is not about discovering things that you don't know, it's about the computer inferring aspects of your taste that you had previously hidden from it.
3. Variety is good.
It is in the interest of listeners and Spotify and music makers if people listen to more and more varied music. If all anybody wanted to hear was this once a day -- Adele "Hello" -- there would be no music business and no streaming and no joy or sunlight. Part of my job is to crack open the shell of the sky. Terabrite "Hello". If you are excited to hear what happens next, you will be more likely to pay us $10, and we will pay the artists more for the music you play, and they will make more of it instead of getting terrible day-jobs working for inbound marketing companies, and the world will be a better place.
4. People like discovering new music.
They may hate the song you want them to love. They may have a limited tolerance for doing work to discover music, or for trial-and-erroring through lots of music they don't like in order to find it, but neither of those things mean that they wouldn't be thrilled by the right new song if somebody could find it for them. One of you will come up after this to ask me what this song is: Sweden "Stocholm". One of you, probably a different person, will wonder about this: Draper/Prides "Break Over You". I have like a million of those. I mean actually like an actual million of those.
5. Bernie Sanders is right.
It is in the interest of the world of music creators if the streaming music business exerts a bit of democratic-socialist pressure against income inequality. The incremental human value of another person listening to "Shake It Off" again is arguably positive, but it's probably also considerably smaller than the value of that person listening to a new song by a new songwriter who doesn't already have enough money to live out the rest of their life inside a Manhattan loft whose walls are covered with thumbdrives full of bitcoins and #1-fan selfies. Anthem Lights "Shake It Off". Taylor, if you're listening, I'm going to keep playing shitty covers of your songs until you put the real ones back on Spotify. That's how it works.
6. If you're going to try to play people what they actually like, you have to be prepared for whatever that is.
DJ Loppetiss "Janteloven 2016"
That's "Russelåter", which is a crazy Norwegian thing where high school kids finish their exams way before the end of the senior year, so in the spring they get together in little gangs, give themselves goofy gang names, purchase actual tour buses from the previous year's gangs, have them repainted with their gang logo, commission terrible crap-EDM gang theme songs from Norwegian producers for whom this is the most profitable local music market, and then spend weeks driving around the suburbs of Oslo in these buses, drinking and never changing their clothes and blasting their appalling theme songs. I did not make this up.
7. Recommendation incurs responsibility.
If people are going to give up minutes of their finite lives to listen to something they would otherwise never have been burdened with, it better have the potential, however vague or elusive, to change their life. You can't, however tantalizing the prospect might seem, just play something because you want to. (Aedliga "Futility Has Its Limits") Like I said, you definitely can't do that. If you do that, the robots win.
Thank you.
¶ The Satan:Noise Ratio · 19 April 2015 essay/listen/tech
Through a roundabout series of connections, I got invited to be part of a roundtable panel at EMP Pop 2015, which ended up (in keeping with this year's themes of Music, Weirdness and Transgression) being a group deliberation on the subject of The Worst Song in the World.
And since I was going to be there, and conference rules allowed for solo proposals in addition to the group thing, I figured I might as well also try something fun and weird and outside of my usual current data-alchemical domain.
In the end the thing ended up being not quite free of data-alchemy in the same way that my songs without drums always somehow develop drum tracks. But it's not about data alchemy. At least mostly not.
All the talks are supposed to eventually be available in audio form, but in the meantime, here is the script I was more or less working from. To reproduce the auditorium experience you should blast at least the first 20 seconds or so of each song as you encounter it in the text, and imagine me intoning the names of the songs in monster-truck-rally announcer-voice, and then saying everything else really fast and excitedly because a) you only get 20 minutes, and b) it was 9:20am on the Sunday morning after the Saturday night conference party and some people might need a little help relocating their attentiveness.
(Also, be forewarned that neither the talk nor the music discussed is intended for underage audiences or people who are insecure about religion or genuinely frightened by grown men growling like monsters.)
The Satan:Noise Ratio
or
Triangulations of the Abyss
I grew up in what I wouldn't call a religious community, exactly, but certainly one that was dominated by the assumption of Christianity. My social status was kind of established when I told two members of the football team that the universe was formed out of dust, not Godliness, and it really didn't make any difference whether you liked that idea or not. This was second grade. We had a football team in second grade.
By the time I discovered heavy metal, I was pretty ready for some kind of comprehensive alternative. Science fiction, existentialism, atheism, algebra, Black Sabbath. These all seemed to frighten people, which suggested they were good and powerful ingredients. But if you're going to fight against football in Texas, you have to have your shit organized. You need a program.
Obviously as an atheist I wasn't going to believe in Satan any more than I was going to believe in elves, but the idea of Satanism seemed potentially compelling anyway. Like Scientology, but with roots, and better iconography, and fewer videotapes to buy. And I had learned a lot from reading the liner notes to Rush albums, so I dug into Black Sabbath albums with the same enthusiasm.
Black Sabbath "After Forever"
[You have to remember that at the time, that was really heavy. But the words go like this:]
Black Sabbath "Heaven & Hell"
But OK, what about Judas Priest. Didn't two guys kill themselves after listening to Judas Priest? Now we're getting serious.
Judas Priest "Saints in Hell"
But whatever. Before I found the Satanism I was looking for, New Wave happened, and it turned out that androgyny and drum machines scared the football boys way more than Satan.
And then I left Texas and went to Harvard and took on a very different set of social challenges. So the next time I cycled back into metal, as I always do no matter how many other things I'm into, I wasn't looking for more elaborate pentagrams to shock football boys, I was looking for more hermeneutic nuances to situate and contextualize metal for comparative-lit majors who listened to the Minutemen and the Talking Heads.
Slayer. The Antichrist. Fucking yes. Slayer makes Sabbath with Ozzy sound like Wings, and Sabbath with Dio sound like Van Halen with Sammy Hagar.
Slayer "The Antichrist"
But what about Bathory? In Nomine Satanas. Fucking Latin! Or something...
Bathory "In Nomine Satanas"
Emperor. These are Norwegian actual church-burning dudes. Although, it's Scandinavia, so the church-burning was actually part of a progressive urban planning scheme with multi-use pentagrams in pleasant, radiant-heated public spaces.
Emperor "Inno a Satana"
Gorgoroth "Possessed by Satan"
And maybe what we fear guides our evasions so inexorably that we always end up confirming our suspicions by our nature, but my love of metal motivated and informed my work designing data-analysis software as much as it haunted my attempts to understand emotional resonance, and gradually over the years my writing about music for people bled into writing about music for computers, and that's how I eventually ended up at Spotify, where we have a lot of computers and the largest mass of data about music that humanity has ever collected. And this makes it possible to find out about a lot of metal that you might not otherwise know about. A lot. And a lot of everything else. So I ended up making this genre map, to try to make some sense of it all.

And having organized the world into 1375 genres (which is approximately 666 times 2), I can now answer some other questions about them. Just a few days ago, in fact, purely coincidentally and in no way because I was writing this talk at the last minute without a really clear idea where I was going with it, I decided to reverse-index all the words in the titles of all the songs in the world, and then, using BLACK MATH, find and rank the words that appear most disproportionately in each genre.
It wasn't totally obvious whether this would produce a magic quantification of scattered souls, or a polite visit from some Mumford-and-Sons fans in the IT department, but here are some examples of what it produced in a few genres you might know:
a cappella: medley love somebody your girl home time over will with when need around life what tonight song that don't just
acoustic blues: blues woman boogie baby mama moan down mississippi gonna ain't going worried chicago shake long don't rider jail poor woogie
modern country rock: country beer that's that whiskey love good like cowboy truck don't she's carolina back ain't just wanna this with dirt
east coast hip hop: featuring edited kool explicit rhyme triple hood shit album game check ghetto what streets money flow version that style
west coast rap: gangsta dogg featuring niggaz nate snoop hood ghetto playa money pimp thang shit smoke game bitch life funk ain't west
I'd say that shit is doing something. [The whole thing is here.]
Using this, I can finally figure out the most Satanic of all metal subgenres. It is Black Thrash, whose top words go like this:
satanic blasphemy unholy death infernal antichrist satan hell blood holocaust evil metal nuclear doom vengeance black flames darkness funeral iron
If Satanism is fucking anywhere, it is here.
Nifelheim "Envoy of Lucifer"
OK, no idea what they're saying there.
Destroyer 666 "Satanic Speed Metal"
Um.
Warhammer "The Claw of Religion"
Sathanas "Reign of the Antichrist"
However, I have a lot of other metal subgenres to work with, and I can actually reorganize the world as if Black Thrash were its point of origin, and then as we move slowly away from that point, genre by genre, we can start to see the patterns change.
"Satan" begins to disappear.
"Christ" goes away.
"Damnation" no longer so much of a concern.
"Chaos" starts to appear.
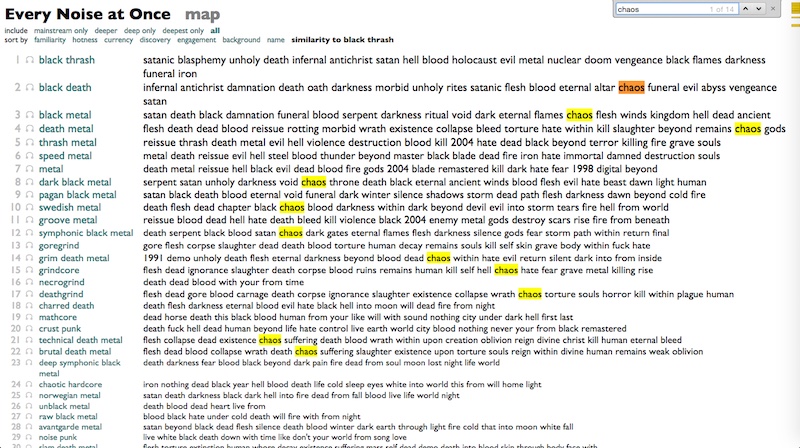
"Darkness" is everywhere.
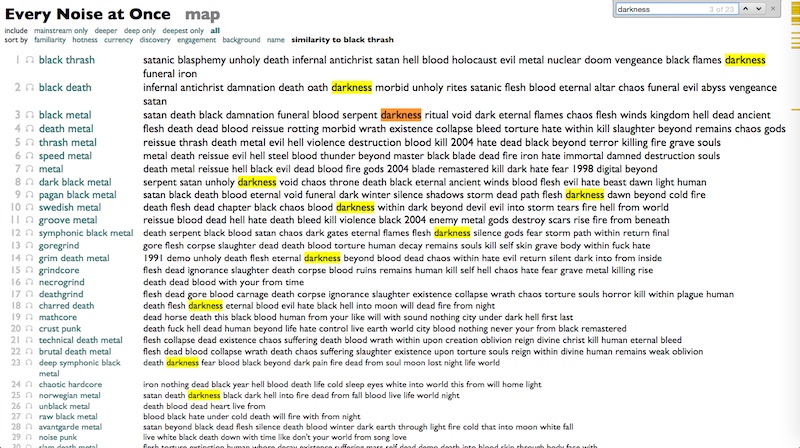
"Eternal" fascinates us.
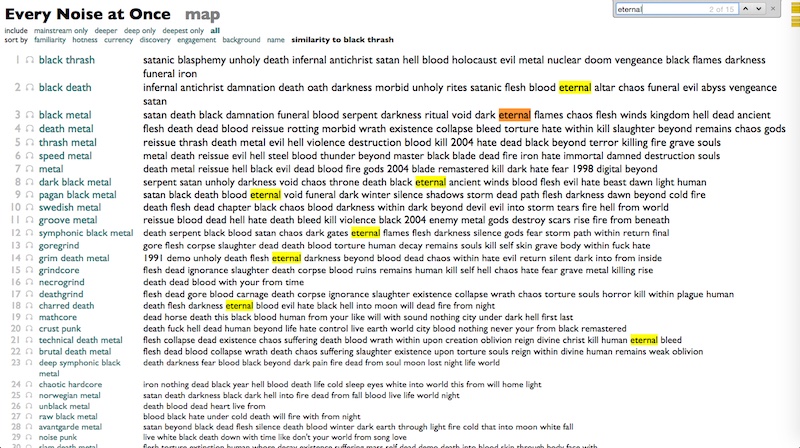
As does "Beyond".
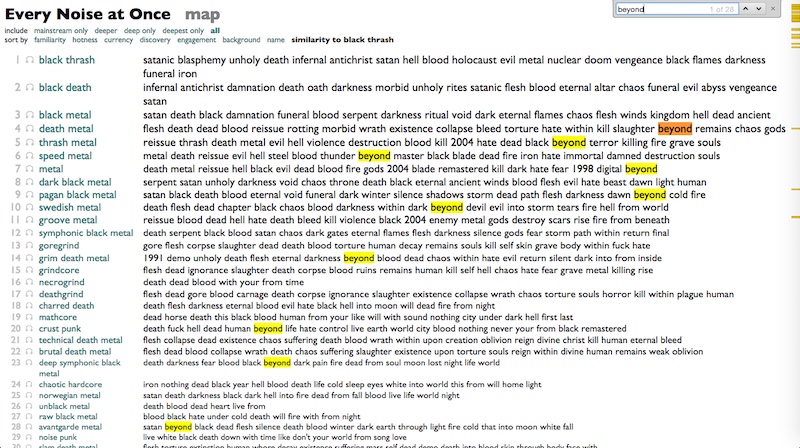
"Death", always death.
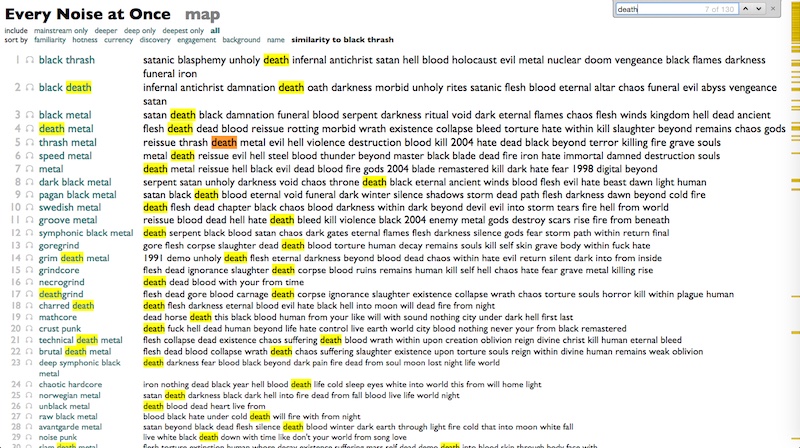
And over and over, at the top of almost every list that doesn't start with "Death": "Flesh".
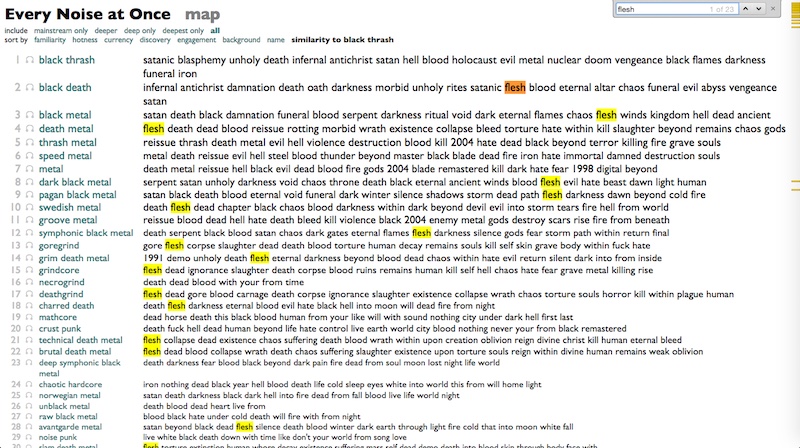
Except groove metal, where the number 1 term is "Reissue".
So my mistake, maybe, was in assuming I was looking for a philosophy that called itself Satanic. Give up that constraint, and ideas start to coalesce after all.
Entombed "Left Hand Path"
Celtic Frost "Os Abysmi Vel Daath"
OK, first of all, the band is called Totalselfhatred, and they sound like this. Dreamy.
Deathspell Omega "Chaining the Katechon"
That's a 22-minute song, and it does not fade in.
1. Babel. Acceptance of chaos, instead of a futile struggle for order or serenity
2. The Codex. To exist in chaos is to seek complexity over simplicity
3. The Void. There is beauty in darkness
4. The Scythe. There are either no illusions, or all illusions, but either way, only death is real
Which all adds up, I think, to something that I basically understood in second grade, after all: grimly acknowledged free will. That is the philosophical core of metal, as an art form. That is the exact rebellion I was seeking. To choose Satan, and particularly to choose Satan without giving him any positive qualities, is to assert that the act of choosing is more important than the actual choice. To choose death is to assert that choosing is more important than living. To choose death symbolically is somewhat more powerful than choosing it literally, because you can choose it symbolically more than once, while gives you a chance to refine your symbolism.
Blut Aus Nord "The Choir of the Dead"
That is Blut Aus Nord's "The Choir of the Dead", from an album actually called The Work Which Transforms God. What does it say? I dunno. But what does it mean? "Hail Satan" is "Think for yourself" plus noise.
Thank you, and see you in Hell.
[The whole playlist that I was playing from is on Spotify here: Triangulations of the Abyss.]
Thanks to the Program Committee and the audience for indulging this whim, and particularly to Eric Weisbard for backing up his early-morning scheduling of this racket by showing up to moderate the session himself.
And since I was going to be there, and conference rules allowed for solo proposals in addition to the group thing, I figured I might as well also try something fun and weird and outside of my usual current data-alchemical domain.
In the end the thing ended up being not quite free of data-alchemy in the same way that my songs without drums always somehow develop drum tracks. But it's not about data alchemy. At least mostly not.
All the talks are supposed to eventually be available in audio form, but in the meantime, here is the script I was more or less working from. To reproduce the auditorium experience you should blast at least the first 20 seconds or so of each song as you encounter it in the text, and imagine me intoning the names of the songs in monster-truck-rally announcer-voice, and then saying everything else really fast and excitedly because a) you only get 20 minutes, and b) it was 9:20am on the Sunday morning after the Saturday night conference party and some people might need a little help relocating their attentiveness.
(Also, be forewarned that neither the talk nor the music discussed is intended for underage audiences or people who are insecure about religion or genuinely frightened by grown men growling like monsters.)
The Satan:Noise Ratio
or
Triangulations of the Abyss
I grew up in what I wouldn't call a religious community, exactly, but certainly one that was dominated by the assumption of Christianity. My social status was kind of established when I told two members of the football team that the universe was formed out of dust, not Godliness, and it really didn't make any difference whether you liked that idea or not. This was second grade. We had a football team in second grade.
By the time I discovered heavy metal, I was pretty ready for some kind of comprehensive alternative. Science fiction, existentialism, atheism, algebra, Black Sabbath. These all seemed to frighten people, which suggested they were good and powerful ingredients. But if you're going to fight against football in Texas, you have to have your shit organized. You need a program.
Obviously as an atheist I wasn't going to believe in Satan any more than I was going to believe in elves, but the idea of Satanism seemed potentially compelling anyway. Like Scientology, but with roots, and better iconography, and fewer videotapes to buy. And I had learned a lot from reading the liner notes to Rush albums, so I dug into Black Sabbath albums with the same enthusiasm.
Black Sabbath "After Forever"
[You have to remember that at the time, that was really heavy. But the words go like this:]
I think it was true it was people like you that crucified ChristPuzzling. But then, as if realizing they were missing something, they got a new singer whose name was Dio, and made an album called Heaven & Hell.
I think it is sad the opinion you had was the only one voiced
Will you be so sure when your day is near, say you don't believe?
You had the chance but you turned it down, now you can't retrieve
Black Sabbath "Heaven & Hell"
Sing me a song, you're a singerThe music: solid. The lyrics? Not exactly "Red Barchetta".
Do me a wrong, you're a bringer of evil
The Devil is never a maker
The less that you give, you're a taker
So it's on and on and on, it's Heaven and Hell, oh well
…
Fool, fool! You've got to bleed for the dancer!
But OK, what about Judas Priest. Didn't two guys kill themselves after listening to Judas Priest? Now we're getting serious.
Judas Priest "Saints in Hell"
Cover your fistsOK, if I wanted a fucking rhyming "evil" version of Noah's Ark...
Razor your spears
It's been our possession
For 8,000 years
Fetch the scream eagles
Unleash the wild cats
Set loose the king cobras
And blood sucking bats
But whatever. Before I found the Satanism I was looking for, New Wave happened, and it turned out that androgyny and drum machines scared the football boys way more than Satan.
And then I left Texas and went to Harvard and took on a very different set of social challenges. So the next time I cycled back into metal, as I always do no matter how many other things I'm into, I wasn't looking for more elaborate pentagrams to shock football boys, I was looking for more hermeneutic nuances to situate and contextualize metal for comparative-lit majors who listened to the Minutemen and the Talking Heads.
Slayer. The Antichrist. Fucking yes. Slayer makes Sabbath with Ozzy sound like Wings, and Sabbath with Dio sound like Van Halen with Sammy Hagar.
Slayer "The Antichrist"
I am the AntichristSo, that's not Satanic, that's Christian. I mean, it's sort of ironic, Slayer of course were the original modern hipsters.
All love is lost
Insanity is what I am
Eternally my soul will rot (rot... rot)
But what about Bathory? In Nomine Satanas. Fucking Latin! Or something...
Bathory "In Nomine Satanas"
Ink the pen with bloodJesus fucking christ: more fealty.
Now sign your destiny to me
Emperor. These are Norwegian actual church-burning dudes. Although, it's Scandinavia, so the church-burning was actually part of a progressive urban planning scheme with multi-use pentagrams in pleasant, radiant-heated public spaces.
Emperor "Inno a Satana"
O' mighty Lord of the Night. Master of beasts. Bringer of awe and derision.Satan's uvula! "Harkee"?
Thou whose spirit lieth upon every act of oppression, hatred and strife.
Thou whose presence dwelleth in every shadow.
Thou who strengthen the power of every quietus.
Thou who sway every plague and storm.
Harkee.
Gorgoroth "Possessed by Satan"
worldwide revolution has occurredWe rape the nuns with desire? This is a program of sorts, I guess. But not one that offered solutions to any problems I actually had. But after a while, I kind of stopped asking music to solve any problems in my life that weren't about music. As an adult, the main thing I asked from my Satanic Norwegian metal was leads for where I could find more of it. The most constant internal theme in my life has been the desperate gnawing suspicion that all the music I know is only the tiniest sliver of what actually exists.
holy war, execution of sodomy
We are possessed by the moon
We are possessed by evil
We are possessed by Satan
possessed
possessed by satan
and then we rape the nuns with desire
And maybe what we fear guides our evasions so inexorably that we always end up confirming our suspicions by our nature, but my love of metal motivated and informed my work designing data-analysis software as much as it haunted my attempts to understand emotional resonance, and gradually over the years my writing about music for people bled into writing about music for computers, and that's how I eventually ended up at Spotify, where we have a lot of computers and the largest mass of data about music that humanity has ever collected. And this makes it possible to find out about a lot of metal that you might not otherwise know about. A lot. And a lot of everything else. So I ended up making this genre map, to try to make some sense of it all.
And having organized the world into 1375 genres (which is approximately 666 times 2), I can now answer some other questions about them. Just a few days ago, in fact, purely coincidentally and in no way because I was writing this talk at the last minute without a really clear idea where I was going with it, I decided to reverse-index all the words in the titles of all the songs in the world, and then, using BLACK MATH, find and rank the words that appear most disproportionately in each genre.
It wasn't totally obvious whether this would produce a magic quantification of scattered souls, or a polite visit from some Mumford-and-Sons fans in the IT department, but here are some examples of what it produced in a few genres you might know:
a cappella: medley love somebody your girl home time over will with when need around life what tonight song that don't just
acoustic blues: blues woman boogie baby mama moan down mississippi gonna ain't going worried chicago shake long don't rider jail poor woogie
modern country rock: country beer that's that whiskey love good like cowboy truck don't she's carolina back ain't just wanna this with dirt
east coast hip hop: featuring edited kool explicit rhyme triple hood shit album game check ghetto what streets money flow version that style
west coast rap: gangsta dogg featuring niggaz nate snoop hood ghetto playa money pimp thang shit smoke game bitch life funk ain't west
I'd say that shit is doing something. [The whole thing is here.]
Using this, I can finally figure out the most Satanic of all metal subgenres. It is Black Thrash, whose top words go like this:
satanic blasphemy unholy death infernal antichrist satan hell blood holocaust evil metal nuclear doom vengeance black flames darkness funeral iron
If Satanism is fucking anywhere, it is here.
Nifelheim "Envoy of Lucifer"
OK, no idea what they're saying there.
Destroyer 666 "Satanic Speed Metal"
Um.
Warhammer "The Claw of Religion"
Since the beginning of timeIsn't that actually the narration from the beginning of The Fifth Element?
A weapon was built and protected
To keep the balance in line
To guard the "forces of the light"
Do you hear the cries of all the ones that fell?
Sathanas "Reign of the Antichrist"
From the fall of grace-I shall rise againWell, it's certainly Satanic. But it's Satanism as mirror-image Christianity. Like, imagine if Jackson Pollock's avant-garde transgression was taking Vermeer paintings and repainting them with left and right reversed!!!! To be fair, that's the usual way in which revolutions collapse into politics, hating the status quo's conclusions but being unable to escape its assumptions.
Avenging chosen one-Known as Satan’s son
However, I have a lot of other metal subgenres to work with, and I can actually reorganize the world as if Black Thrash were its point of origin, and then as we move slowly away from that point, genre by genre, we can start to see the patterns change.
"Satan" begins to disappear.
"Christ" goes away.
"Damnation" no longer so much of a concern.
"Chaos" starts to appear.
"Darkness" is everywhere.
"Eternal" fascinates us.
As does "Beyond".
"Death", always death.
And over and over, at the top of almost every list that doesn't start with "Death": "Flesh".
Except groove metal, where the number 1 term is "Reissue".
So my mistake, maybe, was in assuming I was looking for a philosophy that called itself Satanic. Give up that constraint, and ideas start to coalesce after all.
Entombed "Left Hand Path"
No one will take my soul awayEnslaved "Ethica Odini"
I carry my own will and make my day
You have the key to mysteryDantalion "Onward to Darkness"
Pick up the runes; unveil and see
Existence is your own adversary,Mitochondrion "Eternal Contempt of Man"
a path full of pain and madness.
Now the earth, sea, and sky all have tornDodecahedron "I, Chronocrator"
Now a gate from the void hath been born
Both the watchers and the unholy do agree
Eradicate that vermin filth humanity
Reigning formulas undoneWe are approaching a version of Nihilism that is not an absence, but an embrace of nothingness, an embrace of the finite, of finity.
Oaths sworn into silence
Our world will be without form
Our earth will be void
Celtic Frost "Os Abysmi Vel Daath"
Where I am there is no thing.Totalselfhatred "Enlightenment"
No God, no me, no inbetween.
OK, first of all, the band is called Totalselfhatred, and they sound like this. Dreamy.
I cannot change your destiny, can only help you thinkAnd then, maybe, the grand masters of this, Deathspell Omega.
As far as my horizons lead - your thoughts will be more deep
Hope inside is torturing me - keeps painfully alive
A light inside, a knowledge deep, that shines so bright!
Deathspell Omega "Chaining the Katechon"
That's a 22-minute song, and it does not fade in.
The task to be achieved, human vocationHere, then, are some potential tenets of a chaotic black metal philosophical program:
Is to become intensely mortal
Not to shrink back
Before the voices
coming from the gallows tree
A work making increasing sense
By its lack of sense
In the history of times there is
But the truth of bones and dust.
1. Babel. Acceptance of chaos, instead of a futile struggle for order or serenity
2. The Codex. To exist in chaos is to seek complexity over simplicity
3. The Void. There is beauty in darkness
4. The Scythe. There are either no illusions, or all illusions, but either way, only death is real
Which all adds up, I think, to something that I basically understood in second grade, after all: grimly acknowledged free will. That is the philosophical core of metal, as an art form. That is the exact rebellion I was seeking. To choose Satan, and particularly to choose Satan without giving him any positive qualities, is to assert that the act of choosing is more important than the actual choice. To choose death is to assert that choosing is more important than living. To choose death symbolically is somewhat more powerful than choosing it literally, because you can choose it symbolically more than once, while gives you a chance to refine your symbolism.
Blut Aus Nord "The Choir of the Dead"
That is Blut Aus Nord's "The Choir of the Dead", from an album actually called The Work Which Transforms God. What does it say? I dunno. But what does it mean? "Hail Satan" is "Think for yourself" plus noise.
Thank you, and see you in Hell.
[The whole playlist that I was playing from is on Spotify here: Triangulations of the Abyss.]
Thanks to the Program Committee and the audience for indulging this whim, and particularly to Eric Weisbard for backing up his early-morning scheduling of this racket by showing up to moderate the session himself.
¶ Post-Neo-Traditional Pop Post-Thing · 29 September 2014 essay/listen/tech
As part of a conference on Music and Genre at McGill University in Montreal, over this past weekend, I served as the non-academic curiosity at the center of a round-table discussion about the nature of musical genres, and of the natures of efforts to understand genres, and of the natures of efforts to understand the efforts to understand genres. Plus or minus one or two levels of abstraction, I forget exactly.
My "talk" to open this conversation was not strictly scripted to begin with, and I ended up rewriting my oblique speaking notes more or less over from scratch as the day was going on, anyway. One section, which I added as I listened to other people talk about the kinds of distinctions that "genres" represent, attempted to list some of the kinds of genres I have in my deliberately multi-definitional genre map. There ended up being so many of these that I mentioned only a selection of them during the talk. So here, for extended (potential) amusement, is the whole list I had on my screen:
Kinds of Genres
(And note that this isn't even one kind of kind of genre...)
- conventional genre (jazz, reggae)
- subgenre (calypso, sega, samba, barbershop)
- region (malaysian pop, lithumania)
- language (rock en espanol, hip hop tuga, telugu, malayalam)
- historical distance (vintage swing, traditional country)
- scene (slc indie, canterbury scene, juggalo, usbm)
- faction (east coast hip hop, west coast rap)
- aesthetic (ninja, complextro, funeral doom)
- politics (riot grrrl, vegan straight edge, unblack metal)
- aspirational identity (viking metal, gangster rap, skinhead oi, twee pop)
- retrospective clarity (protopunk, classic peruvian pop, emo punk)
- jokes that stuck (crack rock steady, chamber pop, fourth world)
- influence (britpop, italo disco, japanoise)
- micro-feud (dubstep, brostep, filthstep, trapstep)
- technology (c64, harp)
- totem (digeridu, new tribe, throat singing, metal guitar)
- isolationism (faeroese pop, lds, wrock)
- editorial precedent (c86, zolo, illbient)
- utility (meditation, chill-out, workout, belly dance)
- cultural (christmas, children's music, judaica)
- occasional (discofox, qawaali, disco polo)
- implicit politics (chalga, nsbm, dangdut)
- commerce (coverchill, guidance)
- assumed listening perspective (beatdown, worship, comic)
- private community (orgcore, ectofolk)
- dominant features (hip hop, metal, reggaeton)
- period (early music, ska revival)
- perspective of provenance (classical (composers), orchestral (performers))
- emergent self-identity (skweee, progressive rock)
- external label (moombahton, laboratorio, fallen angel)
- gender (boy band, girl group)
- distribution (viral pop, idol, commons, anime score, show tunes)
- cultural institution (tin pan alley, brill building pop, nashville sound)
- mechanism (mashup, hauntology, vaporwave)
- radio format (album rock, quiet storm, hurban)
- multiple dimensions (german ccm, hindustani classical)
- marketing (world music, lounge, modern classical, new age)
- performer demographics (military band, british brass band)
- arrangement (jazz trio, jug band, wind ensemble)
- competing terminology (hip hop, rap; mpb, brazilian pop music)
- intentions (tribute, fake)
- introspective fractality (riddim, deep house, chaotic black metal)
- opposition (alternative rock, r-neg-b, progressive bluegrass)
- otherness (noise, oratory, lowercase, abstract, outsider)
- parallel terminology (gothic symphonic metal, gothic americana, gothic post-punk; garage rock, uk garage)
- non-self-explanatory (fingerstyle, footwork, futurepop, jungle)
- invented distinctions (shimmer pop, shiver pop; soul flow, flick hop)
- nostalgia (new wave, no wave, new jack swing, avant-garde, adult standards)
- defense (relaxative, neo mellow)
That was at the beginning of the talk. At the end I had a different attempt at an amusement prepared, which was a short outline of my mental draft of the paper I would write about genre evolution, if I wrote papers. In a way this is also a way of listing kinds of kinds of things:
The Every-Noise-at-Once Unified Theory of Musical Genre Evolution
And it would be awesome.
[Also, although I was the one glaringly anomalous non-academic at this academic conference, let posterity record the cover of the conference program.]

My "talk" to open this conversation was not strictly scripted to begin with, and I ended up rewriting my oblique speaking notes more or less over from scratch as the day was going on, anyway. One section, which I added as I listened to other people talk about the kinds of distinctions that "genres" represent, attempted to list some of the kinds of genres I have in my deliberately multi-definitional genre map. There ended up being so many of these that I mentioned only a selection of them during the talk. So here, for extended (potential) amusement, is the whole list I had on my screen:
Kinds of Genres
(And note that this isn't even one kind of kind of genre...)
- conventional genre (jazz, reggae)
- subgenre (calypso, sega, samba, barbershop)
- region (malaysian pop, lithumania)
- language (rock en espanol, hip hop tuga, telugu, malayalam)
- historical distance (vintage swing, traditional country)
- scene (slc indie, canterbury scene, juggalo, usbm)
- faction (east coast hip hop, west coast rap)
- aesthetic (ninja, complextro, funeral doom)
- politics (riot grrrl, vegan straight edge, unblack metal)
- aspirational identity (viking metal, gangster rap, skinhead oi, twee pop)
- retrospective clarity (protopunk, classic peruvian pop, emo punk)
- jokes that stuck (crack rock steady, chamber pop, fourth world)
- influence (britpop, italo disco, japanoise)
- micro-feud (dubstep, brostep, filthstep, trapstep)
- technology (c64, harp)
- totem (digeridu, new tribe, throat singing, metal guitar)
- isolationism (faeroese pop, lds, wrock)
- editorial precedent (c86, zolo, illbient)
- utility (meditation, chill-out, workout, belly dance)
- cultural (christmas, children's music, judaica)
- occasional (discofox, qawaali, disco polo)
- implicit politics (chalga, nsbm, dangdut)
- commerce (coverchill, guidance)
- assumed listening perspective (beatdown, worship, comic)
- private community (orgcore, ectofolk)
- dominant features (hip hop, metal, reggaeton)
- period (early music, ska revival)
- perspective of provenance (classical (composers), orchestral (performers))
- emergent self-identity (skweee, progressive rock)
- external label (moombahton, laboratorio, fallen angel)
- gender (boy band, girl group)
- distribution (viral pop, idol, commons, anime score, show tunes)
- cultural institution (tin pan alley, brill building pop, nashville sound)
- mechanism (mashup, hauntology, vaporwave)
- radio format (album rock, quiet storm, hurban)
- multiple dimensions (german ccm, hindustani classical)
- marketing (world music, lounge, modern classical, new age)
- performer demographics (military band, british brass band)
- arrangement (jazz trio, jug band, wind ensemble)
- competing terminology (hip hop, rap; mpb, brazilian pop music)
- intentions (tribute, fake)
- introspective fractality (riddim, deep house, chaotic black metal)
- opposition (alternative rock, r-neg-b, progressive bluegrass)
- otherness (noise, oratory, lowercase, abstract, outsider)
- parallel terminology (gothic symphonic metal, gothic americana, gothic post-punk; garage rock, uk garage)
- non-self-explanatory (fingerstyle, footwork, futurepop, jungle)
- invented distinctions (shimmer pop, shiver pop; soul flow, flick hop)
- nostalgia (new wave, no wave, new jack swing, avant-garde, adult standards)
- defense (relaxative, neo mellow)
That was at the beginning of the talk. At the end I had a different attempt at an amusement prepared, which was a short outline of my mental draft of the paper I would write about genre evolution, if I wrote papers. In a way this is also a way of listing kinds of kinds of things:
The Every-Noise-at-Once Unified Theory of Musical Genre Evolution
- There is a status quo;
- Somebody becomes dissatisfied with it;
- Several somebodies find common ground in their various dissatisfactions;
- Somebody gives this common ground a name, and now we have Thing;
- The people who made thing before it was called Thing are now joined by people who know Thing as it is named, and have thus set out to make Thing deliberately, and now we have Thing and Modern Thing, or else Classic Thing and Thing, depending on whether it happened before or after we graduated from college;
- Eventually there's enough gravity around Thing for people to start trying to make Thing that doesn't get sucked into the rest of Thing, and thus we get Alternative Thing, which is the non-Thing thing that some people know about, and Deep Thing, which is the non-Thing thing that only the people who make Deep Thing know;
- By now we can retroactively identify Proto-Thing, which is the stuff before Thing that sounds kind of thingy to us now that we know Thing;
- Thing eventually gets reintegrated into the mainstream, and we get Pop Thing;
- Pop Thing tarnishes the whole affair for some people, who head off grumpily into Post Thing;
- But Post Thing is kind of dreary, and some people set out to restore the original sense of whatever it was, and we get Neo-Thing;
- Except Neo-Thing isn't quite the same as the original Thing, so we get Neo-Traditional Thing, for people who wish none of this ever happened except the original Thing;
- But Neo-Thing and Neo-Traditional Thing are both kind of precious, and some people who like Thing still also want to be rock stars, and so we get Nu Thing;
- And this is all kind of fractal, so you could search-and-replace Thing with Post Thing or Pop Thing or whatever, and after a couple iterations you can quickly end up with Post-Neo-Traditional Pop Post-Thing.
And it would be awesome.
[Also, although I was the one glaringly anomalous non-academic at this academic conference, let posterity record the cover of the conference program.]